
I am a Ph.D. candidate at KAIST advised by Prof. Jaegul Choo, with an M.S. degree from KAIST under Prof. In So Kweon. My graduate research has been shaped by collaborations with Carnegie Mellon University, NAVER AI Lab, Lunit AI, and Qualcomm AI Research, with a focus on robust visual perception, multimodal AI, and efficient AI systems. I aim to build reliable and accessible AI systems that can benefit people across diverse social and economic backgrounds.
Research Experiences
-
NAVER AI Lab
Apr 2025 - Oct 2025
AI Research Intern
Mentors: Byeongho Heo, Sangdoo Yun, and Dongyoon Han -
Carnegie Mellon University
Aug 2024 - Feb 2025
Visiting Scholar in Computer Science (Korean Government Fellowship)
Collaborating with Prof. Yonatan Bisk's research group -
Lunit
Jun 2023 - Dec 2023
AI Research Intern
Mentors: Tae Soo Kim, and Thijs Kooi -
Qualcomm
Jul 2022 - Dec 2022
AI Research Intern
Mentor: Sungha Choi

Publications
-
 Learning to See What You Need: Gaze Attention for Multimodal Large Language Models
Learning to See What You Need: Gaze Attention for Multimodal Large Language Models
Junha Song, Byeongho Heo, Geonmo Gu, Jaegul Choo, Dongyoon Han, and Sangdoo Yun
Under review, 2026.
[arxiv] -
 RL makes MLLMs see better than SFT
RL makes MLLMs see better than SFT
Junha Song, Sangdoo Yun, Dongyoon Han, Jaegul Choo, and Byeongho Heo
In the International Conference on Learning Representations (ICLR), 2026.
[arxiv], [project page], [code] -
 MM-SeR: Multimodal Self-Refinement for Lightweight Image Captioning.
MM-SeR: Multimodal Self-Refinement for Lightweight Image Captioning.
Junha Song, Yongsik Jo, So Yeon Min, Quanting Xie, Taehwan Kim, Yonatan Bisk, and Jaegul Choo
In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026.
[arXiv], [project page] -
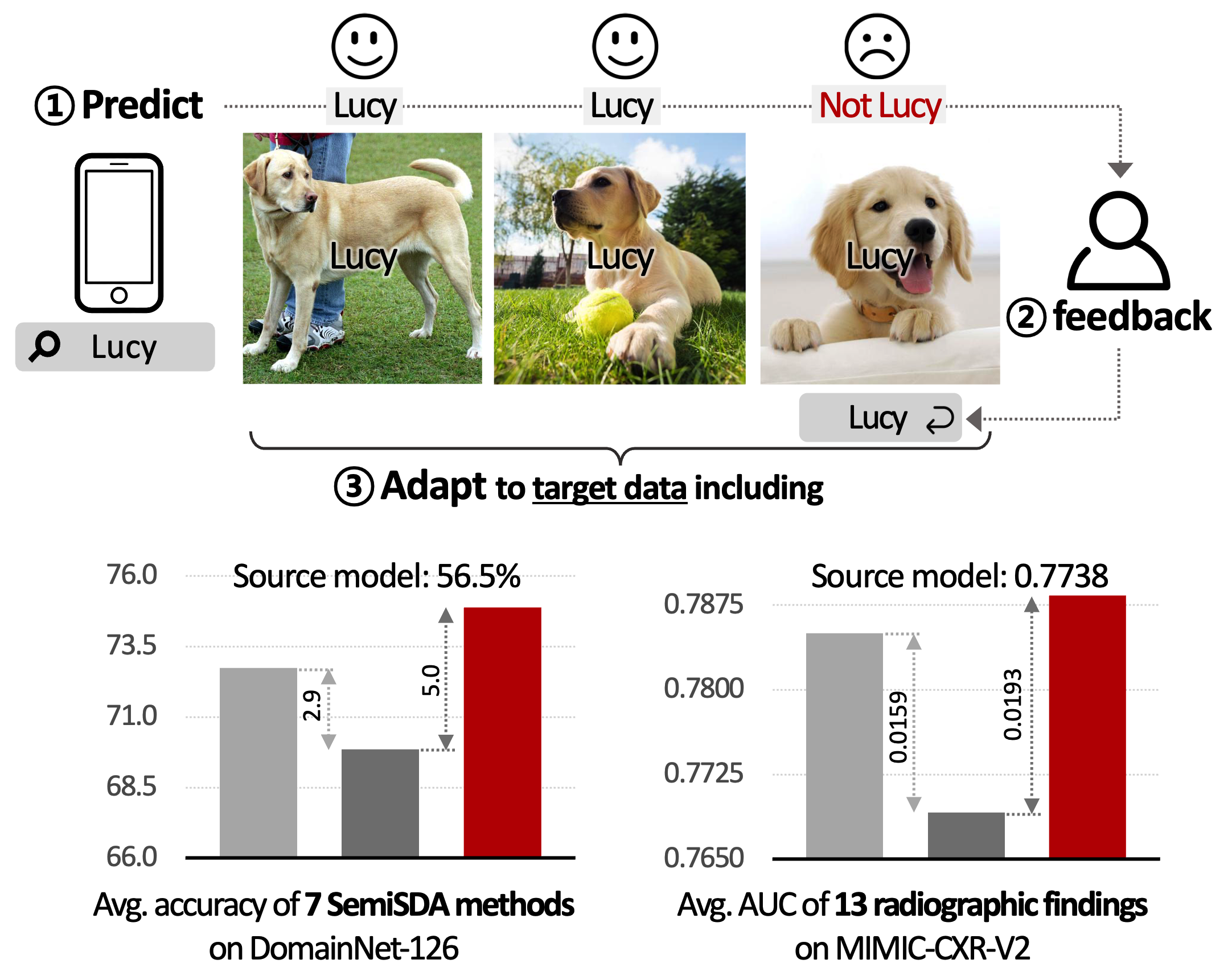 Is user feedback always informative? Retrieval Latent Defending for Semi-Supervised Domain Adaptation without Source Data.
Is user feedback always informative? Retrieval Latent Defending for Semi-Supervised Domain Adaptation without Source Data.
Junha Song, Tae Soo Kim, Gunhee Nam, Junha Kim, Thijs Kooi, and Jaegul Choo
In the European Conference on Computer Vision (ECCV), 2024
