[Detection] TridentNet - Scale-Aware Trident Networks for Object Detection
- 논문 : Scale-Aware Trident Networks for Object Detection
- 분류 : Scale-Aware Object Detection
- 저자 : Yanghao Li, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang
- PS
- COCO에서 Small, Medium, Large의 기준이 무엇인가? 참고 Page, (핵심 복붙 : In COCO, there are more small objects than large objects. Specifically: approximately 41% of objects are small (area < 322), 34% are medium (322 < area < 962), and 24% are large (area > 962). Area is measured as the number of pixels in the segmentation mask.)
- 전체적으로 약 파는 논문 같다. 비교도 자기의 모델(ablation) 비교가 대부분으고. 최근 기법들이랑 비교도 안하고…
- 파라메터 share하는 거 말고는, 앙상블이랑 뭐가 다른지. 모르겠고 왜 이게 논문이고 citation이 250이나 되는지 모르겠다. 속도보단 성능. 실용성보단 연구. 라는 느낌이 강해서 내맘에 들지 않는 논문이다.
- 목차
- TridentNet Paper Review
- Code
TridentNet
1. Conclusion, Abstract, Introduction
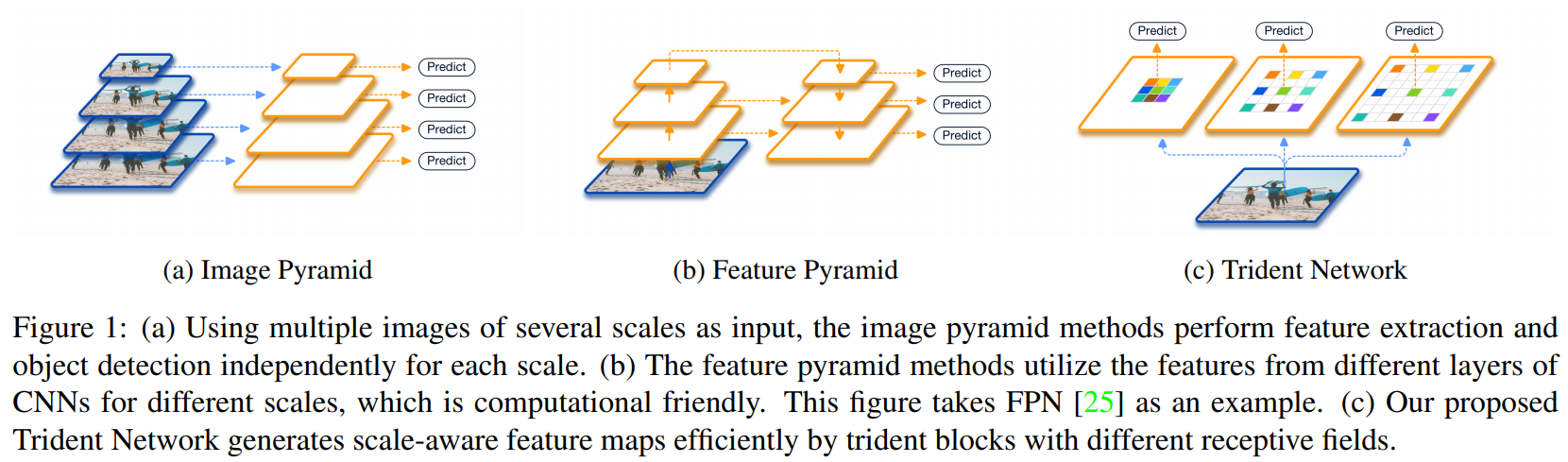
- 아래와 같은 Network를 설계하여, trident blocks 들이 다른 receptive field를 가지게 함으로써, scale-aware feature maps 을 생성한다.
