chap11 - Machine Learning
-
머신러닝 이해하기
-
OpenCV 머신 러닝 클래스
-
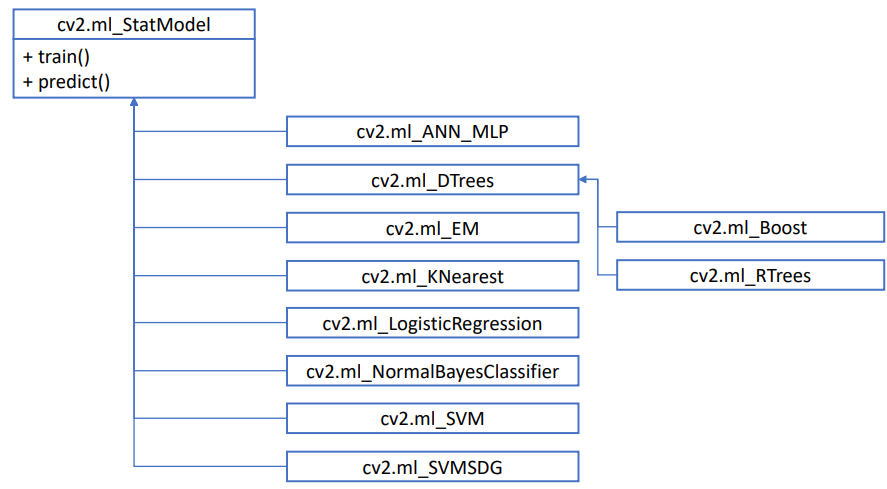
- 위의 어떤 방법으로 머신러닝 알고리즘 객체를 생성한 후, train(), predict() 함수를 사용하면 된다.
- cv2.ml_StatModel.train(samples, layout, responses)
- cv2.ml_StatModel.predict(samples, results=None, flags=None)
- 예제코드를 통해서 공부할 예정이고, 이번 수업에서는 아래를 공부할 예정
- KNearest : K 최근접 이웃 알고리즘은 샘플 데이터와 인접한 K개의 학습 데이터를 찾고, 이 중 가장 많은 개수에 해당하는 클래스를 샘플 데이터 클래스로 지정
- SVM : 두 클래스의 데이터를 가장 여유 있게 분리하는 초평면을 구함
-
-
k최근접 이웃 알고리즘
-
KNearest 이론
-
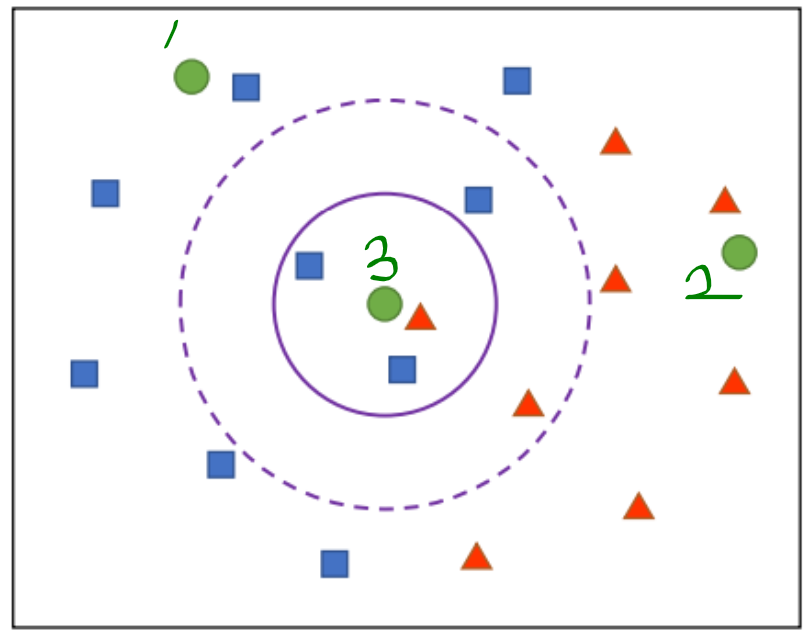
- 원래 파란, 빨간 백터만 있는 공간에, 초록색이 들어왔다고 가정하다.
- 1번은 파랑 클래스, 2번은 빨강 클래스라고 정하면 될 것 같다.
- 3번은 뭘까?? 이것을 결정하기 위해, 초록색에 대해서 가까운 k개의 백터를 찾는다. 그리고 가장 많이 뽑힌 클래스를 3번의 클래스라고 정하는 방법이다.