[arXiv], [project page], [code] -
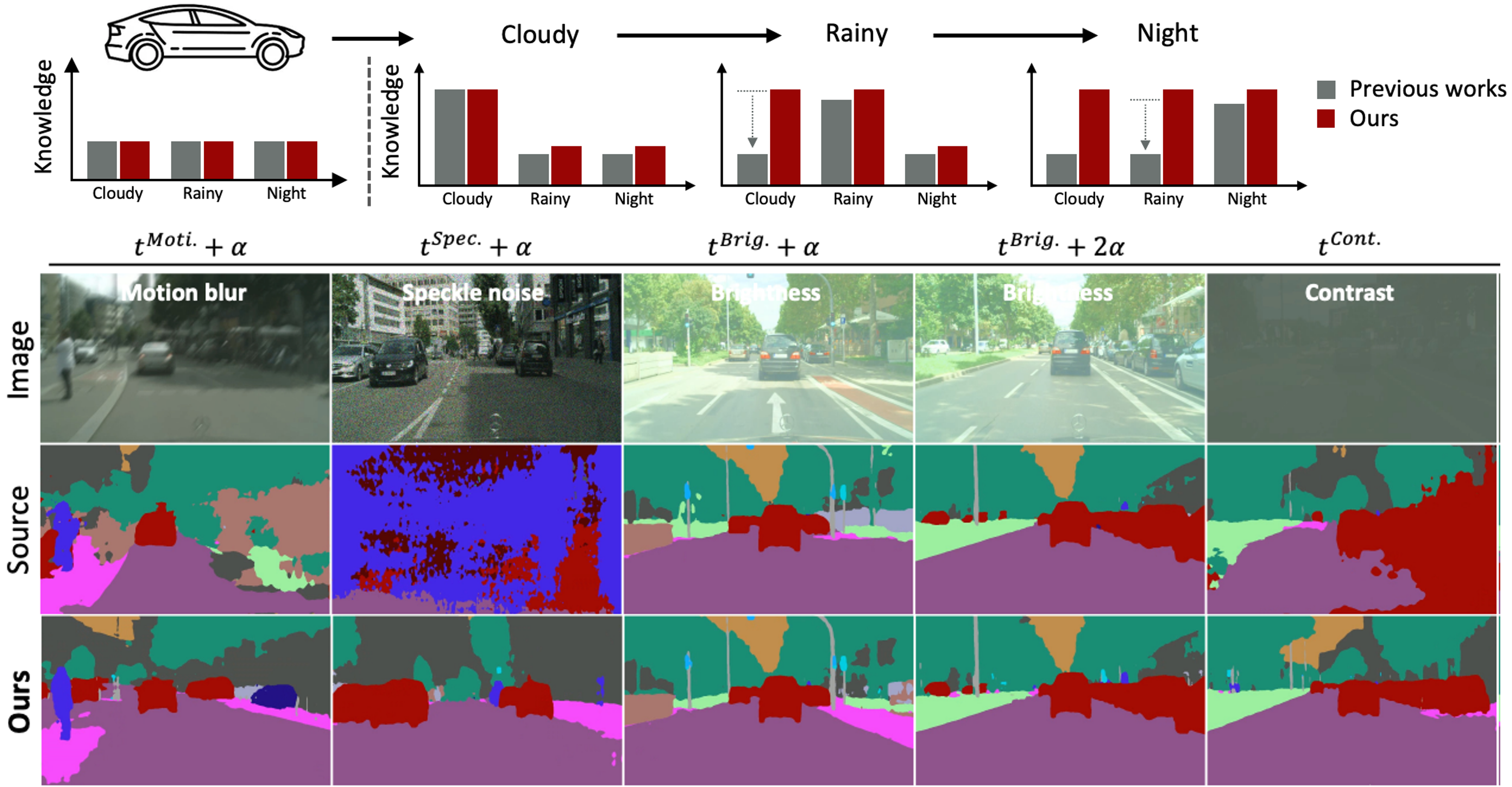 Test-time Adaptation in the Dynamic World with Compound Domain Knowledge Management.
Test-time Adaptation in the Dynamic World with Compound Domain Knowledge Management.
Junha Song, Kwanyong Park, Inkyu Shin, Sanghyun Woo, Chaoning Zhang, and In So Kweon
In IEEE Robotics and Automation Letters (RA-L, ICRA Oral), 2024
[arXiv], [IEEE], [Youtube] -
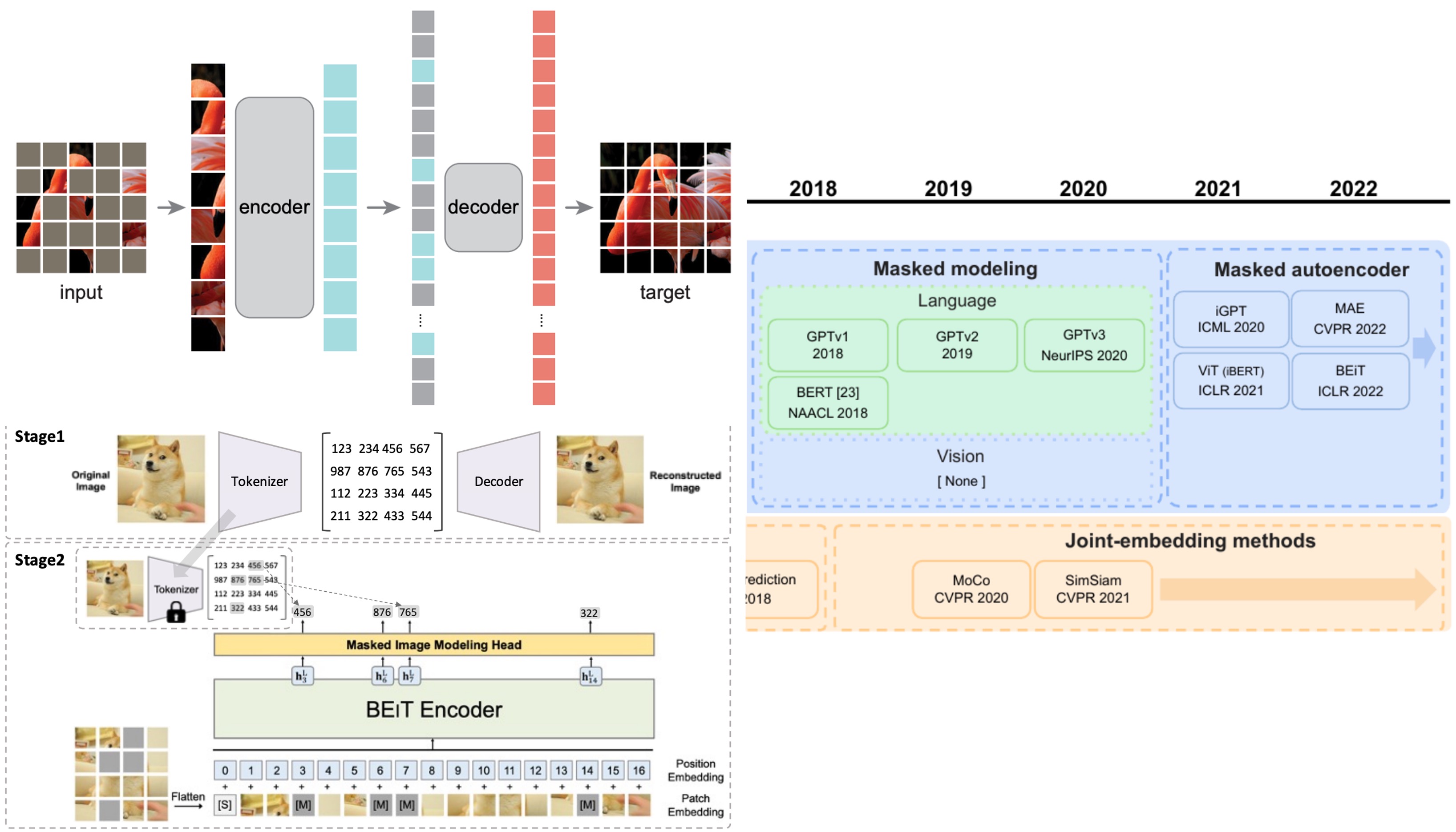 A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond.
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond.
Chaoning Zhang, Chenshuang Zhang, Junha Song, John Seon Keun Yi, and In So Kweon
In the International Joint Conference on Artificial Intelligence (IJCAI), 2023.
[arXiv], [slide] -
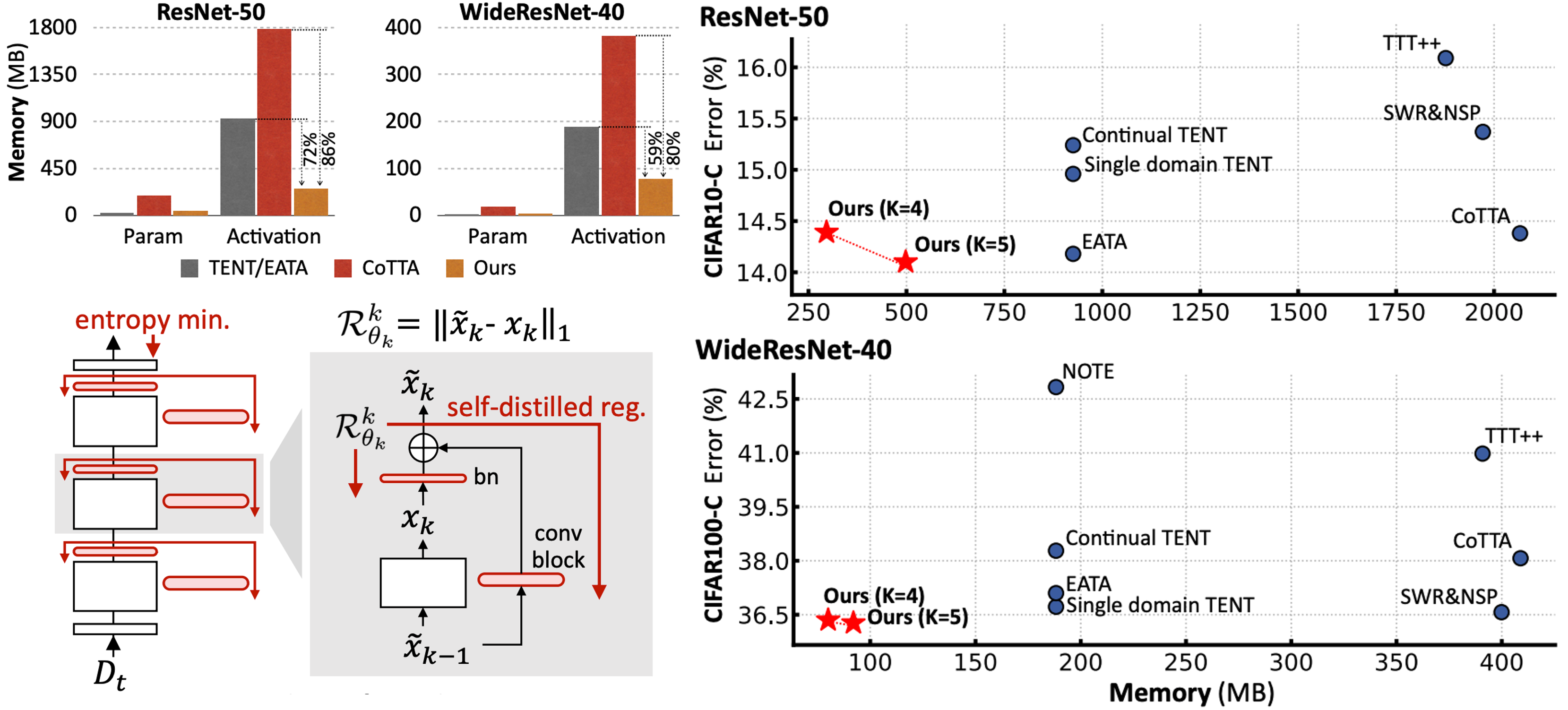 EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization.
Junha Song, Jungsoo Lee, In So Kweon, and Sungha Choi
In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[arXiv], [project page]
Patents
-
Test-time adaptation via self-distilled regularization
Junha Song and Sungha Choi. 15 May, 2024. [U.S. Patent No. US20240160926A1]
