[Pa-Segmen] Axial-DeepLab - Stand-Alone Axial-Attention
Axial-DeepLab
1. Conclusion, Abstract
position-sensitive + axial attention, without cost이 Classification과 Segmentation에서 얼마나 효율적인지를 보여주었다.- Convolution은
global long range context를 놓치는 대신에 locality attention을 효율적으로 처리해왔다. 그래서 최근 work들은, local attention을 제한하고, fully attention, global relativity 을 추가하는 self-attention layer 사용해왔다.
- 우리는
fully, stand-alone + axial attention은 2D self-attention을 1D self-attention x 2개로 분해하여 만들어 진 self-attention 모듈이다. 이로써 large & global receptive field를 획득하고, complexity를 낮추고, 높은 성능을 획득할 수 있었다.
- introduction, Related Work는 일단 패스
3. Method
- Key Order :
stand-alone Axial-ResNetposition-sensitive self-attentionaxial-attentionAxial-DeepLab
3.1 Self-attention mechanism
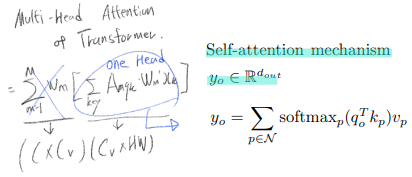
- 여기서 N은 모든 이미지 픽셀(HxW)
- 장점 :
non-local context 를 보는것이 아니라, related context in the whole feature map 을 바라본다. conv가 local relations만을 capture하는 것과는 반대이다.
- 단점
- (단점 1) extremely expensive to compute O(h2*w2 = hw(query) x hw(key))