-
-
KNearest 코드
-
cv2.ml.KNearest_create() -> retval
-
# Knnplane.py 아래의 순서대로 OpenCV 사용 # 이거 사용할거다. 라는 의미의 객체 생성 knn = cv2.ml.KNearest_create() # 백터 저장 knn.train(trainData, cv2.ml.ROW_SAMPLE, labelData) # Inference ret, _, _, _ = knn.findNearest(sample, k_value) -
Knnplane.py 코드는 tuple(x,y,label) 의 다수 포인트를 이용해서, 2차원 평면상의 임의 포인트는 (3개의 클래스 중) 어떤 클래스를 가지는지 결정하여 색칠하는 코드이다. 어렵지 않으니 필요하면 참고
-
-
-
KNN 필기체 숫자 인식 (KNearest 사용)
-
cv2.matchTemplate(chap8-segmentation-detection) 를 사용해서 필기체 인식을 했었다. 하지만 그 방법은 똑같은 폰트를 사용한 숫자여야하고 레이블링 후 숫자 부분영상의 정규화도 해야한다. (이전 post 참고)
-

-
# 학습 데이터 & 레이블 행렬 생성 digits = cv2.imread('digits.png?raw=tru', cv2.IMREAD_GRAYSCALE) h, w = digits.shape[:2] # 배열 분할 하기 h_split,v_split = https://rfriend.tistory.com/359 cells = [np.hsplit(row, w//20) for row in np.vsplit(digits, h//20)] cells = np.array(cells) # cells: shape=(50, 100, 20, 20), dtype: uint8 # 위 사진과 같이 배열 및 클래스 저장 train_images = cells.reshape(-1, 400).astype(np.float32) train_labels = np.repeat(np.arange(10), len(train_images)/10) # train_images: shape=(5000, 400), dtype=**float32**, train_labels: shape=(5000, ), dtype=**int32** # KNN 학습 knn = cv2.ml.KNearest_create() knn.train(train_images, cv2.ml.ROW_SAMPLE, train_labels) # Inference ret, _, _, _ = knn.findNearest(test_image, 5)
-
-
SVM 알고리즘 (아주 간략히만 설명한다. 자세한 수학적 설명은 직접 찾아공부)
- SVM : 기본적으로 두 개의 그룹(데이터)을 분리하는 방법으로 데이터들과 거리가 가장 먼 초평면(hyperplane)을 선택하여 분리하는 방법 (maximum margin classifier)
- 아래의 1번과 2번 라인이 아닌, 3번의 라인처럼, 직선/평면과 가장 거리가 최소한 서포트 백터와의 거리가 최대maximum가 되도록 만드는 직선/평면(n차원 백터에 대해서 n-1차원 평면)을 찾는다.
-

-
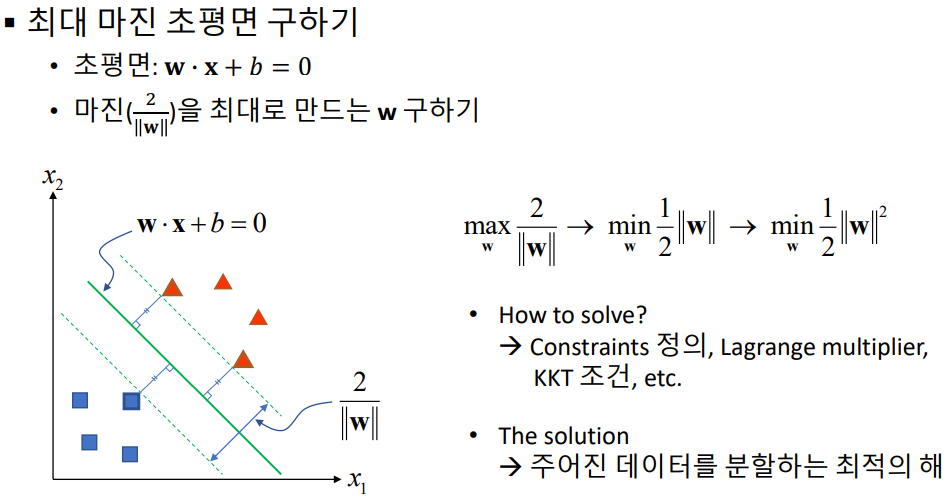
- 수학적 수식은 위와 같다. 자세한 내용은 생략한다. 여기서 w와 x는 백터이다. w*x + b = 0 이 n차원 백터에 대해서 n-1차원 평면식이 되겠다. 자세한 수학적 설명은 강의에서도 가르쳐주지 않으니 직접 찾아서 공부할 것.
