-
논문1 : MnasNet: Platform-Aware Neural Architecture Search for Mobile / Youtube Link
-
논문2 : NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection / Youtube Link
-
분류 : LightWeight
-
저자 : Mingxing Tan, Bo Chen, Ruoming Pang, / Golnaz Ghiasi, Tsung-Yi Lin
-
읽으면서 생각할 포인트 : 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
-
느낀점 :
-
목차
-
읽으면 좋은 기초 논문
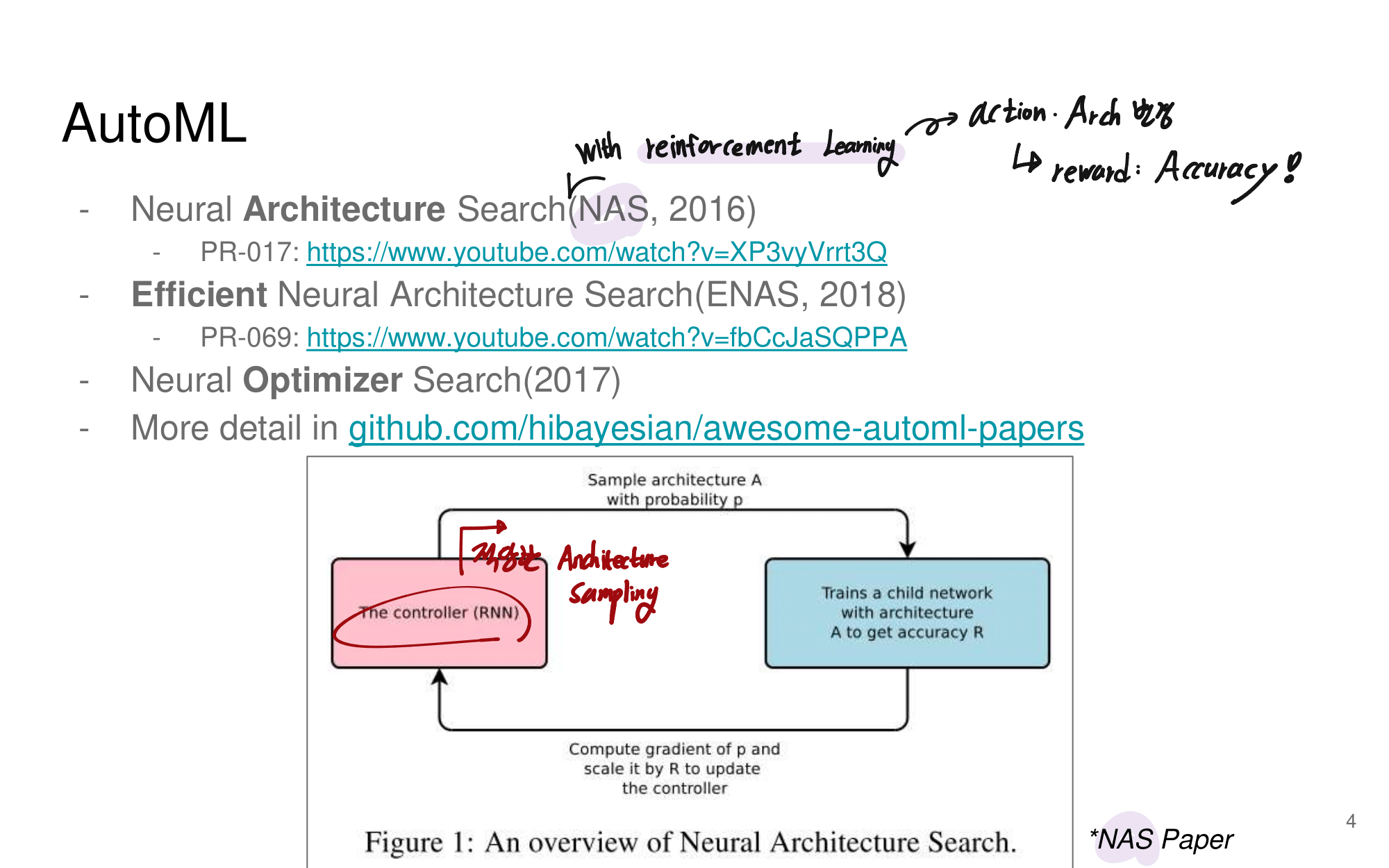
- NAS (Neural Architecture Search)
- EnasNet
- Auto-DeepLab (For Image Segmentation)
1. MnasNet from youtube