- (단점 2) (position embeding이 충분하지 않다) positional information를 사용하지 못한다. vision task에서 spatial structure(이게 이미지의 어느 위치 인지)를 capture하고 positional imformation 을 사용하는 것이 매우 중요하다.
3.2 stand-alone(독립형) self attention
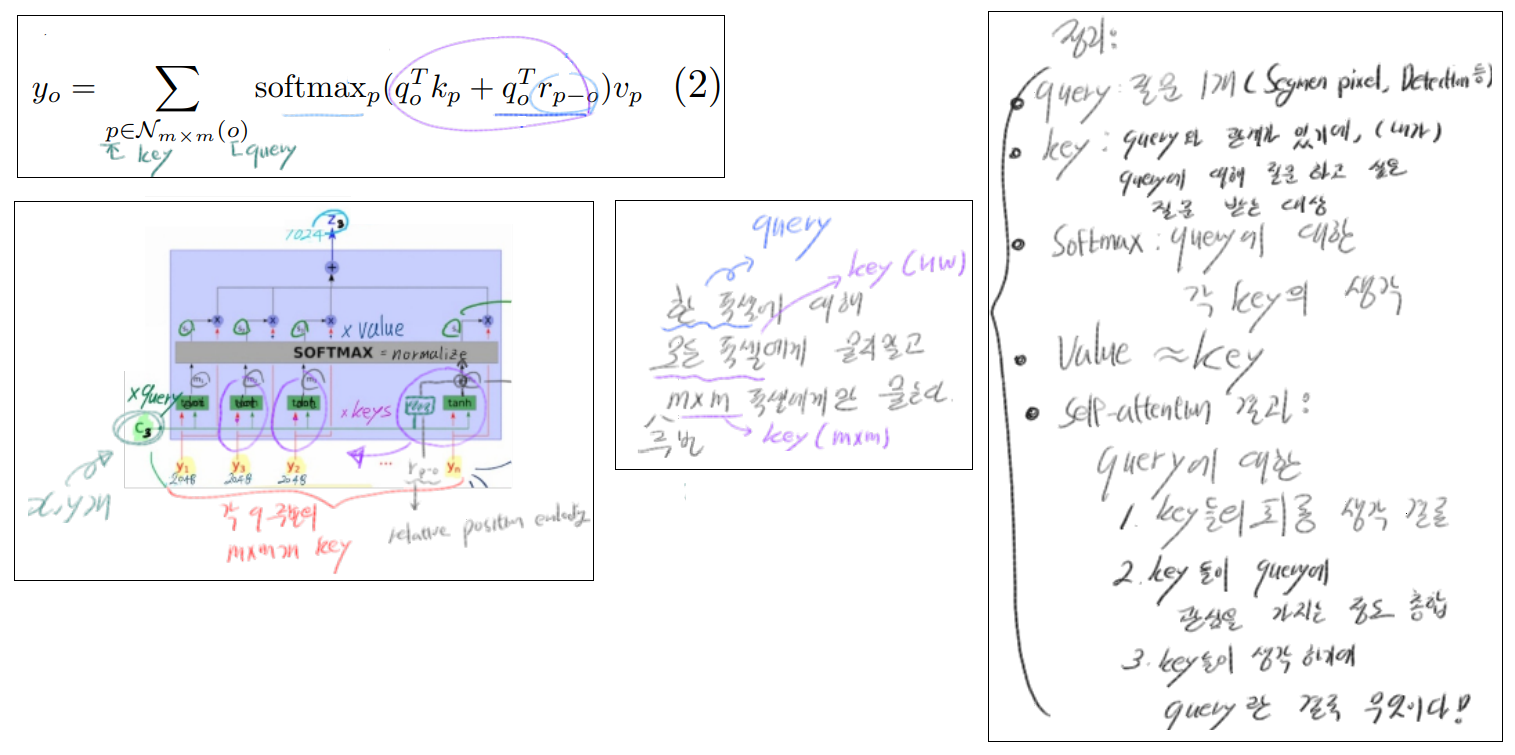
- 위의 문제점을 해결하기 위해, 개발되었다. 모든 Feature map pixel을 key로 가져가지말고, query 주변의 MxM개만을 key로 사용한다. 이로써. computation 복잡도를 O(hw(query갯수) x m^2(key갯수) ) 까지 줄일 수 있다.
- 추가적으로,
relative positional encoding을 주었다. 즉 query에 positional 정보를 주는 term을 추가한 것이다. 각 pixel(query)들은 주변 MxM공간을 receptive field로써 확장된 정보를 가지게 되고, 이 덕분에 softmax이후에 dynamic prior를 생산해낼 수 있다.
- qr 항이 추가되어, key§ location에서 query(o) location까지의 양립성(compatibility)에 대한 정보가 추가되었다. 특히 r인 positional encodings는 heads끼리 각 r에 해당하는 parameter를 공유해서 사용하기 때문에, cost 증가가 그렇게 크지는 않다고 한다.
- 위의 계산 식은 one-head-attention이다. multi-head attention 를 사용해서 혼합된 affinities (query에 대한 key들과의 애매하고 복잡한 관계로, 인해 발생하는, 다양한 선호도)를 capture할 수 있다.
- 지금까지 transformer 모델들은 one-head에서 나온 결과를 y_o1이라고 하고, y_o 1~y_o 8 까지 8개의 head로 인해 나오는 결과를 sum했는데, 여기서는 concat을 한다. 따라서 이런 식이 완성된다. z_o = concatn(y_o n).
3.3 Position-Sensitivity self attention