Research Interests
I live by a simple motto: 'live life with full passion, and work with the greatest people.' The directions below reflect my current focus, but my interests are by no means limited to them.
-
Visual representation learning & World model
- Current vision encoders still fall short of providing precise visual states for robotic and interactive agents. I am interested in building visual representations that enable agents to perceive, predict, and interact reliably in real environments. A foundation for this exploration is classical self-supervised learning (SSL) in vision—jigsaw puzzles, rotation prediction, contrastive learning, and masked image modeling—which has produced strong general-purpose visual features. In IJCAI'23, I surveyed masked autoencoders as a generative paradigm for visual pretraining. My ICLR'26 work analyzes how visual representations evolve during MLLM training, showing that RL can boost the vision encoder effectively. Going forward, I aim to pursue SSL within unified multimodal models (UMMs) that jointly perform visual understanding and generation. I view UMMs as natural candidates for world models, which demand visual representations rich enough to anticipate how the world unfolds. This aligns with recent work on unified multimodal pretraining and the broader agenda of AMI Labs.
-
Multimodal LLMs and Agentic AI & RL
- Multimodal LLMs are emerging as capable visual assistants, yet they often miss fine-grained details and fail to ground their responses in the visual evidence. In CVPR'26, I studied multimodal self-refinement for revisiting visual evidence after an initial description. The arXiv'26 Gaze Attention enables MLLMs to attend to task-relevant visual regions during generation, avoiding redundant visual tokens. The ICLR'26 work examines how to post-train MLLMs for better visual understanding, showing that RL is more effective than SFT. Looking ahead, I want to extend these efforts to agentic AI systems, where multimodal models must perceive accurately while supporting tool use and planning. I am particularly interested in RL methods that make visual perception reliable enough for agentic decision-making.