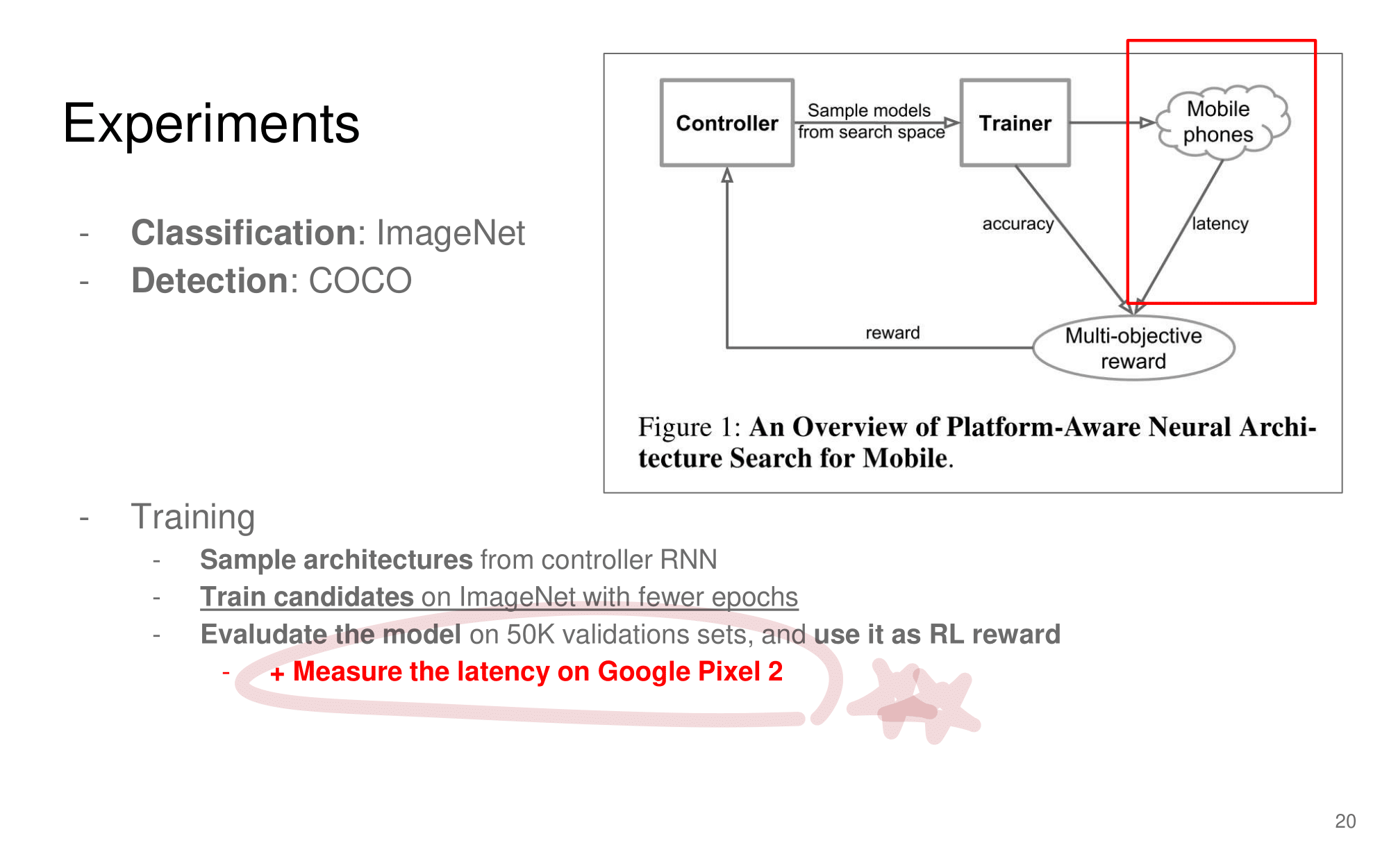
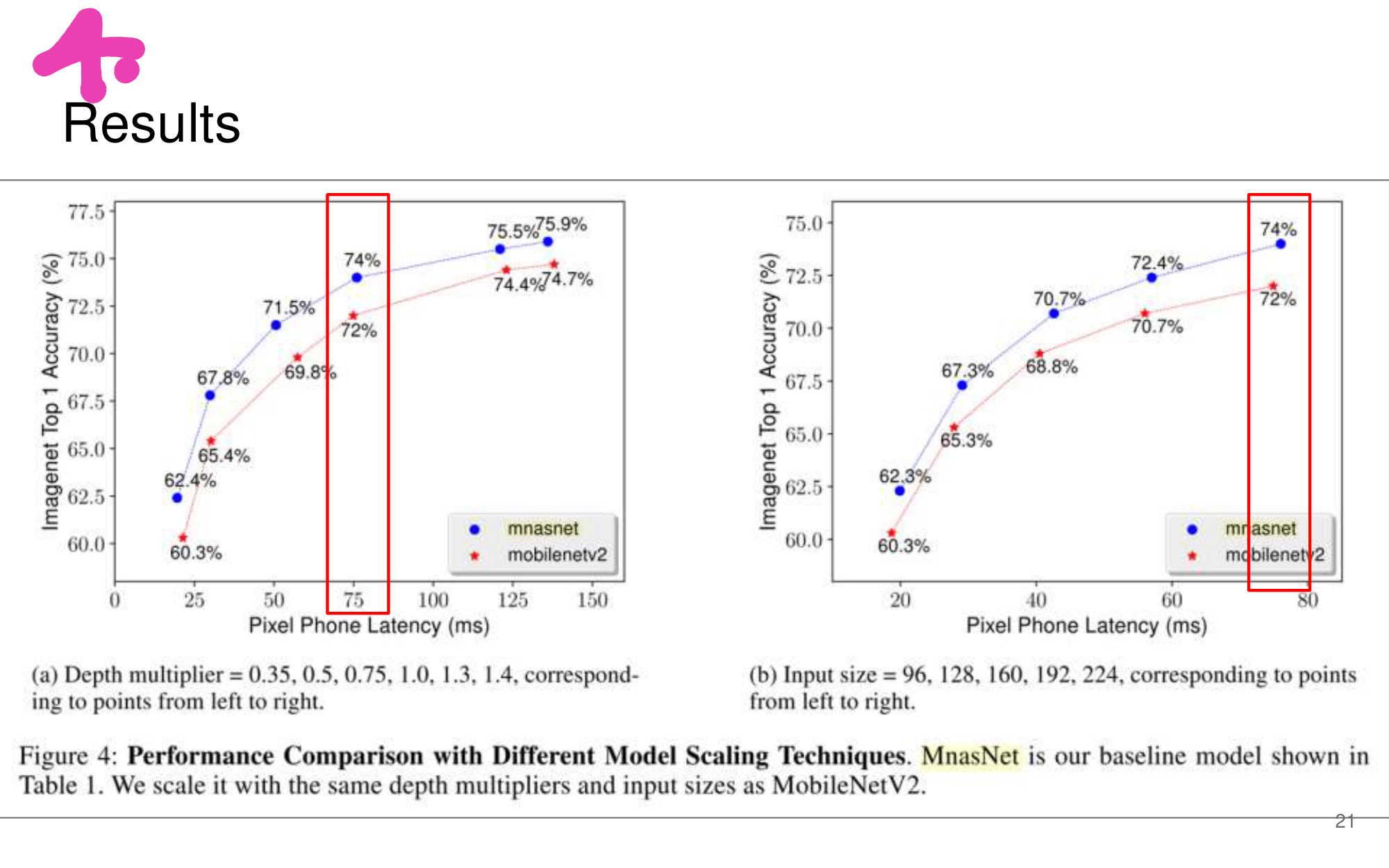
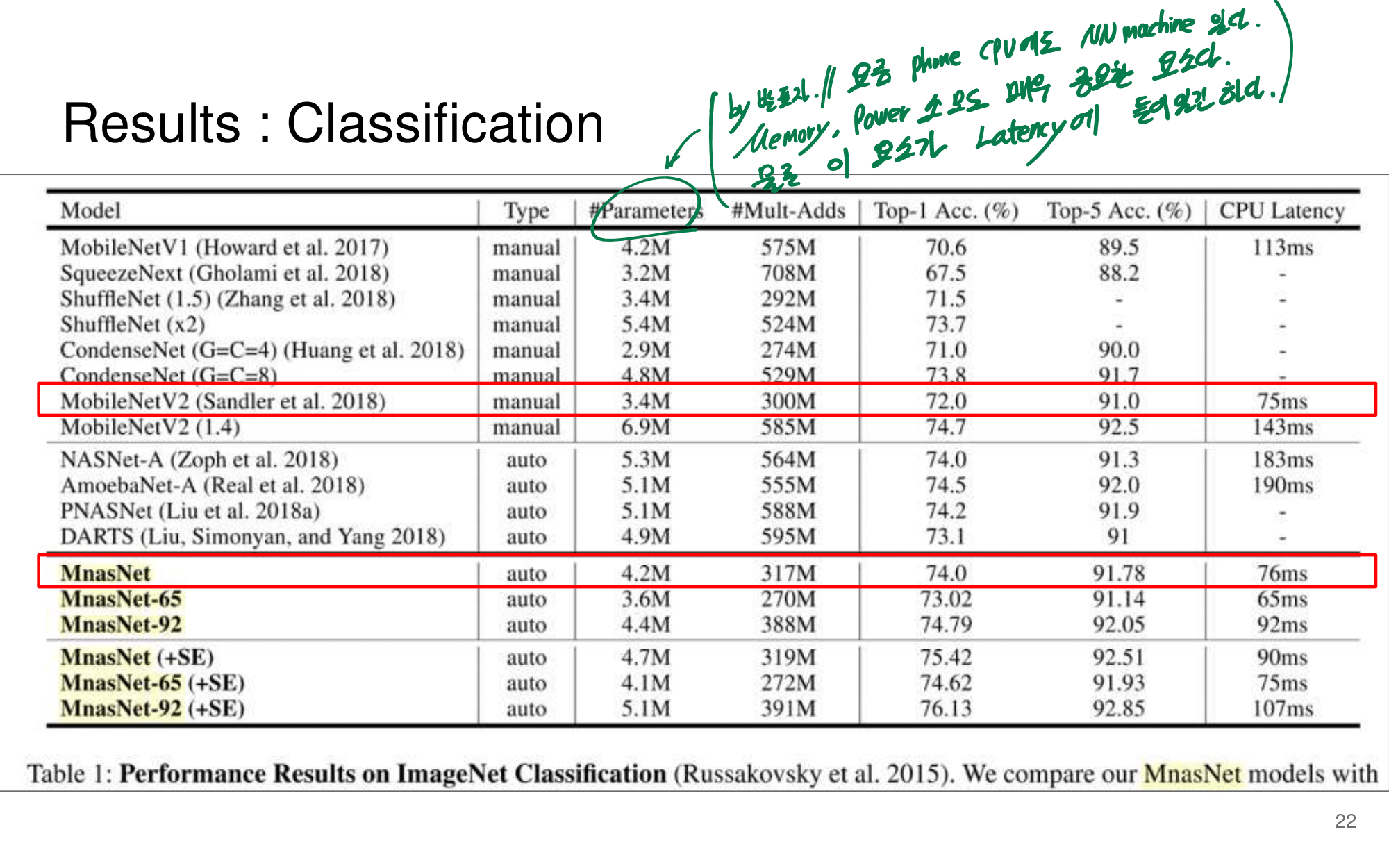
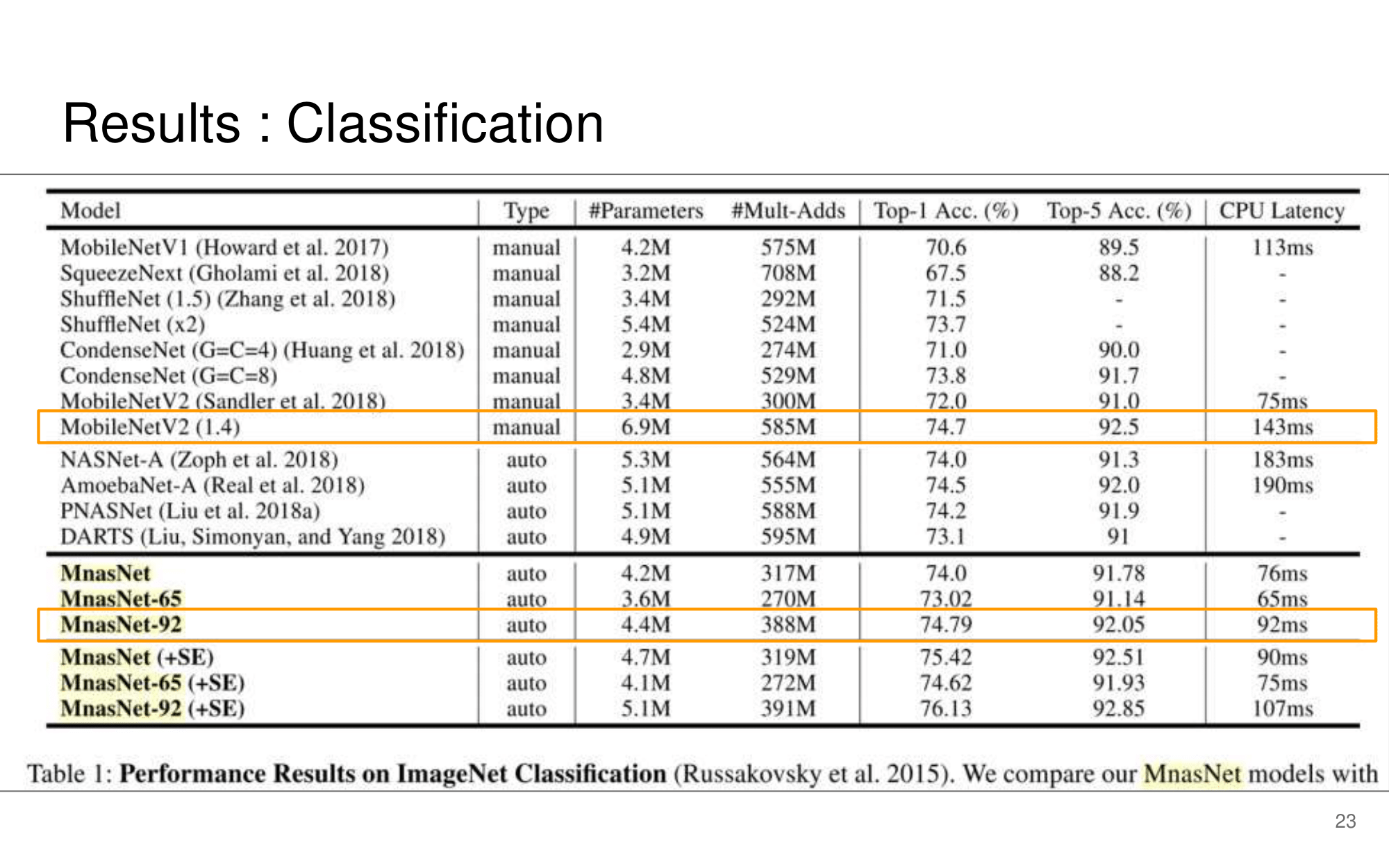
- 논문에 나오는 최종 모델 Architecture
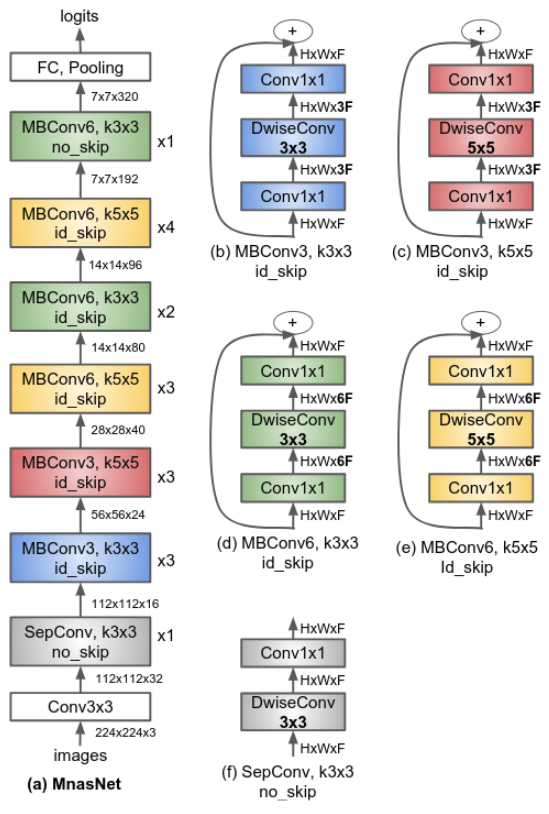
- 발표자분들끼리 하는 이야기로, 이런 NAS 작업을 우리같은 일반인이 하기는 쉽지 않다. 