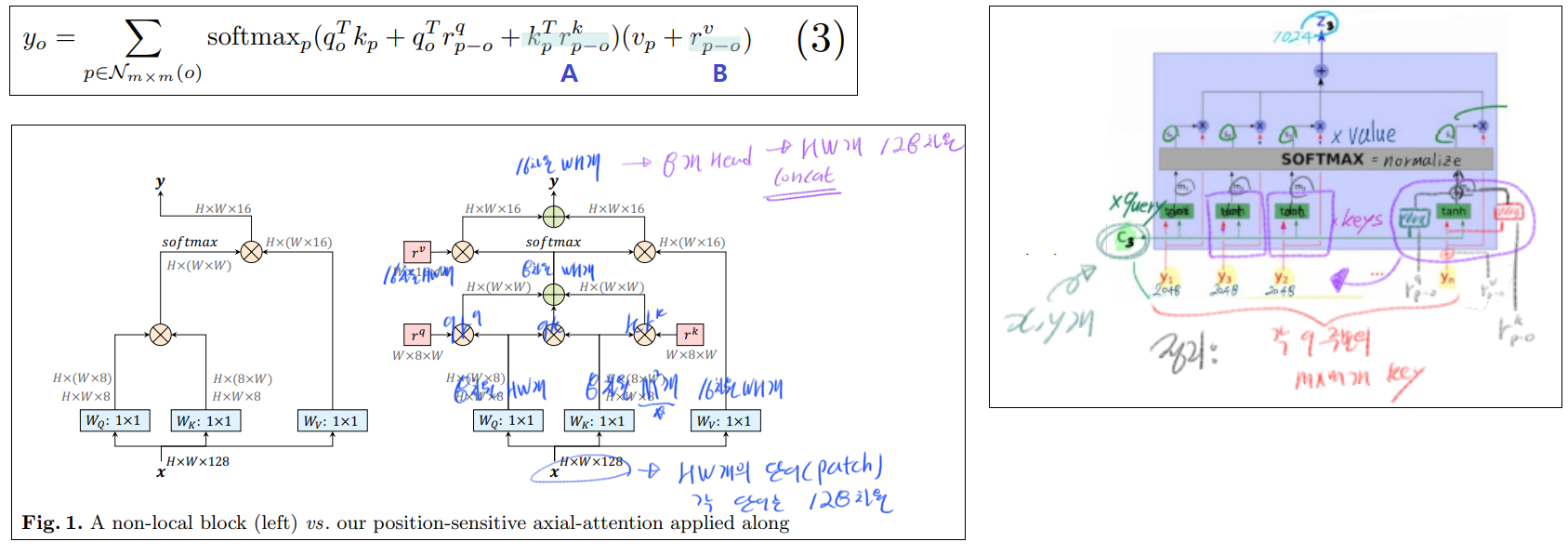
- (파랑 A) 위에서 query에게만
positional embeding을 해주었다. 여기서 저자는 ‘그렇다면 key에게도 해줘야하는거 아닌가?’ 라는 생각을 했다고 한다. 따라서 key에게도 previous positional bias를 주기 위해 key-dependent positional bias term을 추가해줬다.
- (파랑 B) y_o 또한 precise location정보를 가지면 좋겠다. 특히나 stand-alone을 사용하면 MxM (HW보다는 상대적으로) 작은 receptive fields를 사용하게 된다. 그렇기에 더더욱 value또한 (내생각. 이 MxM이 전체 이미지에서 어디인지를 알려줄 수 있는) precise spatial structures를 제공해줘야한다. 이것이
retrieve relative positions = r 이라고 할 수 있다.
- 위의 A와 B의 positional embeding 또한 across heads 사이에 parameter를 share하기 때문에 큰 cost 증가는 없다.
- 이렇게 해서 1.
captures long range interactions 2. with precise positional information 3. reasonable computation overhead를 모두 가진 position-sensitive self-attention를 만들어 내었다.
3.4 Axial-Attention
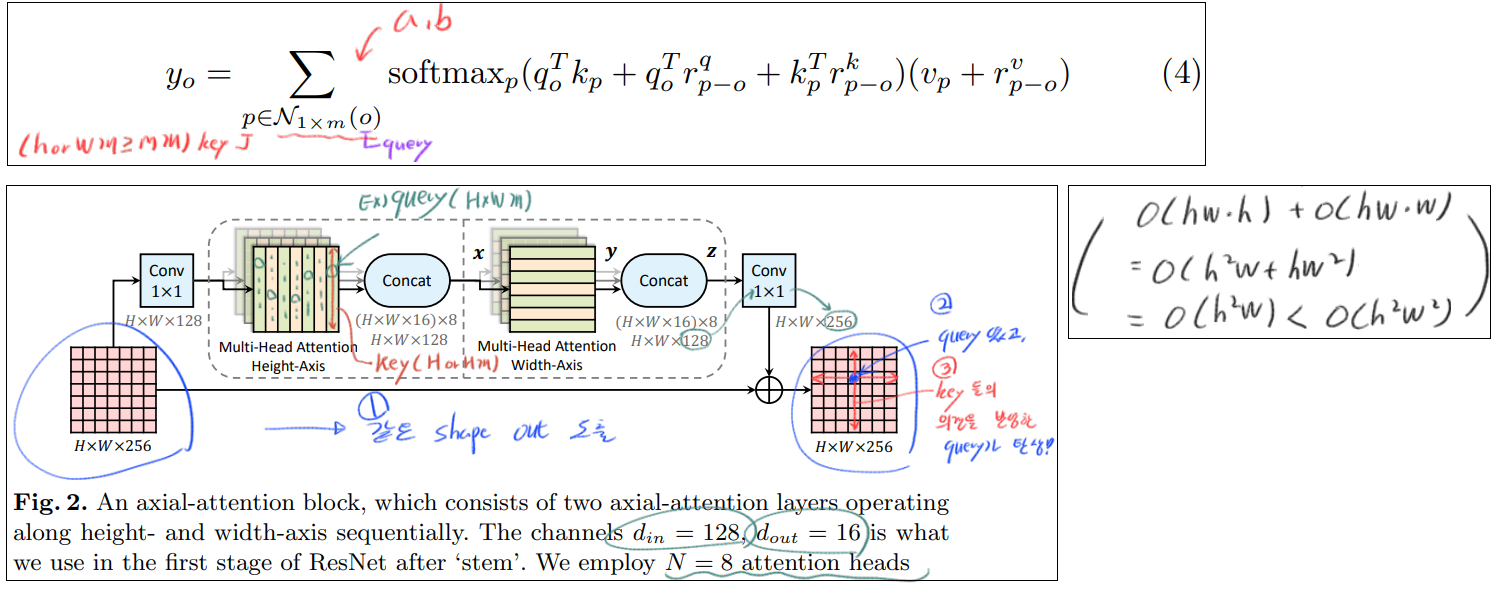
- 어찌보면, Stand-alone은 MxM만을 고려하니까, 이러한 receptive field가 local constraint로써, 단점으로 작용할 수 있다. 물론 global connection (HW 모두를 key로 사용하는 것)보다는 computational costs를 줄일 수 있어서 좋았다.
- Axial-attention의 시간 복잡도는 O(hw(query갯수) x m^2(key갯수=H or W) ) 이다. m에 제곱에 비례한 시간 복잡도를 가지고 있다.
- axial-attention를 이용해서