-
Efficient AI systems
- Strong AI systems demand attention not only to capability but also to efficiency—training cost, inference latency, and memory usage. These constraints determine where AI can actually be deployed, especially in on-device and edge settings. My CVPR'23 EcoTTA work addressed memory-efficient continual test-time adaptation. In CVPR'26, I showed a lightweight captioning model can rival larger MLLMs, enabling on-device deployment. More recently, my arXiv'26 Gaze Attention work shrinks the visual KV cache by up to 90% while matching dense-attention baselines. Looking ahead, I want to extend these efforts to agentic systems, where RL, tool routing, and long-context processing introduce new computational and memory bottlenecks.
-
Robust and self-improving AI systems
- My earlier robustness research focused on domain adaptation in classical vision settings, improving classification and segmentation under distribution shift. My CVPR'23 studied test-time adaptation that stays stable over long-term deployment by mitigating catastrophic forgetting. RA-L/ICRA'24 extended this to dynamic environments, where domains can shift abruptly. ECCV'24 showed that user feedback is naturally biased toward a model's wrong predictions, which can degrade adaptation rather than improve it. These projects shaped my interest in self-improving systems that learn from changing environments. I want to revisit this direction with modern multimodal LLMs and agentic AI, in line with the broader push toward open-ended, self-improving AI pursued by Recursive Superintelligence.
Education
-
Korea Advanced Institute of Science and Technology (KAIST)
Aug 2023 - Present
Ph.D student in Graduate School of AI
Advisor: Prof. Jaegul Choo -
Korea Advanced Institute of Science and Technology (KAIST)
Feb 2021 - Feb 2023
M.S. degree in the Division of Future Vehicle
Advisor: Prof. In So Kweon
Grade: 3.9 / 4.3 (Percent: 95.56/100) -
Kookmin University (Seoul, South Korea)
Feb 2015 - Feb 2021
B.S. degree in IT and Automobile Engineering
Grade: 4.39 / 4.5 (Rank: 1/121 | Percent: 98.7/100 | Major: 4.43)
National Science and Engineering Scholarship (Full tuition) from Korea Student Aid Foundation
Mandatory Military Service for 21 Months
Awards and Honors
- Intensive 2-Week Guest Lecturer, Introduction to Deep Learning, LG Innotek (2024)
- Best Master's Thesis Award, Korea Advanced Institute of Science and Technology (KAIST) (2023)
- Lecture planning consultant, Fast Campus (2022)
- Industry-University Scholarship (Full tuition support for M.S. program), Hyundai Mobis (2021–2022)
- National Science and Engineering Scholarship (Full tuition support for B.S. program), Korea Scholarship Foundation (2019–2021)
- Future Transport Design Award and Honorable Judge Award, 'Vehicle monitoring over internet toward digital twins', Cloud Programming World Cup, Japan (2019)
- Capstone Awards, Korean Society of Automotive Engineers (2019)
Projects
- Development of real-time masking/unmasking system for personal video information for public services such as CCTV (article), Korea Ministry of Science and ICT (2021 - 2023)
- Development of segmentation networks robust to environment variance, Hyundai Mobis (2021)
- Satellite image precision object detection, Korea Agency for Defense Development (ADD) (2020)
- Detection of Surrounding Vehicles using Deep Neural Network and Fusion of Panoramic Camera and Lidar Sensor, Korea Foundation for the Advancement of Science and Creativity (KORAC), Korea (2019)
B.S. Research Experiences
- "Style Transfer Maps from Satellite Images by using Generative Model", Korean Institute of Communications and Information Science (KICS) (2020)
- "Improvement of LiDAR and IMU-based autonomous driving performance in right-angle corner situations", Korean Sociey of Automotive Engineers (2019)
- Research Intern at Machine Intelligence Lab, Kookmin University (Dec 2019 - Oct 2020)
- Research Intern at Intelligence and Interaction Lab, Kookmin University (Feb 2019 - Nov 2019)
Skills
- Programming language: Python, C++
- Machine Learning Librarie: Pytorch, Tensorflow
- Application development: Robot Operating System (ROS)
- Sensor utilization: Camera, RGB-D Camera, LiDAR, GPS/IMU