구글의 목표는 “너네가 원하는 신경망을 최적으로 찾고 싶다면, 너네 스스로 하지말고 돈 좀 내고 우리가 만든 플랫폼을 사용해서 최적의 신경망을 찾아” 라는 것을 목표로 한다고 한다. 따라서 NAS를 일반인이 하기에는 더욱 어려운 것 같다.
- 그럼에도 불구하고 이 논문이 나오기 전, EnasNet은 [기존에 800개의 GPU로 21일을 학습시켜서 최적의 모델을 찾은 NAS]에 비해서 학습 효율이 더 좋게 만들기 위한 목적을 가지고 있다. 1개의 GPU로 8시간을 학습했다고 한다. 나중에 정말 NAS를 공부해야한다면 EnasNet 또한 읽어보는 것도 좋겠다.
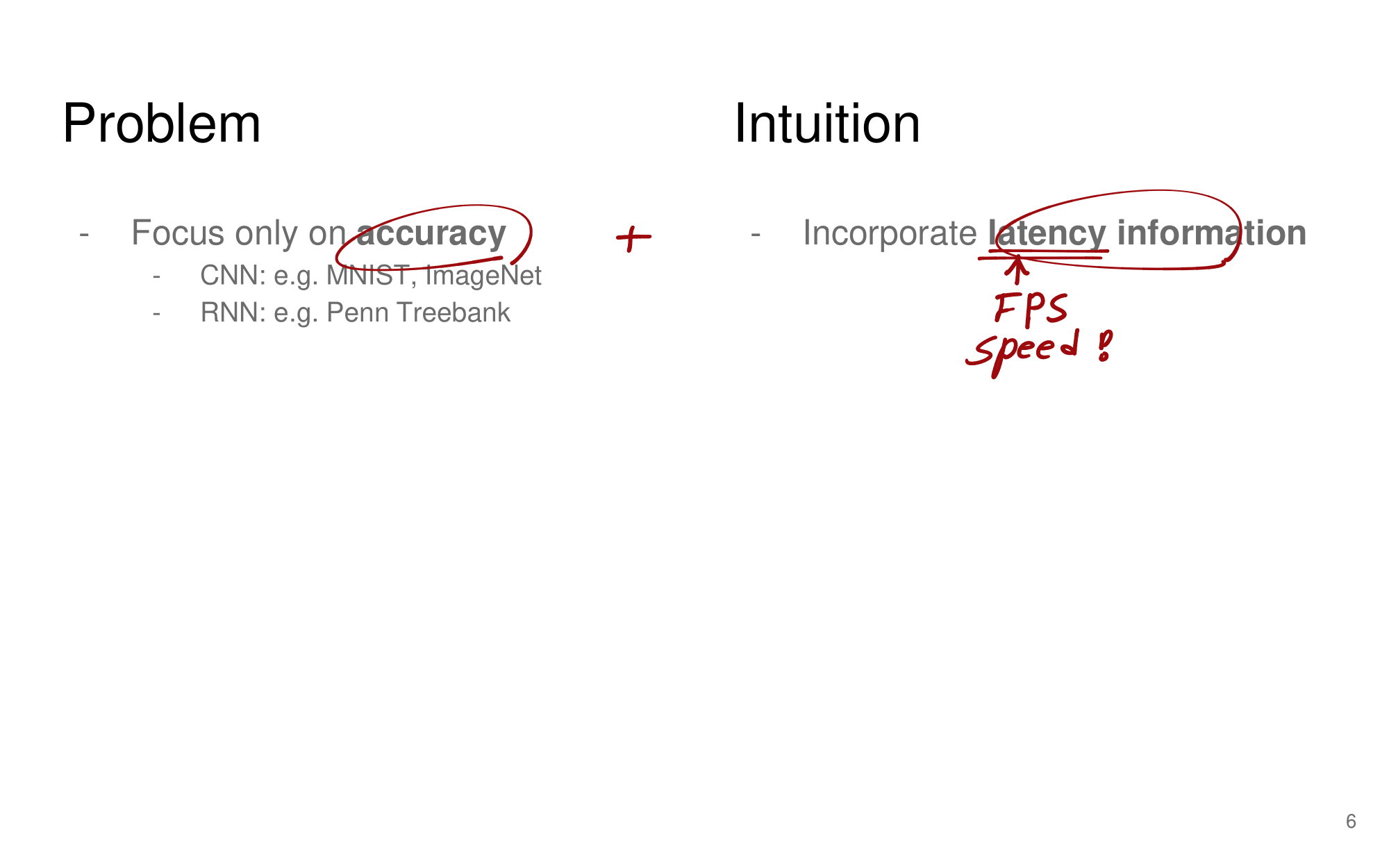
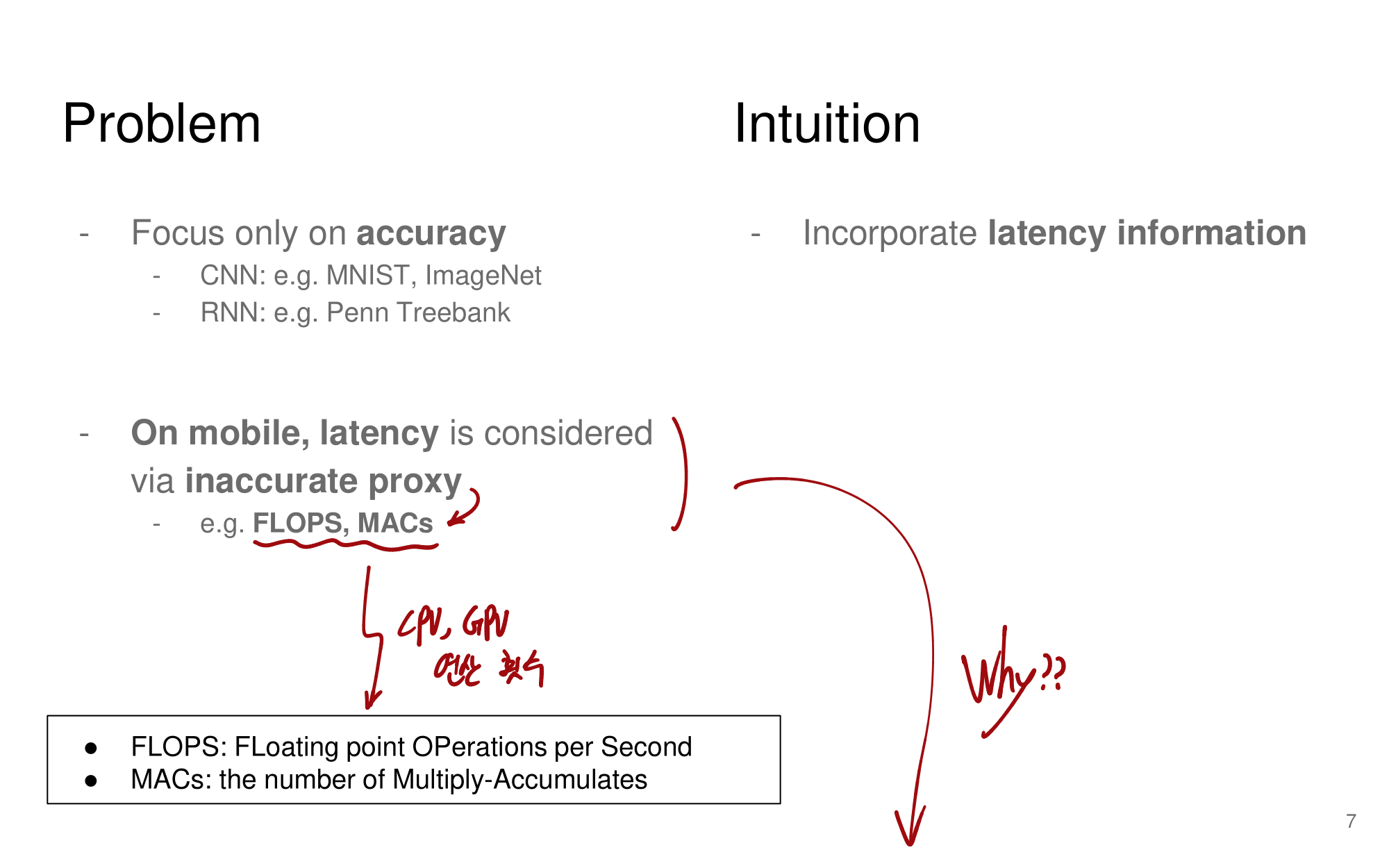
- 강의 필기 자료




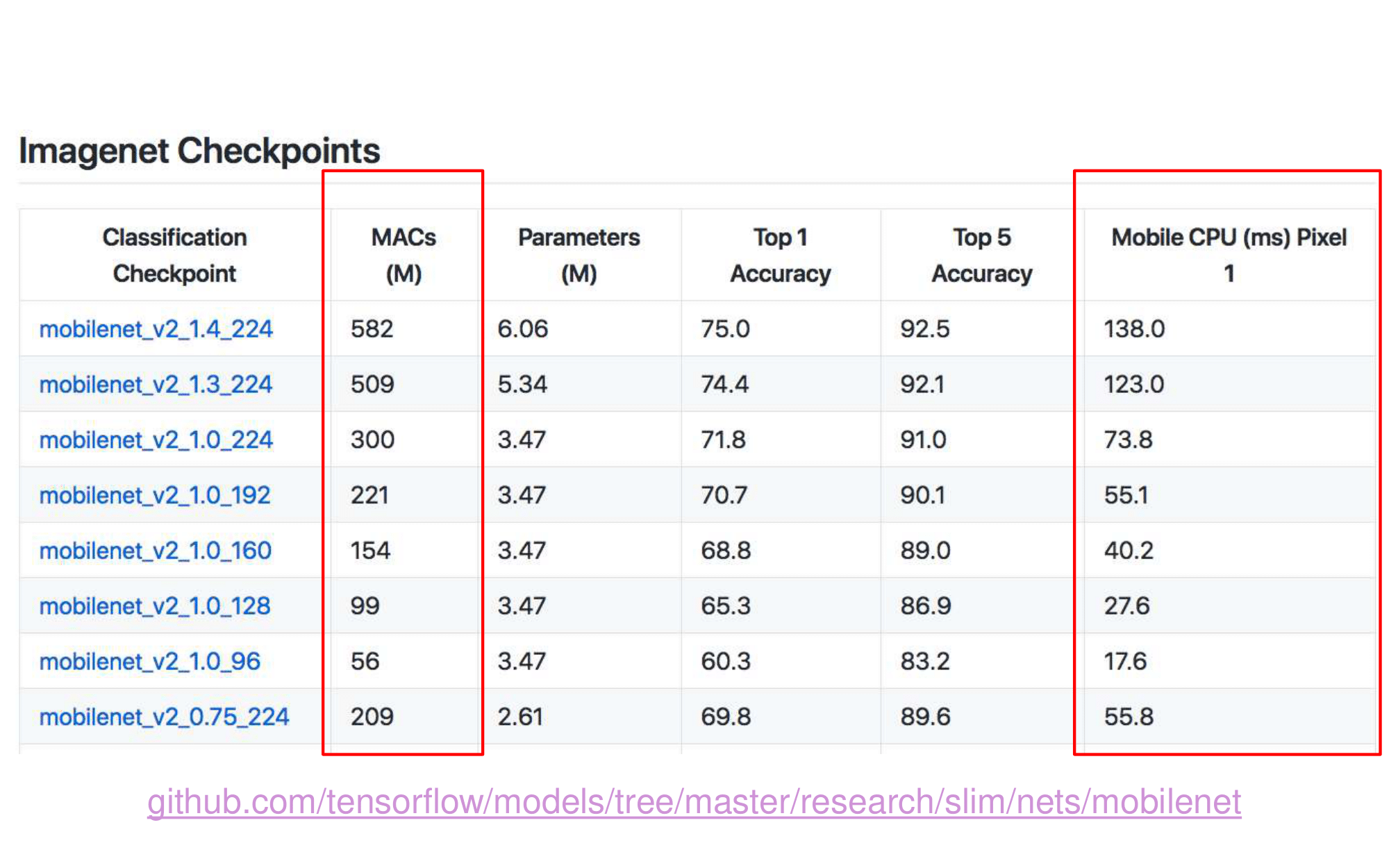
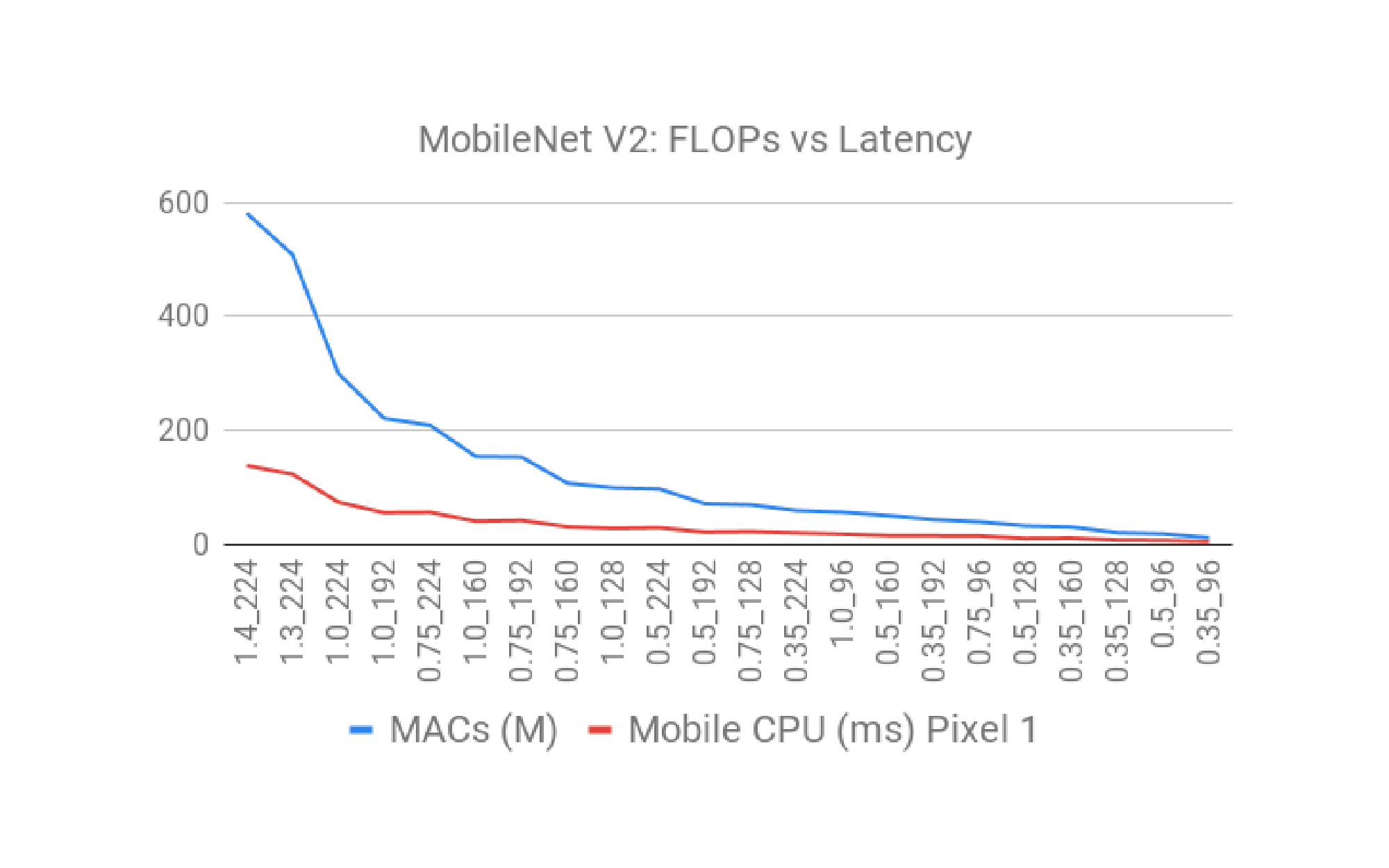