- our contributions 정리
- effect of the receptive field 에 대해서 조사해보았다.
scale-specific feature maps을 생성하는 TridentNet를 소개한다.scale-aware training scheme 를 사용해서 각각의 branch가 적절한 크기의 객체를 추출하는데 특화되도록 만든다.- TridentNet Fast 를 소개한다.
a parallel multi-branch architecture : 각 branch 들이 자신들의 transformation parameter를 공유하지만(trident-block 들이 서로의 weight를 sharing), 서로 다른 receptive fields를 가지도록 한다.- mAP of 48.4 using a single model with ResNet-101 backbone
3. Investigation of Receptive Field
- Architecture의 디자인 요소 중, Receptive feild에 대한 영향력 조사에 대한 논문은 없었다. 따라서 우리가 다른 Dilation rate를 사용함으로써 receptive field 에 대한 영향력을 조사해보았다.
- dilation rate (d_s) 를 사용하면, network의 receptive field를 증가시키는 장점을 얻을 수 있다.
- 아래와 같이 실험을 했고, 오른쪽 표가 실험의 결과이다.
- 이를 통해서, receptive field가 객체 크기에 따른 검출 성능에 영향을 준다는 것을 파악했다.
- 특히! 큰 객체에 대해서 더 검출을 잘하는 것을 파악할 수 있다. (이 논문 전체를 보면 small object의 성능 검출 보다는 보통 large object에 따른 성능 증가가 많은 편이었다.)
- ResNet101을 사용했을 때 조차도, receptive field를 넓혀줬을 때, 성능이 향상되었다. 이론적인 receptive field 보다, [practical하고 실험적이고 effective한] receptive field는 더 작다는 것을 증명하는 사례이다.
4. Trident Network
4.1. Network Structure
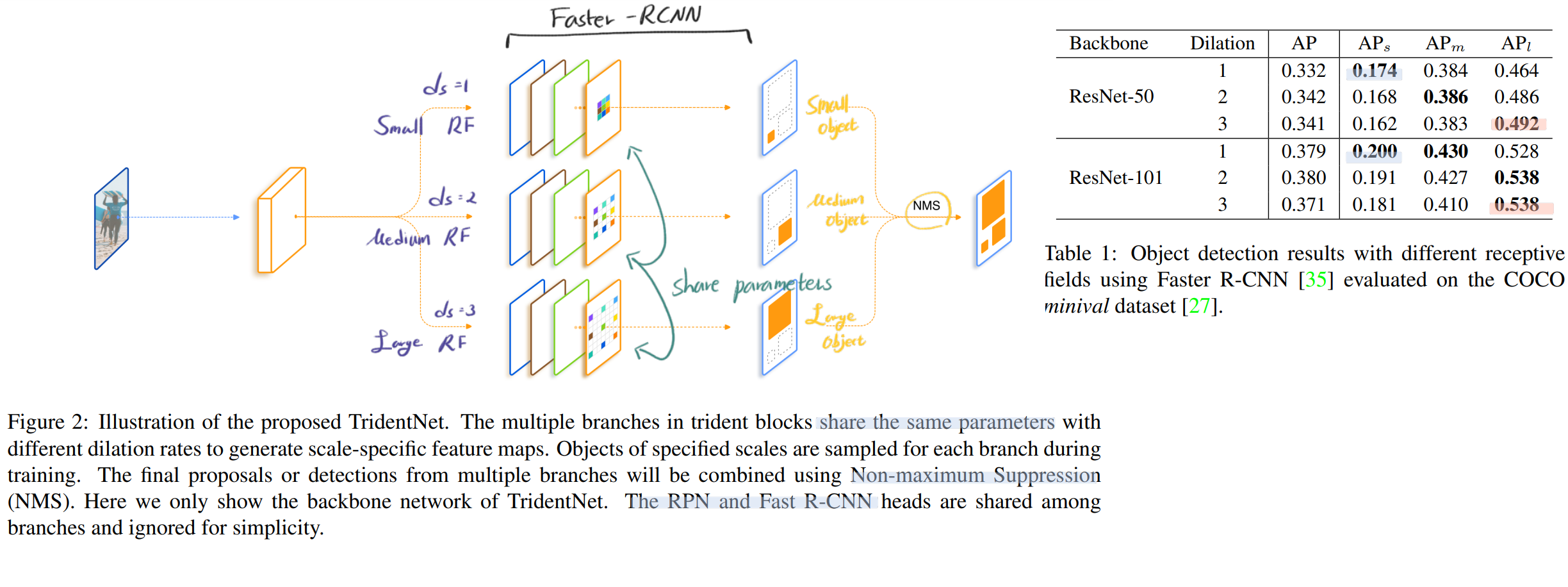
- Multi-branch Block
- single scale input이 들어가고, 평행하게 각 branch가 scale-specific feature map을 만들어 낸다.