- 위의 백터들은 완벽하게 분류가 되어 있는데, 오차가 있는 경우의 SVM을 찾는 방법은 다른 알고리즘을 사용한다. 그 알고리즘은 Soft margin, C-SVM 이라고 부른다.
- 하지만 SVM은 선형 분류 알고리즘이다. 백터들을 분류하기 위해 직선(선형식)으로는 분류가 안된다면 SVM을 사용할 수 없다. 물론 차원을 확장하면 선형으로 분리 가능 할 수 있다. 아래의 예제로만 알아두고 정확하게는 나중에 정말 필요하면 그때 찾아서 공부하기.
-

- 여기서는 z에 관한 방적식으로 차원을 확장했는데, 일반적으로 z는 조금 복잡하다. kernel trick이라는 방법을 통해서 차원 확장을 이루는데, 이것도 필요함 그때 공부.
-
OpenCV SVM 사용하기
-
객체 생성 : cv2.ml.SVM_create() -> retval
-
SVM 타입 지정 : cv.ml_SVM.setType(type) -> None
-
SVM 커널 지정 : cv.ml_SVM.setKernel(kernelType) -> None
-
SVM 자동 학습(k-폴드 교차 검증) : cv.ml_SVM.trainAuto(samples, layout, respo) -> retval
-
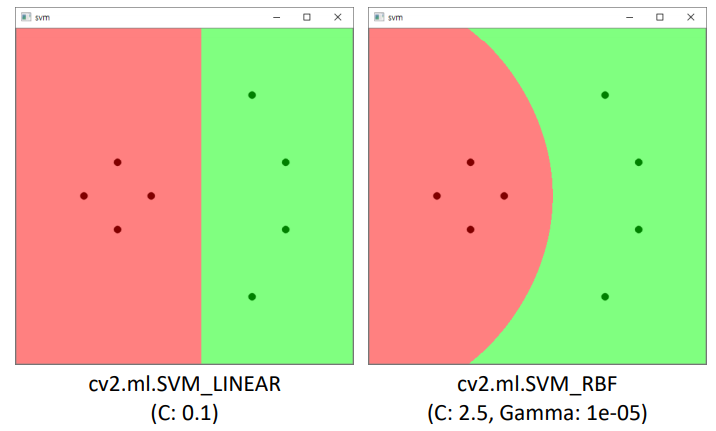
# svmplane.py # trains and labels 임으로 만들어 주기 trains = np.array([[150, 200], [200, 250], [100, 250], [150, 300], [350, 100], [400, 200], [400, 300], [350, 400]], dtype=np.float32) labels = np.array([0, 0, 0, 0, 1, 1, 1, 1]) # set SVM svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_LINEAR) # 직선, 평명 찾기 #svm.setKernel(cv2.ml.SVM_RBF) # 곡선, 곡면 찾기 svm.trainAuto(trains, cv2.ml.ROW_SAMPLE, labels) print('C:', svm.getC()) # 초평면 계산 결과1 print('Gamma:', svm.getGamma()) # 초평면 계산 결과2 w, h = 500, 500 img = np.zeros((h, w, 3), dtype=np.uint8) for y in range(h): for x in range(w): test = np.array([[x, y]], dtype=np.float32) _, res = svm.predict(test) # predict ret = int(res[0, 0]) if ret == 0: img[y, x] = (128, 128, 255) else: img[y, x] = (128, 255, 128) color = [(0, 0, 128), (0, 128, 0)] for i in range(trains.shape[0]): x = int(trains[i, 0]) y = int(trains[i, 1]) l = labels[i] cv2.circle(img, (x, y), 5, color[l], -1, cv2.LINE_AA) -
-
-
HOG(descriptor = 특징값 vector로 추출)를 이용한, SVM 기반 필기체 숫자 인식
-
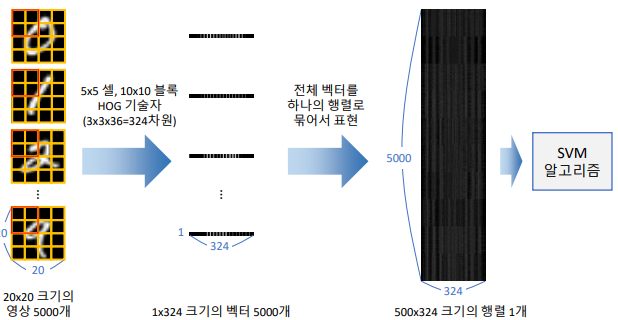
-
이전에는 hog.setSVMDetector를 사용했지만, hog.compute(img) 를 사용한다.