- (장점1) global connection(=capture global information) 을 사용하고
- (장점2) 각 query에 HW를 모두 key로 사용하는 것 보다는, efficient computation 을 획득한다. 위 그림과 같이 width-axis, height-axis 방향으로 2번 적용한다.
3.5 Axial-ResNet
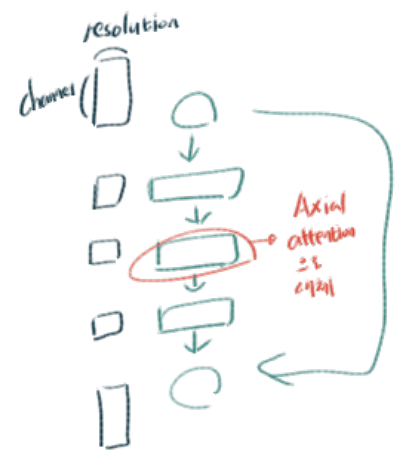
- 별거 없고, residual bottleneck block 내부의 일부 conv연산을 Axial atention으로 대체한다.
- 사실 위의 Fig2가 conv연산을 대체하는 Axial atention의 모습이다. 확실히 Input과 ouput의 shape가 같으므로, 어디든 쉽게 붙이고 때며 적용할 수 있는 것을 확인할 수 있다.
- Full Axial-ResNet : simply stack three axial-attention bottleneck blocks. 즉 residual block의 전체 conv를 Axial atention으로 대체하여 사용하는 것이다.
3.6 Axial-DeepLab:
- Panoptic-DeepLab이란? : 각 Final head는 (1) semantic segmentation (2) class-agnostic instance segmentation 결과를 생성해 내고, 이 결과들을 majority voting 기법을 이용해서 merge 하는 방법론이다. Panoptic-DeepLab논문 참조.
- DeepLab에서 stride를 변경하고 atrous rates를 사용해서 dense feature maps을 뽑아내었다. 우리는 axial-attention을 사용함으로써 충분한 global information을 뽑아내기 때문에, ‘atrous’ attention (?)을 사용하지 않았고, stride of the last stage (?)를 제거했다고 한다.
- 같은 이유로, global information은 충분하기 때문에, atrous spatial pyramid pooling module를 사용하지 않았다.