- TridentNets은 임이의 Network의 Conv연산을 trident blocks으로 바꿔서 만들어 낸다.
- (실제 이 논문의 목표는 어떤 전체 Architecture를 만든게 아니다. Faster-RCNN 그리고 RPN 혹은 ResNet backbone의 특정부분의 Conv연산을 trident block으로 대체하여 사용한게 전부이다. 어떻게 어느 부분을 바꾸었는지는 구체적으로 나와있지 않다.)
- Typically, we replace the blocks in the last stage of the backbone network with trident blocks / since larger strides lead to a larger difference in receptive fields as needed. 즉, ResNet 중에서도 Deep한 부분부터 trident block을 삽입해 사용했다고 한다. 뒤의 실험에서도 나오겠지만, Deep 한 곳에 적용해야 효과가 좋다. 왜냐하면, Deep한 곳의 각각의 Featrue Pixel들은 이미 큰 Receptive field를 가지는데, 거기다가 Trident Block을 적용해서 더! 큰 Receptive Field를 가지게 만드는 것이다.
- (이것을 코드로 구현하는 것은 어렵지 않을 것 같다. 일단 Faster-RCNN코드를 하나 가져온다. 그리고 그 코드에 있는 일부 nn.conv2d 에 Dilation rate를 추가해준다. 그럼 그게 하나의 branch이다. 그렇게 각각의 net=build_module()을 3개 만든다. net1, net2, net3. 그리고 이것들을 가지고 NMS해주면 끝. (NMS가 그냥 앙상블 수준이다.))
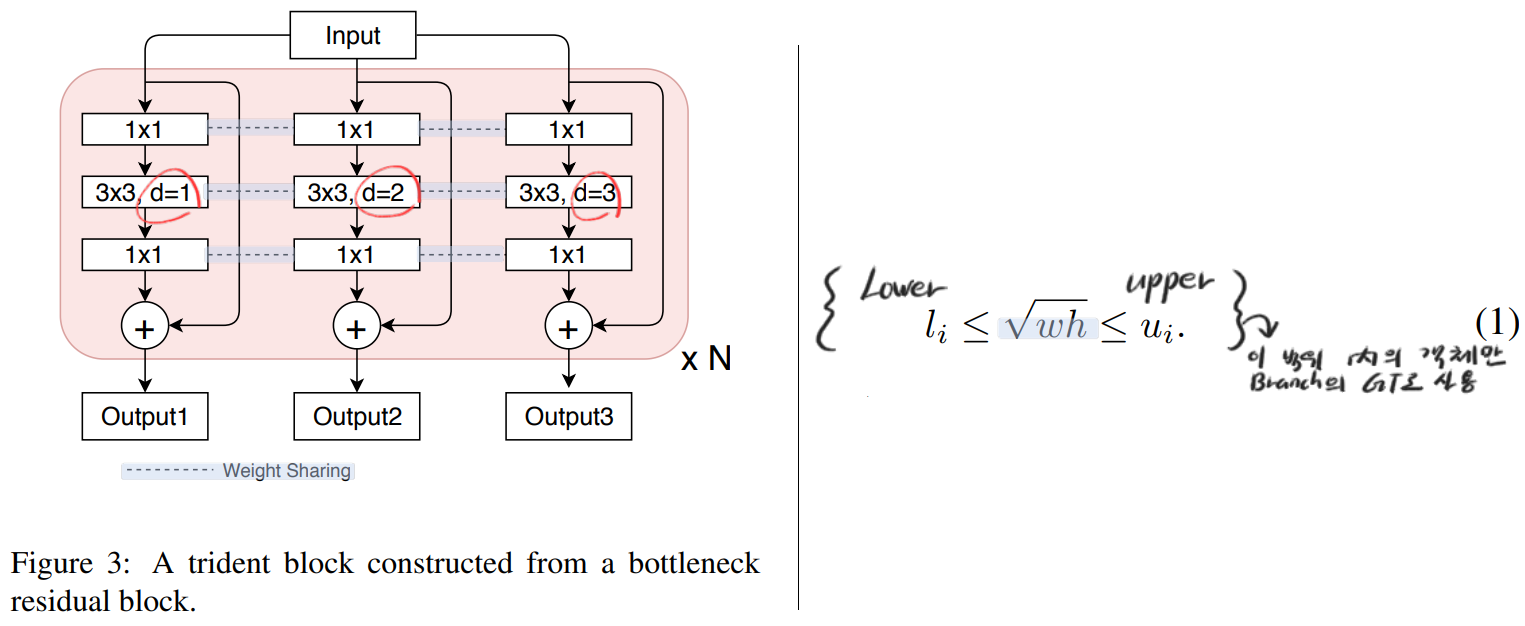
- Weight sharing among branches
- 모든 Branch는 RPN and R-CNN heads의 일부 conv를 Trident Block으로 대체하여 사용한다… 그리고 (서로 dilation rate만 다른) 각각의 Branch에 대해서, the same parameters를 공유한다.
- 그렇기 때문에 추가적인 파라미터가 필요하지 않다. (물론 연산은 3배로 해야하는 것은 맞다.)