-
# svmdigits.py 자세한 내용은 코드를 참고하기 (필요하면..) hog = cv2.HOGDescriptor((20, 20), (10, 10), (5, 5), (5, 5), 9) desc = [] for img in cells: desc.append(hog.compute(img)) train_desc = np.array(desc).squeeze().astype(np.float32) train_labels = np.repeat(np.arange(10), len(train_desc)/10) # SVM 학습 svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_RBF) svm.setC(2.5) svm.setGamma(0.50625) svm.train(train_desc, cv2.ml.ROW_SAMPLE, train_labels) # inference test_image = cv2.resize(img, (20, 20), interpolation=cv2.INTER_AREA) test_desc = hog.compute(test_image) _, res = svm.predict(test_desc.T) print(int(res[0, 0]))
-
-
숫자 영상 정규화
-
숫자 이미지는 숫자의 위치, 회전,크기 등등에 따라서 다양한 모습을 갖추기 때문에, 숫자 위치를 정규화할 필요가 있음
-
숫자 영상의 무게 중심이 전체 영상 중앙이 되도록 위치 정규화
-
무게 중심을 찾아주는 함수 사용 m = cv2.moments(img)
-
def norm_digit(img): # cv2.moments의 사용법은 아래와 같다 m = cv2.moments(img) cx = m['m10'] / m['m00'] cy = m['m01'] / m['m00'] h, w = img.shape[:2] aff = np.array([[1, 0, w/2 - cx], [0, 1, h/2 - cy]], dtype=np.float32) dst = cv2.warpAffine(img, aff, (0, 0)) return dst desc = [] for img in cells: img = norm_digit(img) desc.append(hog.compute(img)) # 나머지는 윗 코드와 같다
-
-
- 주어진 데이터가지고, 이미지를 k개의 구역으로 나누는 군집화 알고리즘 (비지도 학습으로 고려)
-

- 동작순서
- 임의의 (최대한 서로 멀리) K개 중심을 선정 (분할 평면도 대충 적용. Ex) 두 임의의 점의 중점을 지나는 수직 선)
- 모든 데이터에 대해서 가장 가까운 중심을 선택 (추적 때 배운 평균 이동 알고리즘과 비슷)
- 각 군집에 대해 중심을 다시 계산
- 중심이 변경되면 2번과 3번 과정을 반복
- 중심 변경이 적어지면 종료
- 컬러 영상 분할
- 컬러영상에서 대표가 되는 칼라 픽셀 값을 선택하는 알고리즘. 원본 이미지에서 위의 k-mean 알고리즘을 수행하는게 아니라, RGB&HS 공간에서 위의 알고리즘을 수행해 '대표필셀값’을 찾는다
-
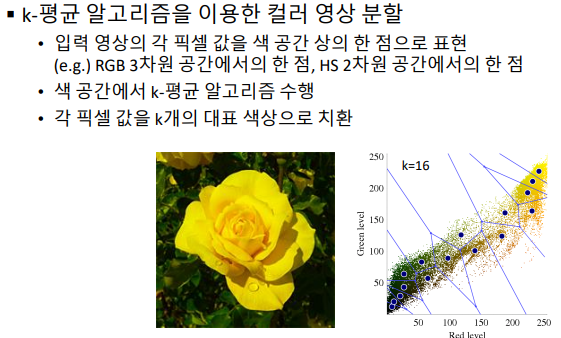
- cv2.kmeans(data, K, bestLabels, criteria, attempts) -> retval, bestLabels, centers (자세한 파라메터 설정은 강의나 공식 문서 참고)
- k-means 알고리즘을 이용한 컬러 영상 분할 예제 실행 결과 - kmeans.py 파일 참고 (코드는 매우 간단)
-

-
실전 코딩: 문서 필기체 숫자 인식
-

- 앞에서 배운것 만을 잘 활용한다.
- 순서 요약
- 레이블링 이용 → 각 숫자의 바운딩 박스 정보 추출
- 숫자 부분 영상을 정규화
- HOGDescriptor 로 descriptor 추출
- 이미 학습된 SVM으로 predict 수행
-
chap - 12, 13 딥러닝
- cv2.dnn 모듈을 사용해서 합습 및 추론
- 필요하면 그때 공부하자.