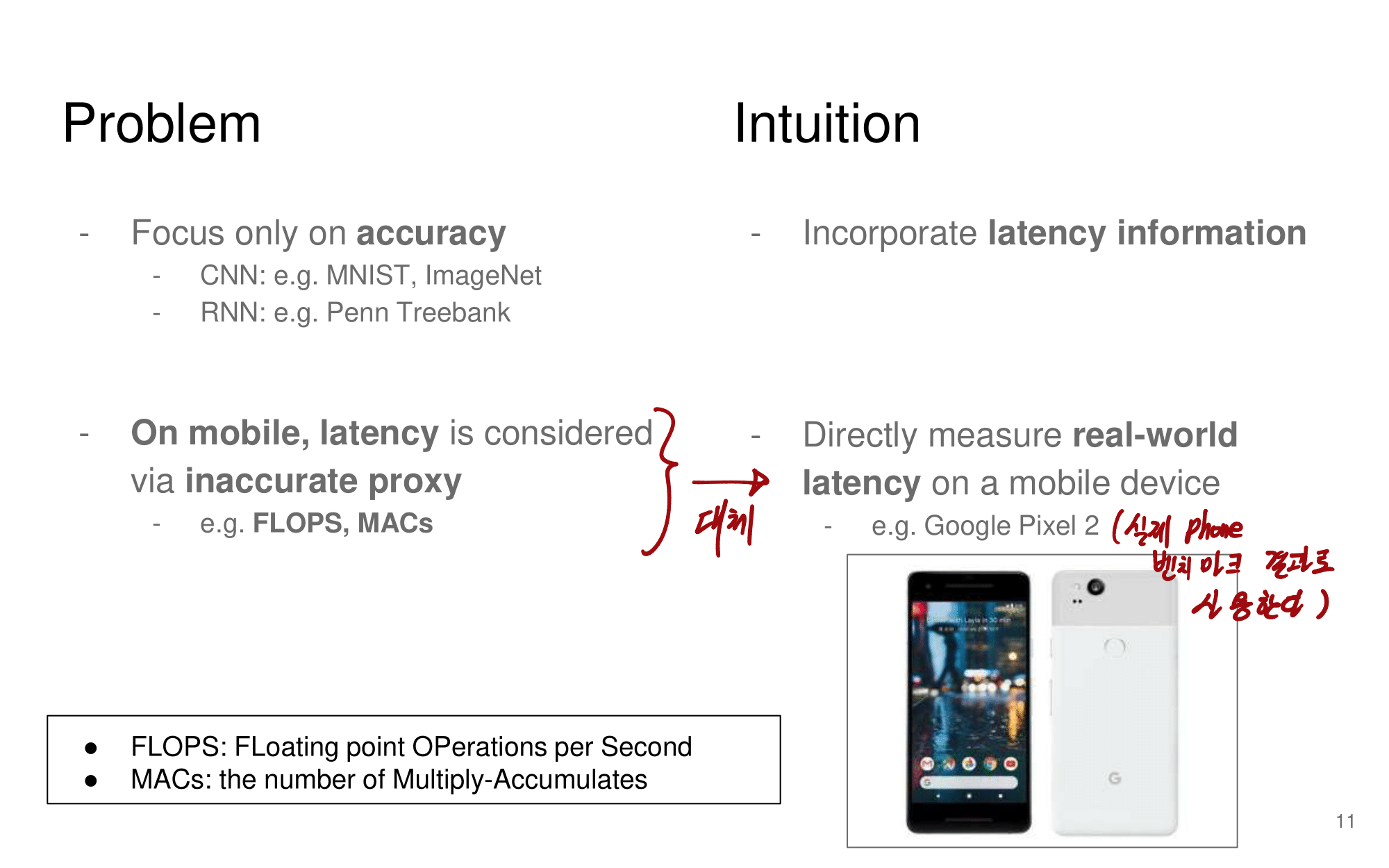

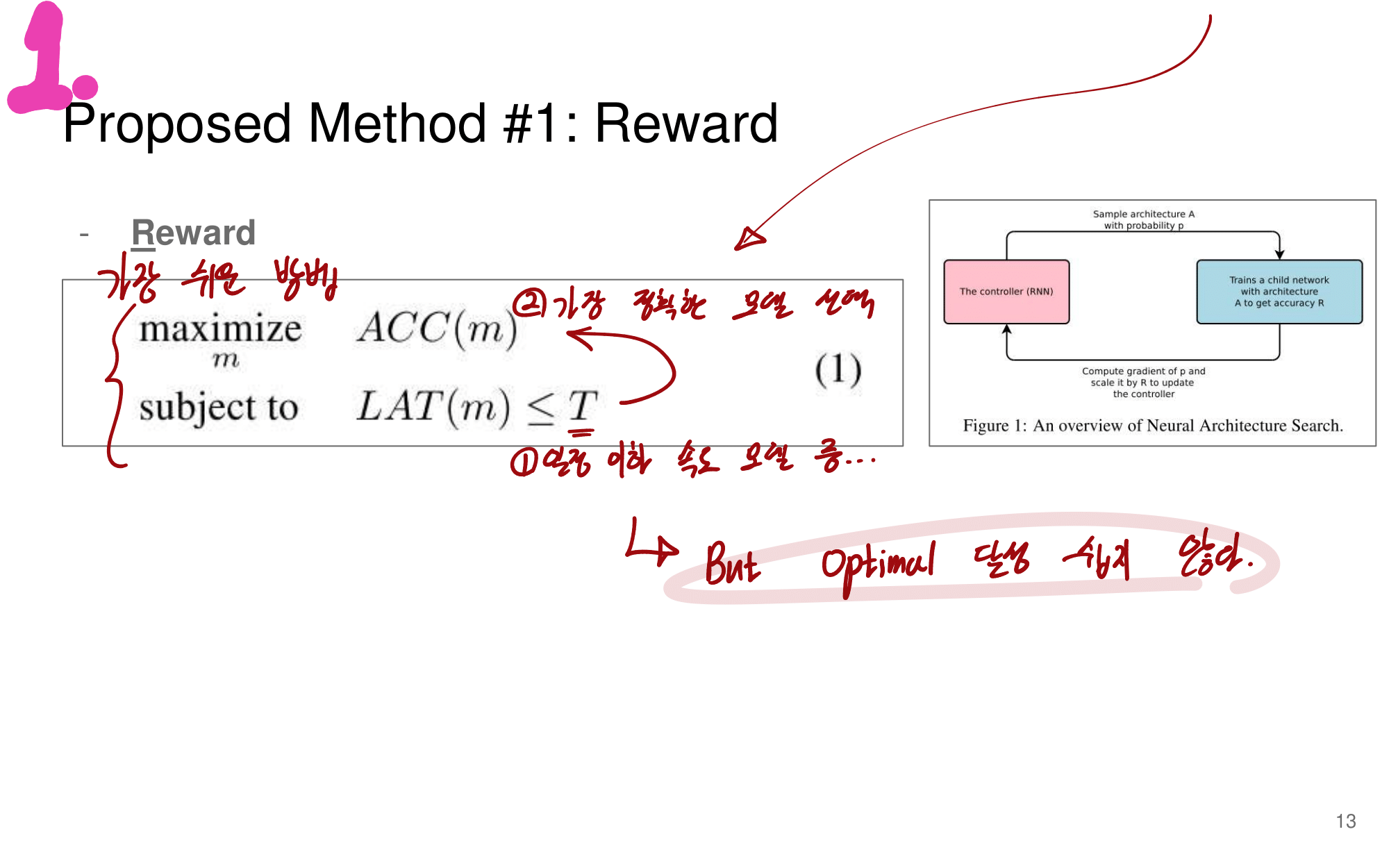

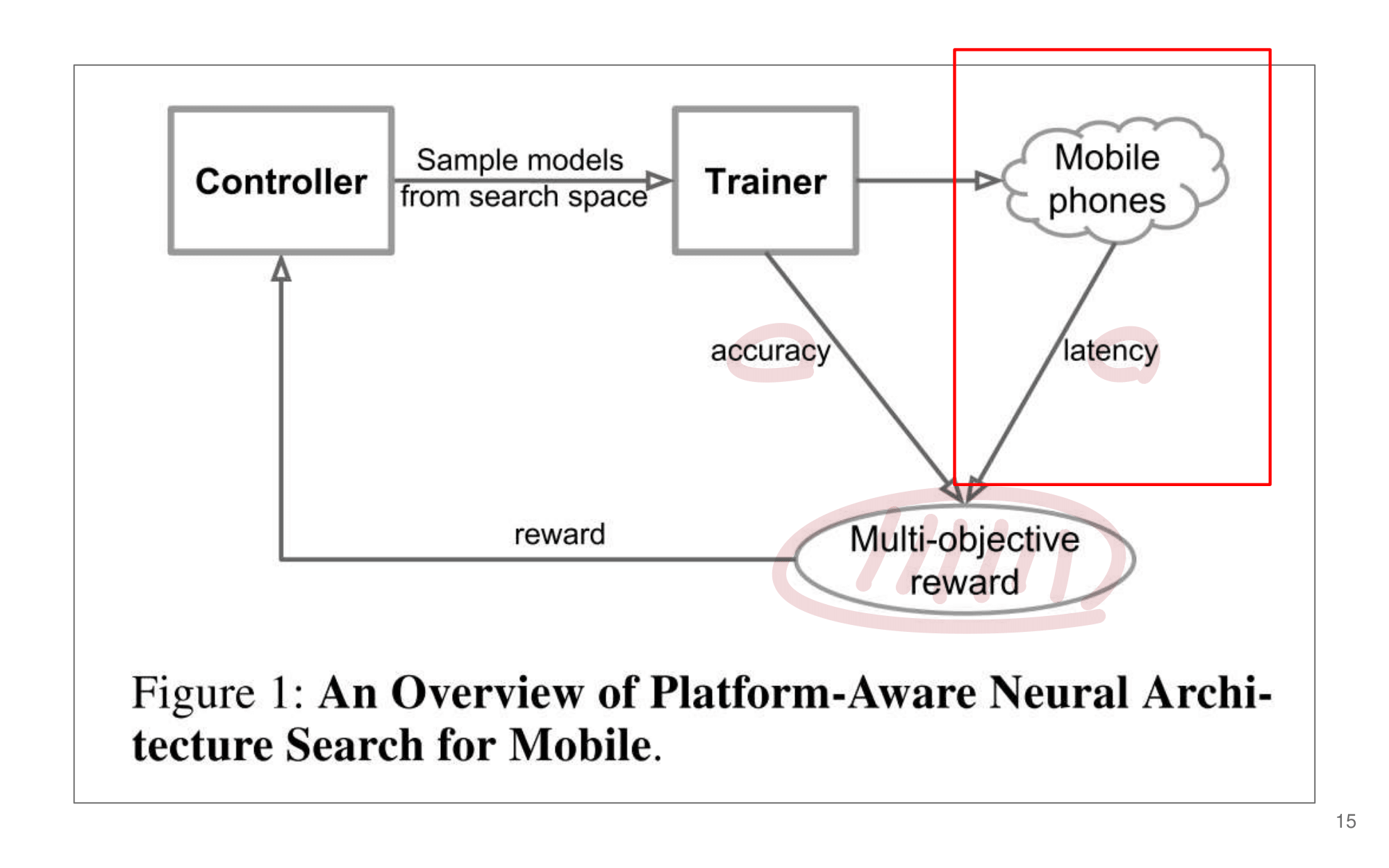
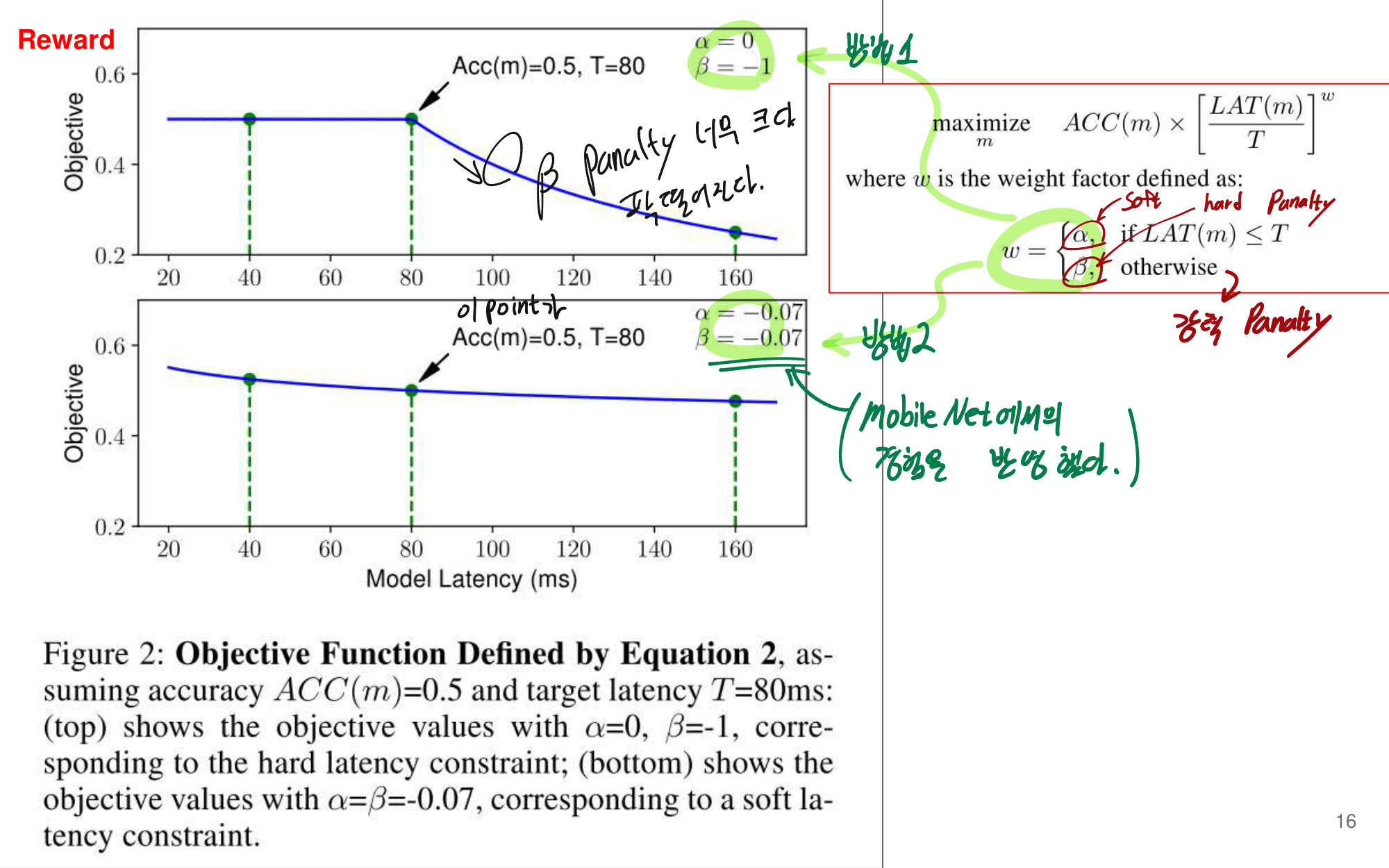
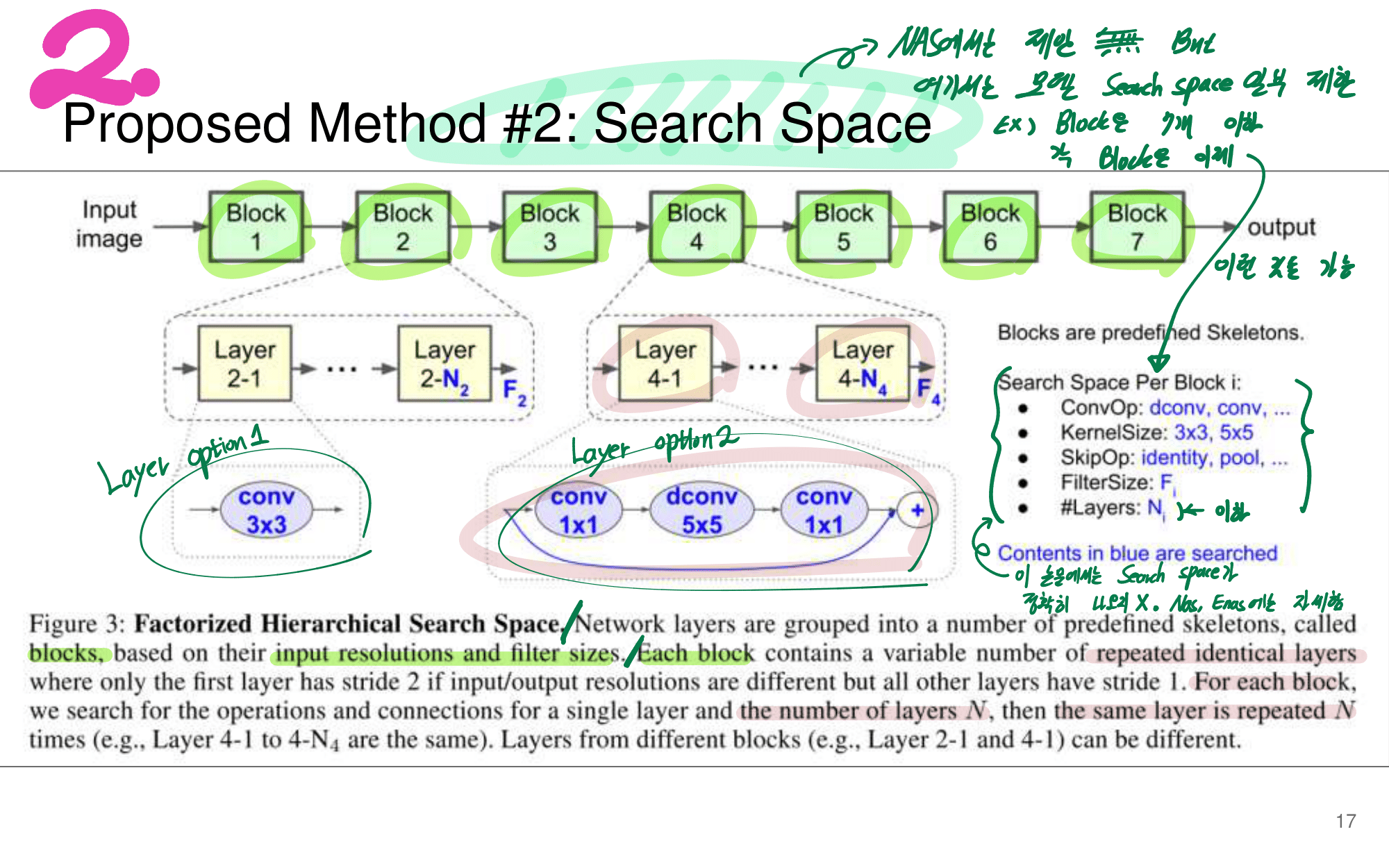
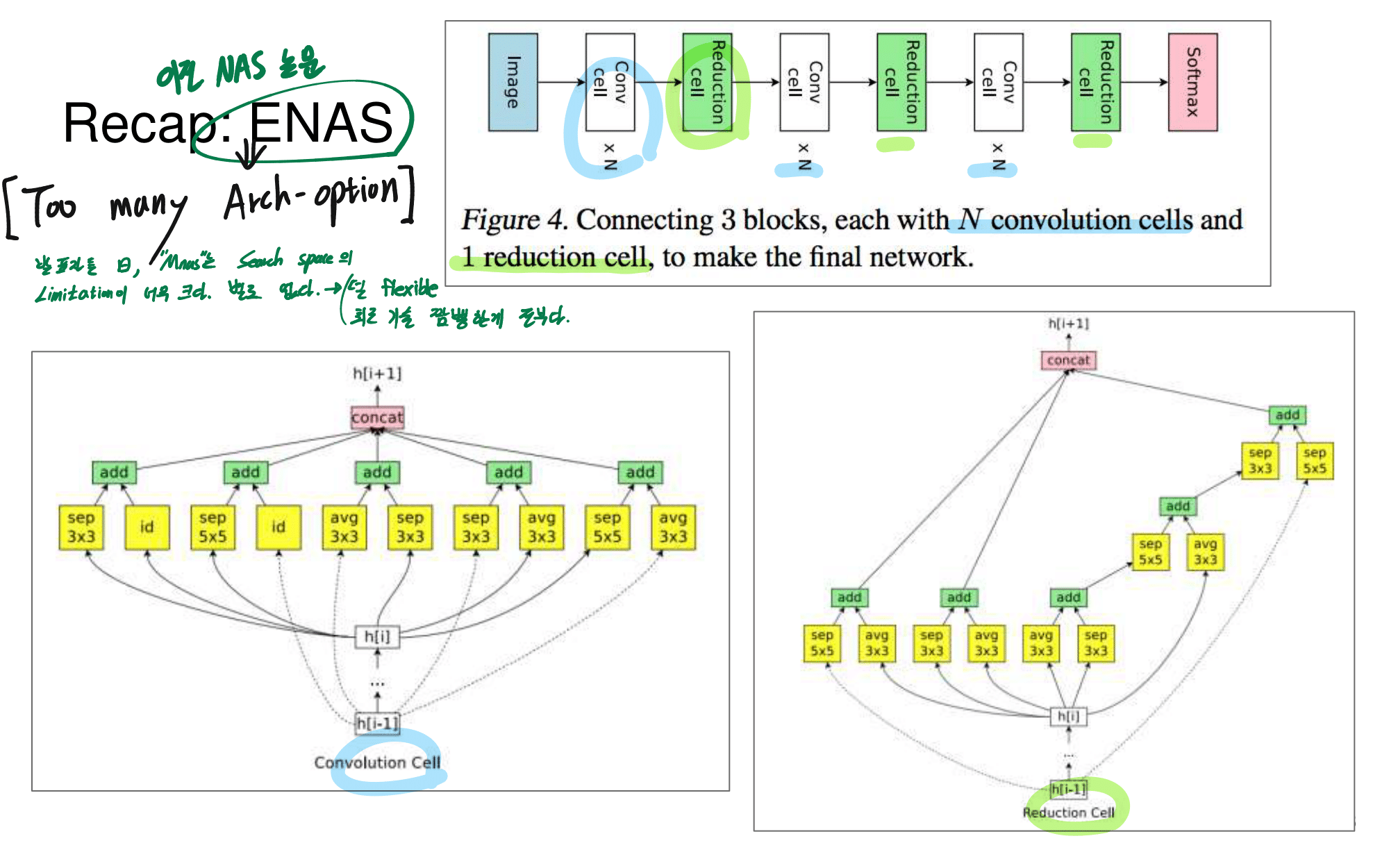


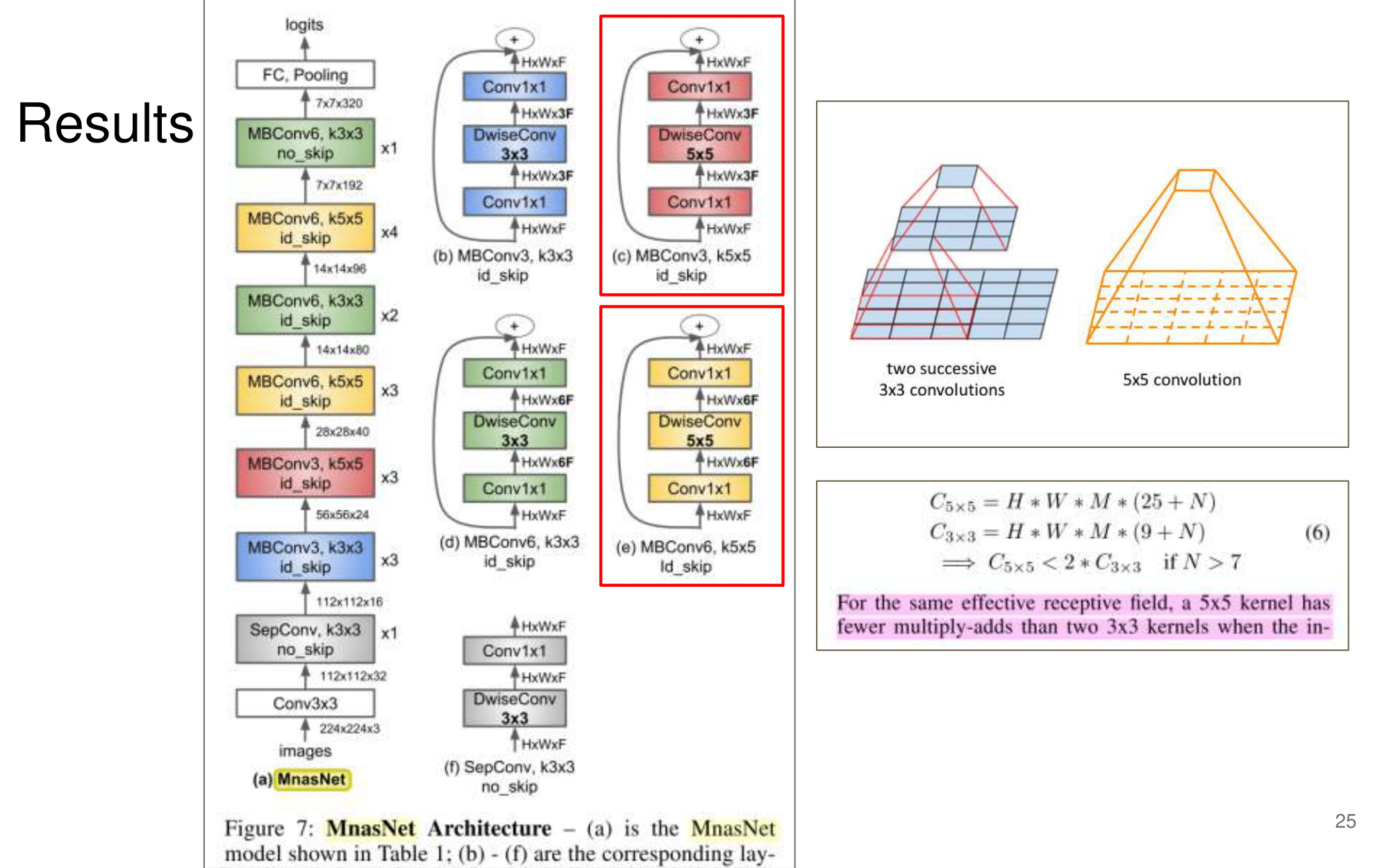