- 학습 중에서도 파라메터가 공유되어 학습된다.
- Scale-aware Training Scheme
- 위의 표를 보면 Small object에 대해서는 Large Receptive Field를 가지는 branch에서는 오히려 낮은 성능이 나오는 것을 확인할 수 있다.
- 이것을 objects of different scales, on different branches 즉 mismatched branches 라고 표현할 수 있다.
- 따라서 이러한 문제를 피하고자, 각각의 branch가 the scale awareness를 가지게 하도록 하는 a scale-aware training scheme을 수행했다.
- 어려운게 아니라, 각 Branch마다 담당하는 객체의 크기가 다르다. 위의 (1) 식과 같이 l_i와 u_i를 설정한다. 그리고 ROI 즉 이미지의 위에서 객체의 크기를 w, h 라고 했을 때, 일정 범위의 객체일 때만, 각 Branch가 Predict 해야하는 GT로 사용하도록 만든다.
- Inference and Approximation
- 각각의 Branch에서 Detect 결과를 받아서 NMS 혹은 NMS를 사용해서 최종 결과로써 반환한다.
- Fast Inference Approximation
- 연산을 3배로 해야하기 떄문에 속도가 매우 느리다. 그래서 inference하는 동안 좀더 좋은 속도를 얻고 싶다면, 중간 branch 만을 사용한다. (dilation rate = 2 )
- (아니 특별한 것도 아니고 겨우 이게 Fast inference 기법이란다. 무슨 약 파는 것도 아니고 어이가 없는 논문이다.)
- 확실히 performance drop 이 발생하지만, weight-sharing strategy을 사용하기 때문에 중간 성능에서는 좋은 성능을 보인다. (Figure2 확인)
5. Experiments
- Table4 는 ResNet에서 trident blocks을 어디다 놓을지 정하는 실험이다. conv2,3,4가 의미하는 곳이 어딘지 모르겠으나, (논문에 안 나와 있음. ResNet논문 혹은 코드를 봐야함) conv4에서 사용하는게 좋다고 한다. 위에서 말했듯이 더 deep한 곳에서 사용해야 더 확실하게 receptive field를 크게 하는것에 도움을 받는다고 한다.