- extremely large inputs 에 대해서는 m = 65을 가지는 mxm주변의 영역에 대해서만 axial-attention blocks 을 적용했다. (? 정확하게 맞는지 모르겠다)
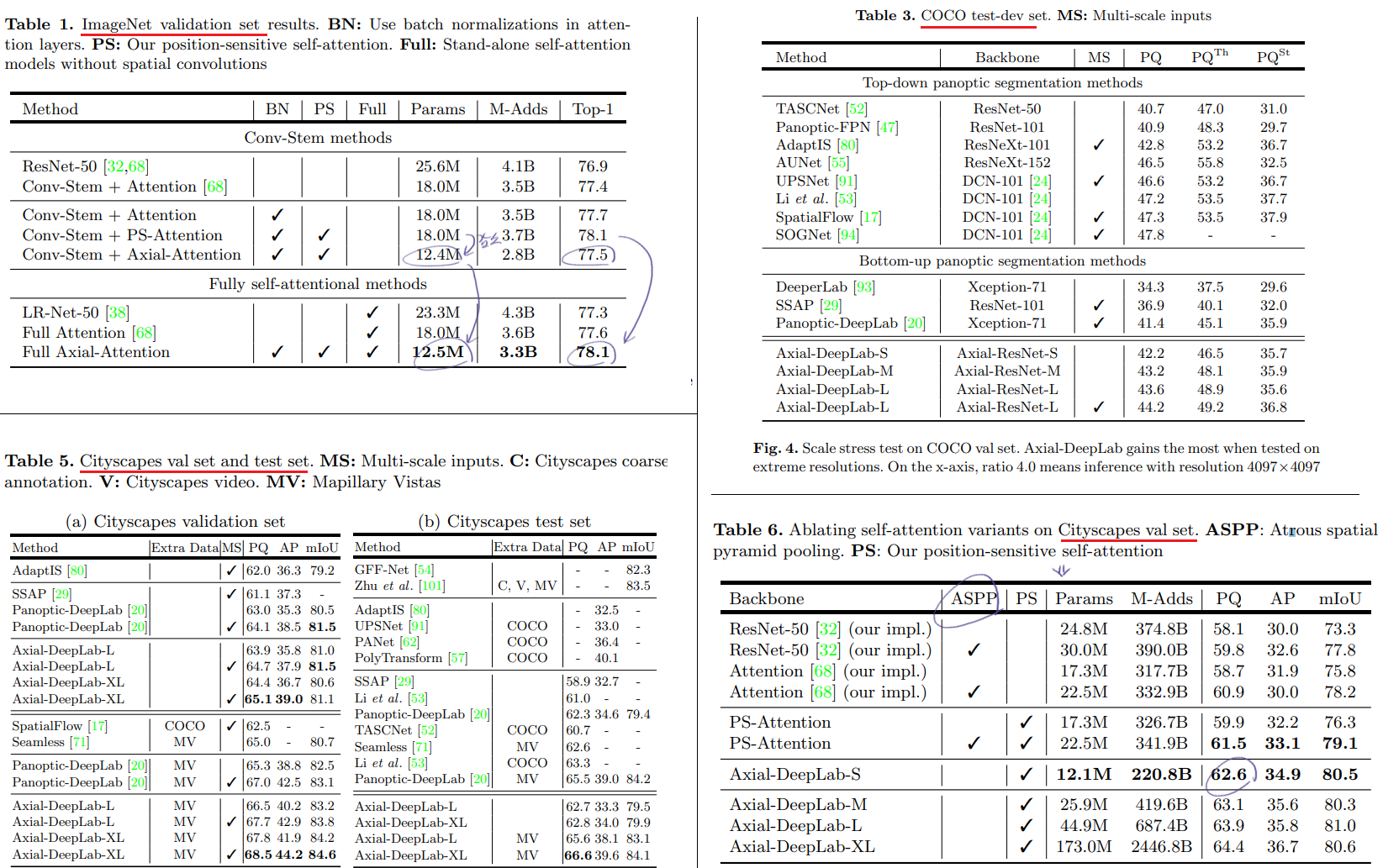
4. Experimental Results
- 사실 이 이후로는 논문 안 읽었다. 필요하면 찾아 읽자.
youtube 내용 정리
- Intro & Overview
- transformer가 NLP에서 LSTM을 대체한 것 처럼, Image process에서도 convolution을 대체할 것이다. 이러한 방향으로 가는 step이 이 논문이라고 할 수 있다.
- From Convolution to Self-Attention for Images
- https://www.youtube.com/watch?v=hv3UO3G0Ofo&t=380s
- Learned Positional Embeddings
- Propagating Positional Embeddings through Layers
- Traditional vs Position-Augmented Attention
- Axial Attention
- Replacing Convolutions in ResNet
- Experimental Results & Examples