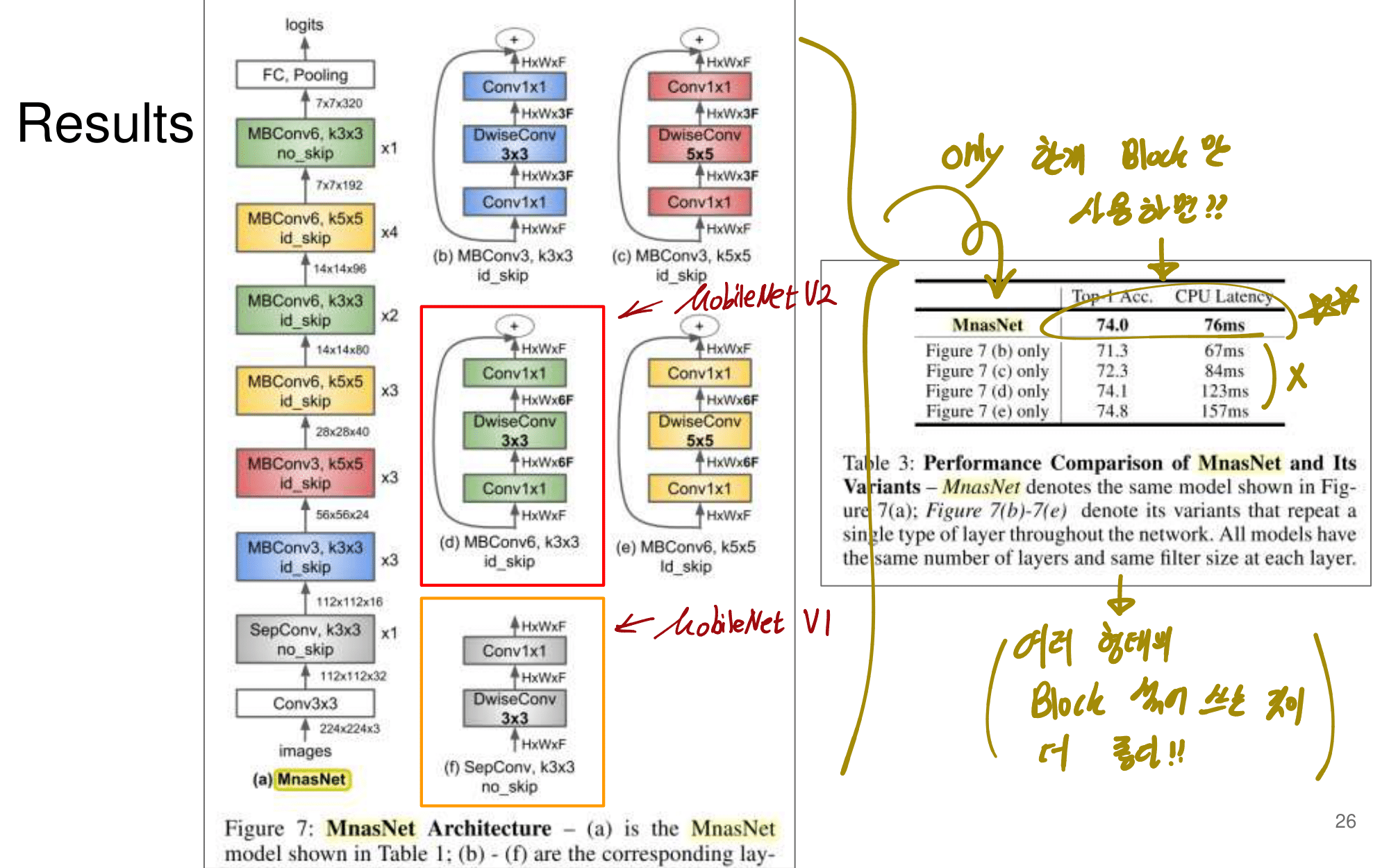
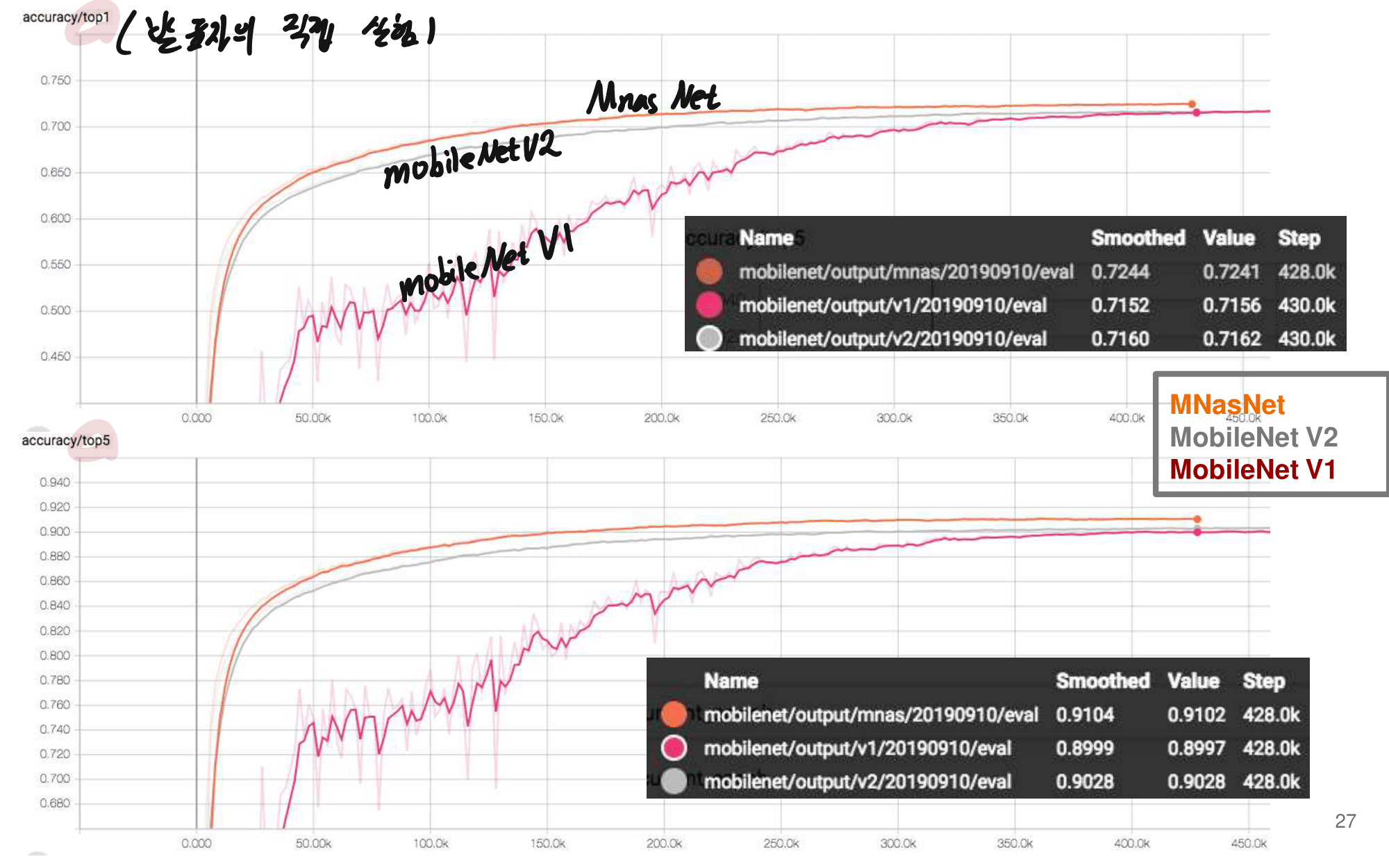
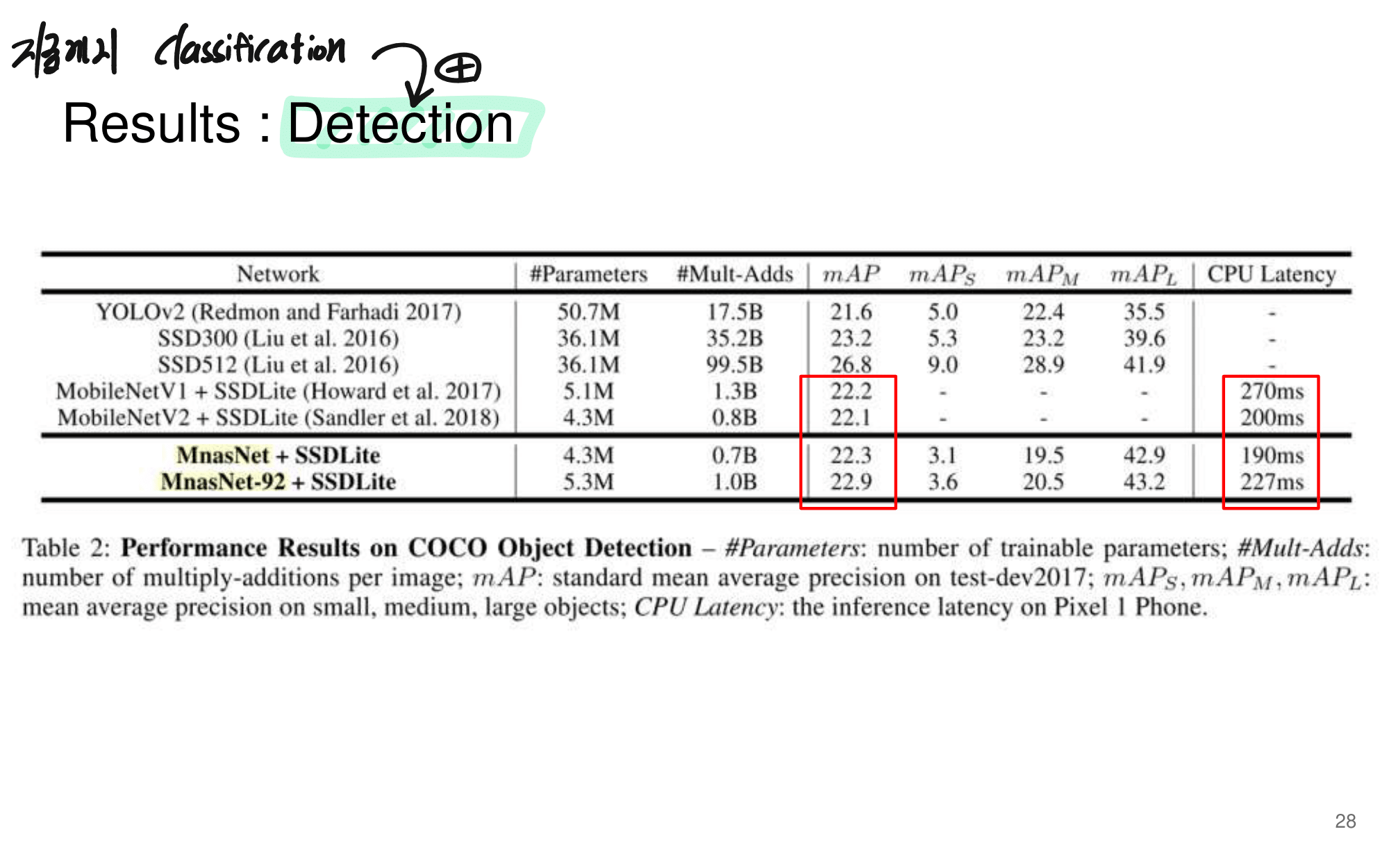
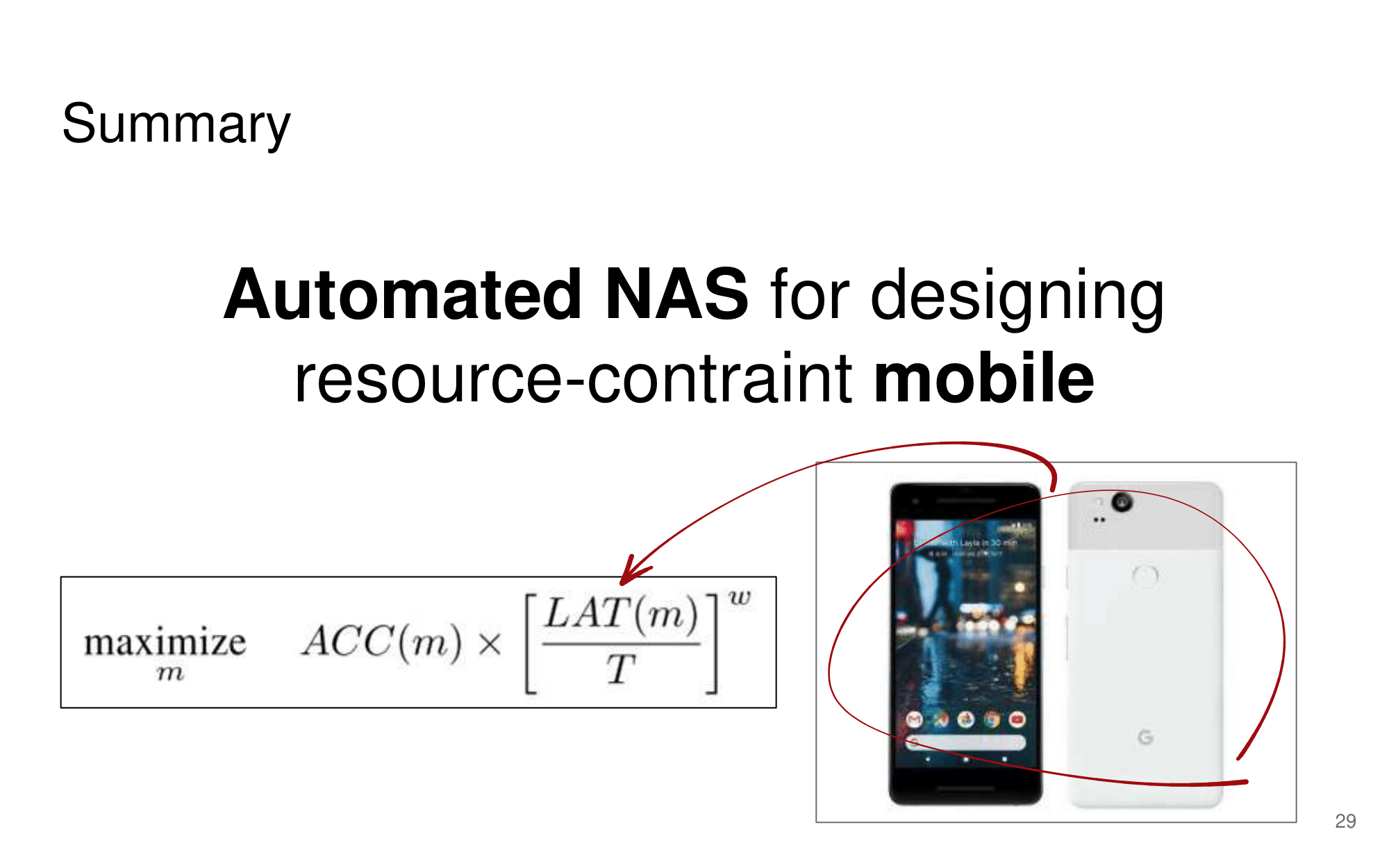

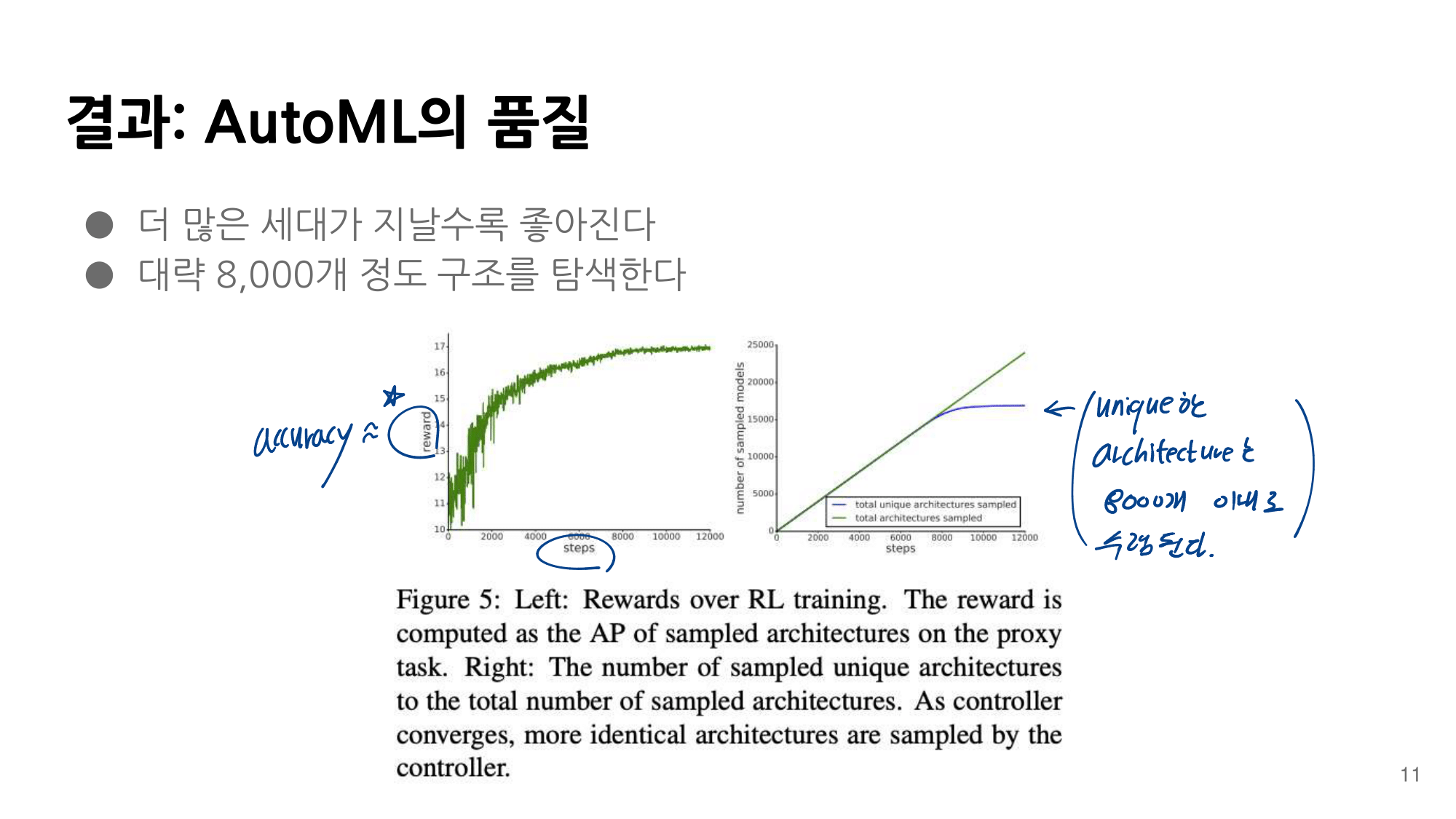
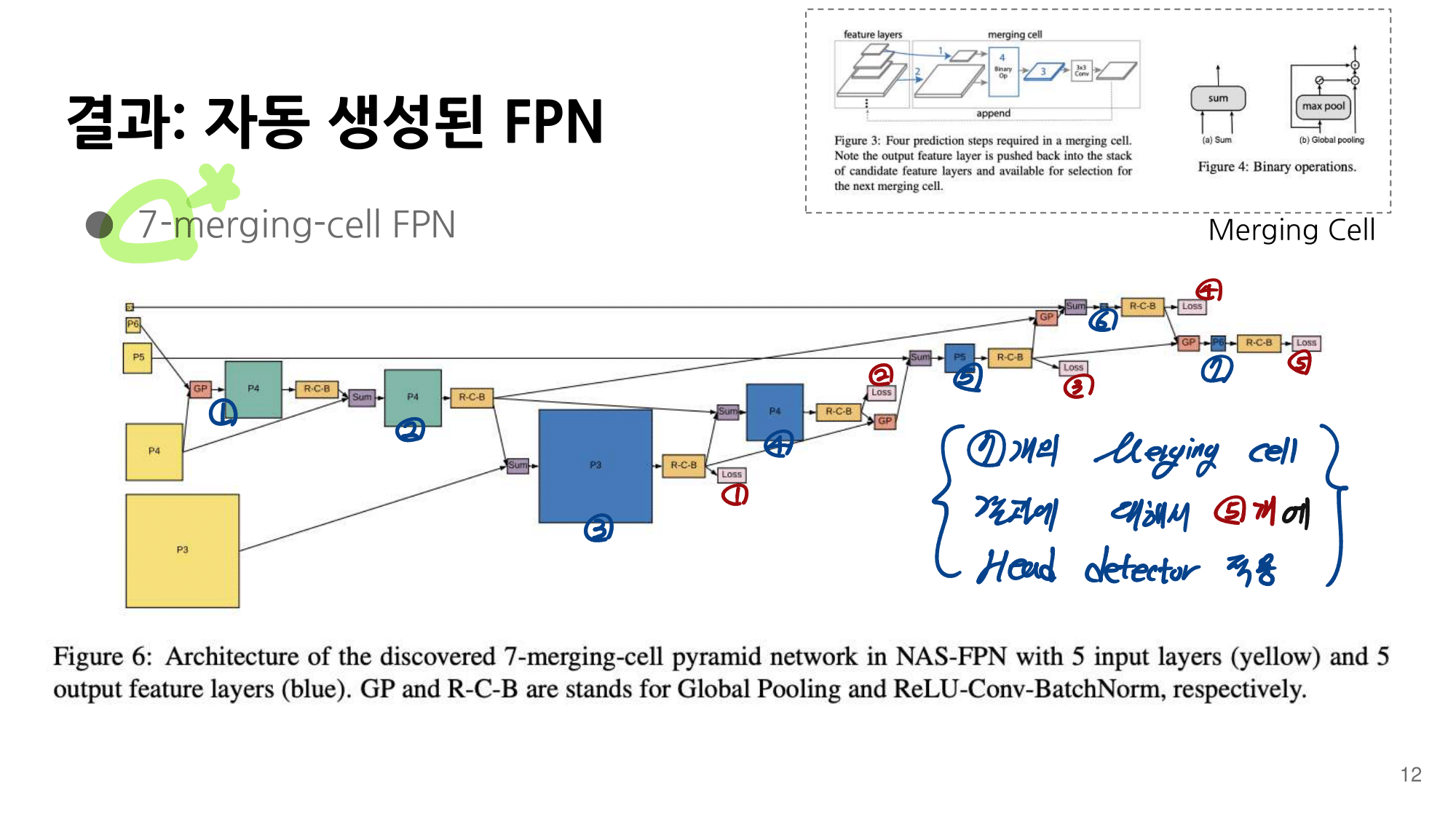
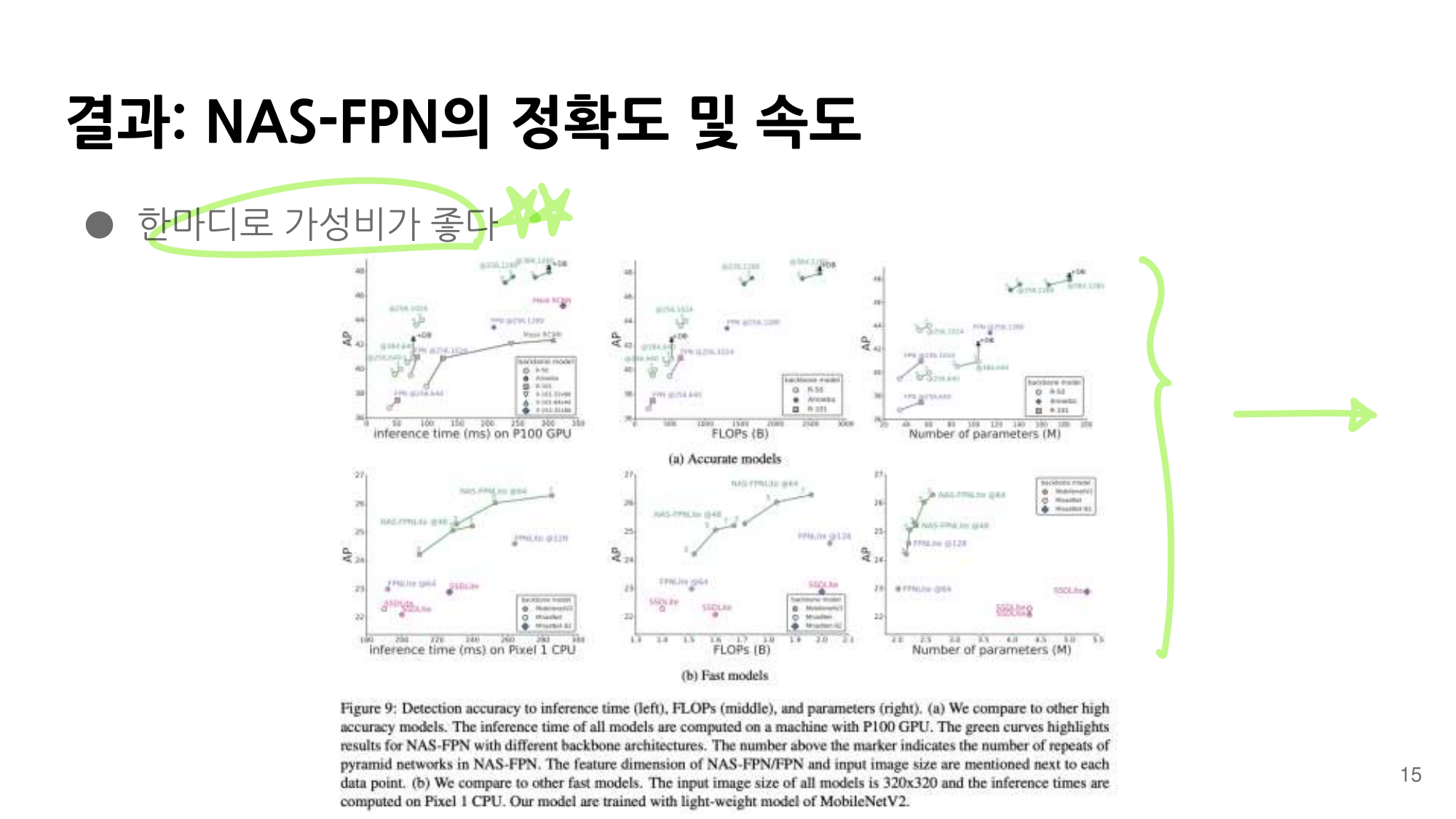
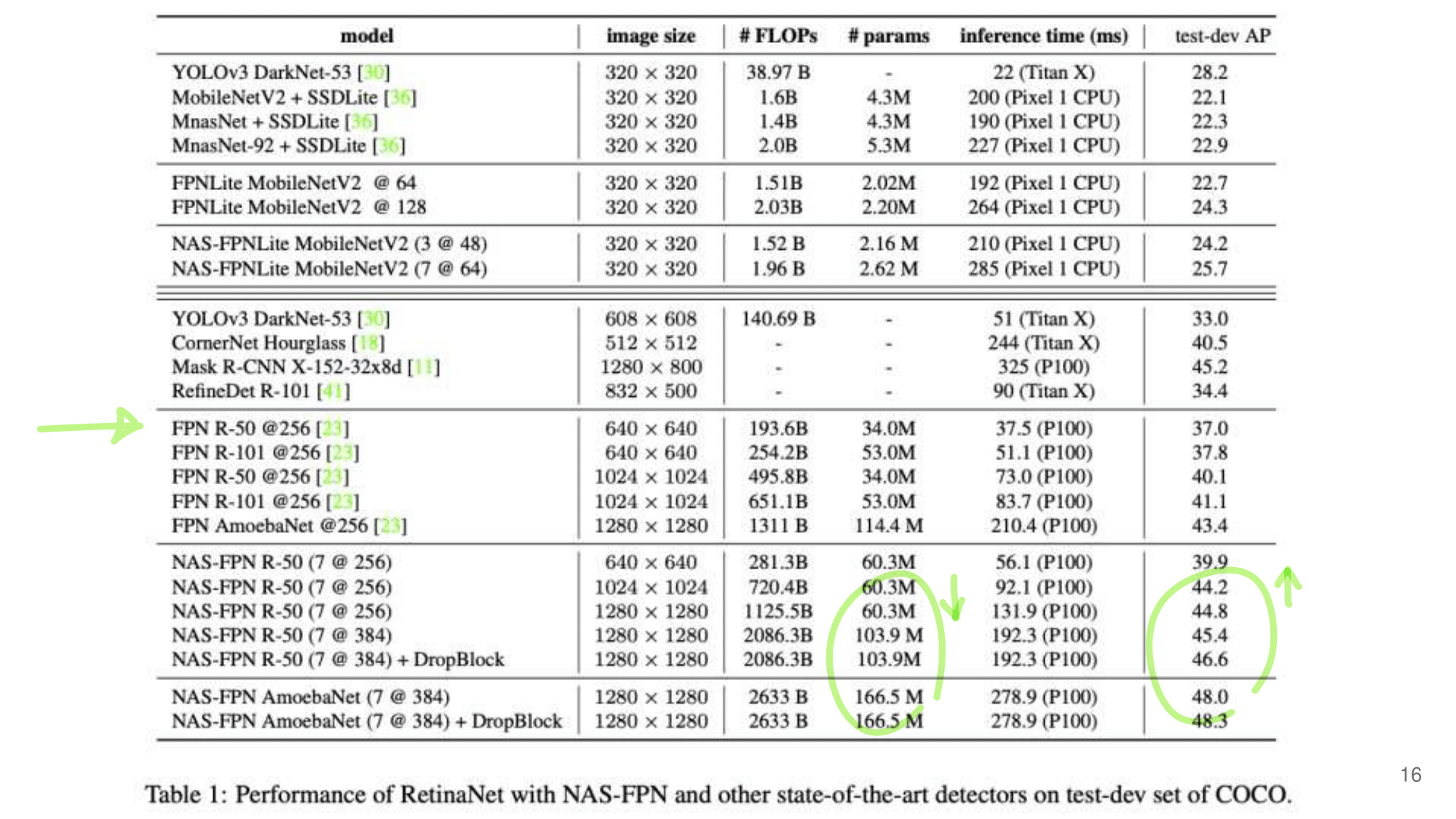
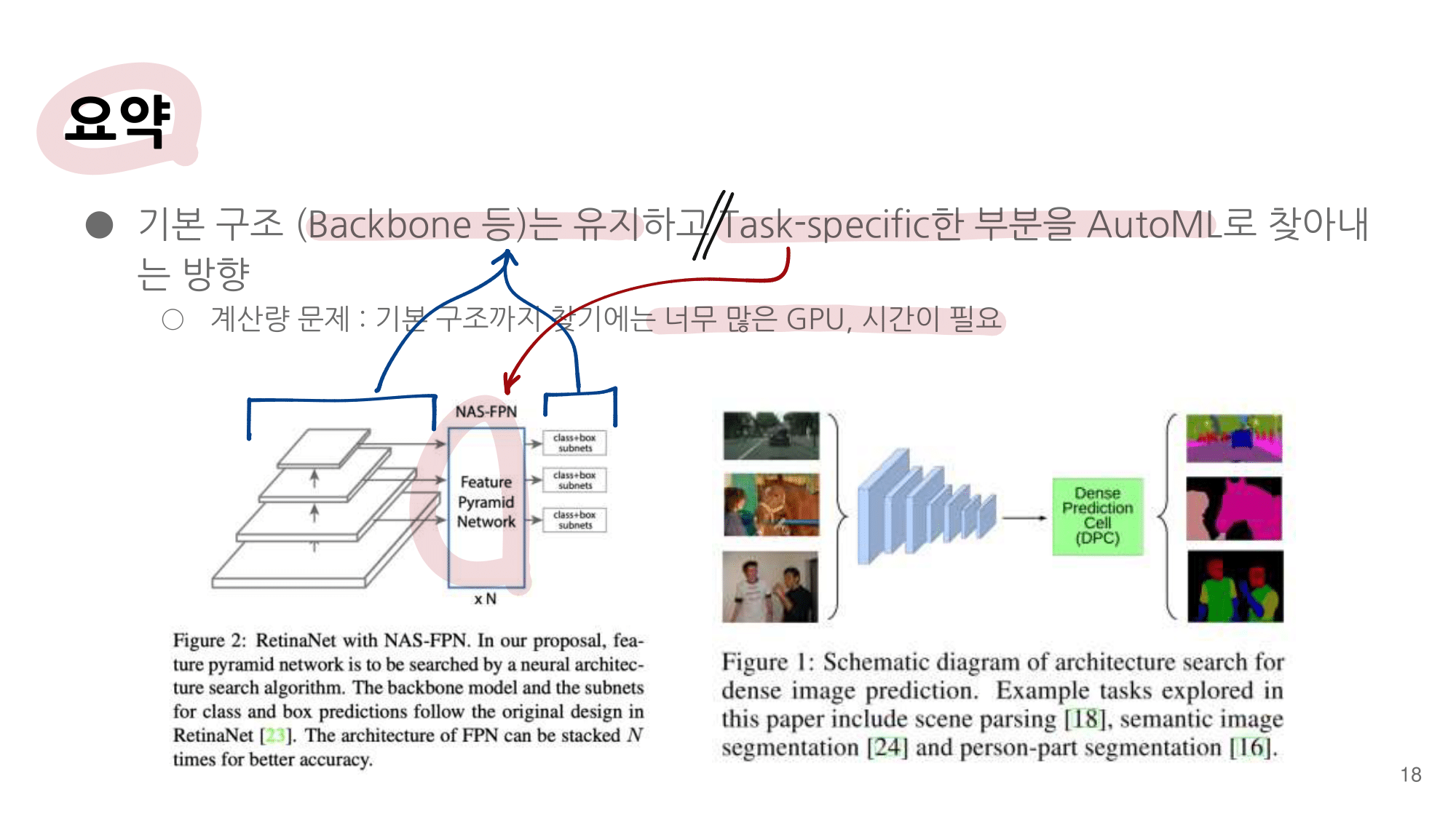
2. NAS-FPN from youtube
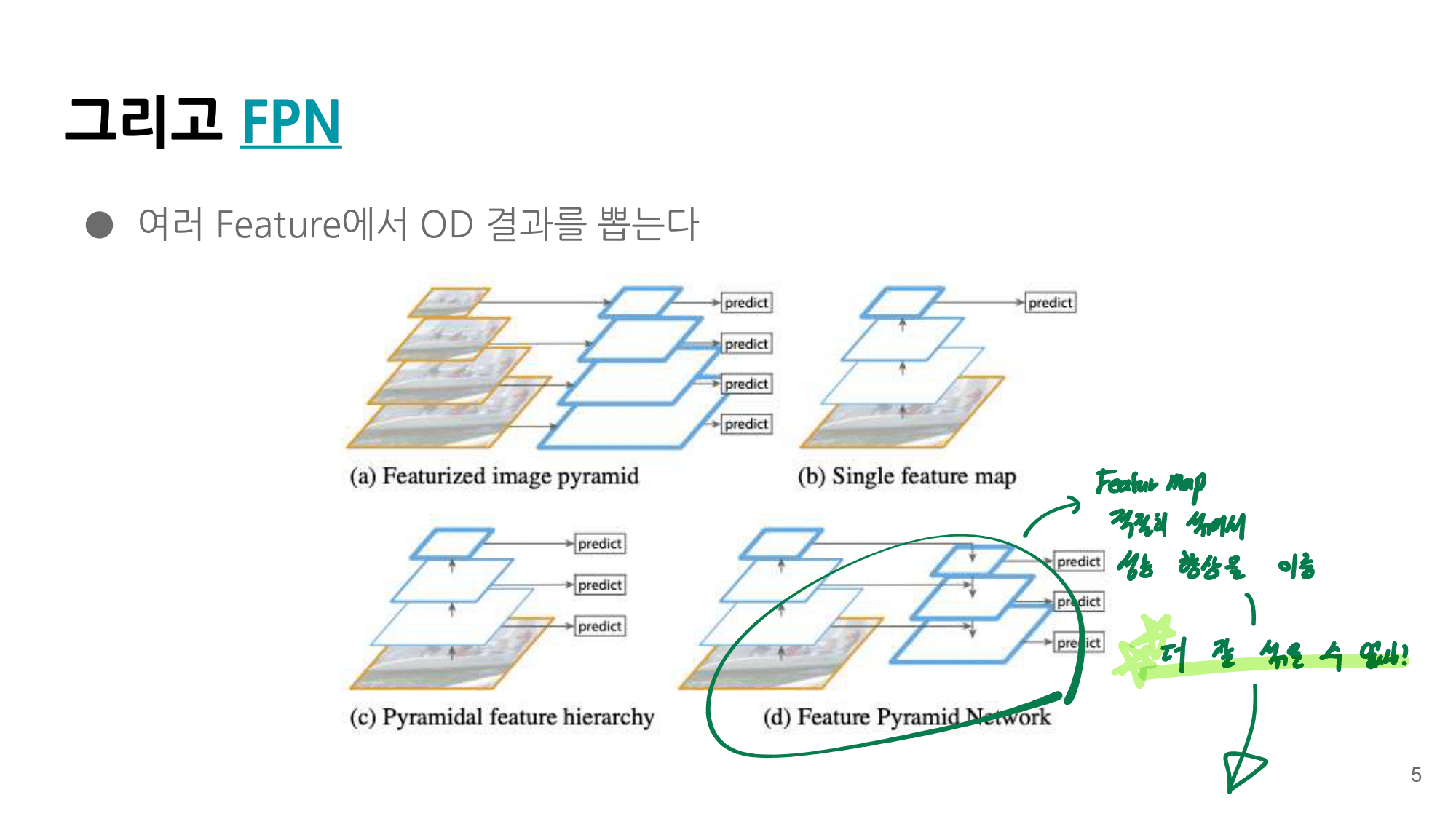
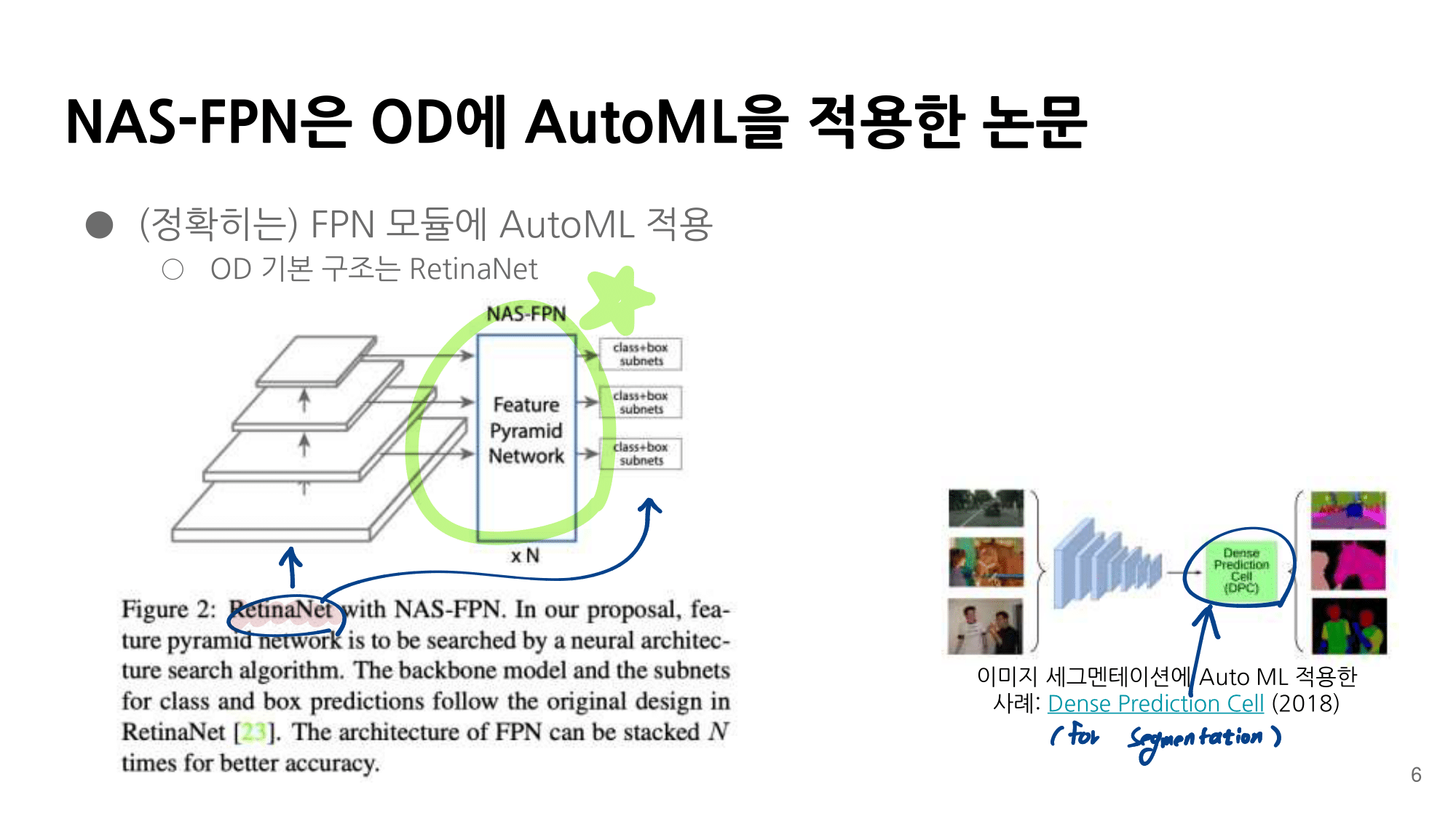
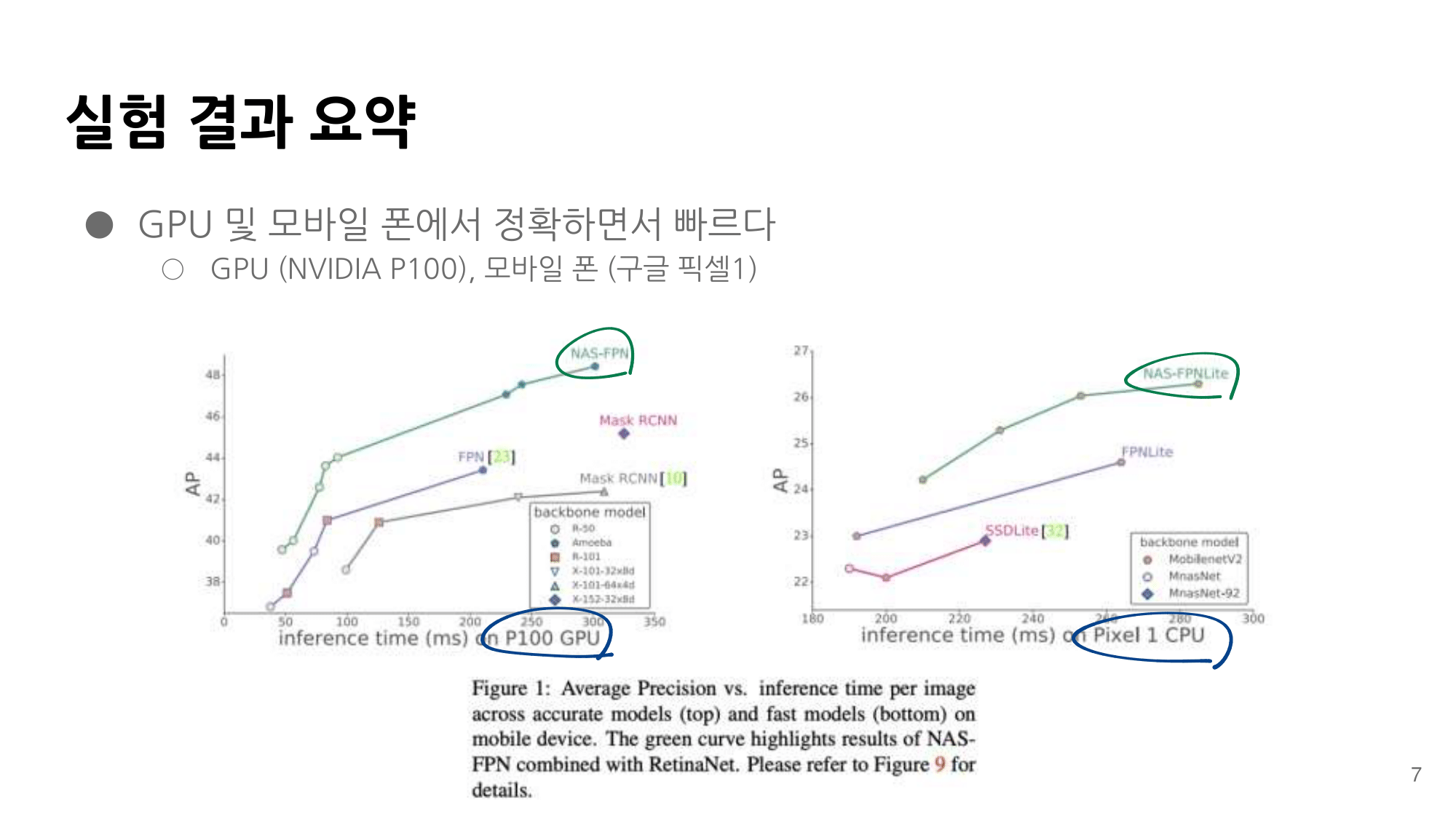
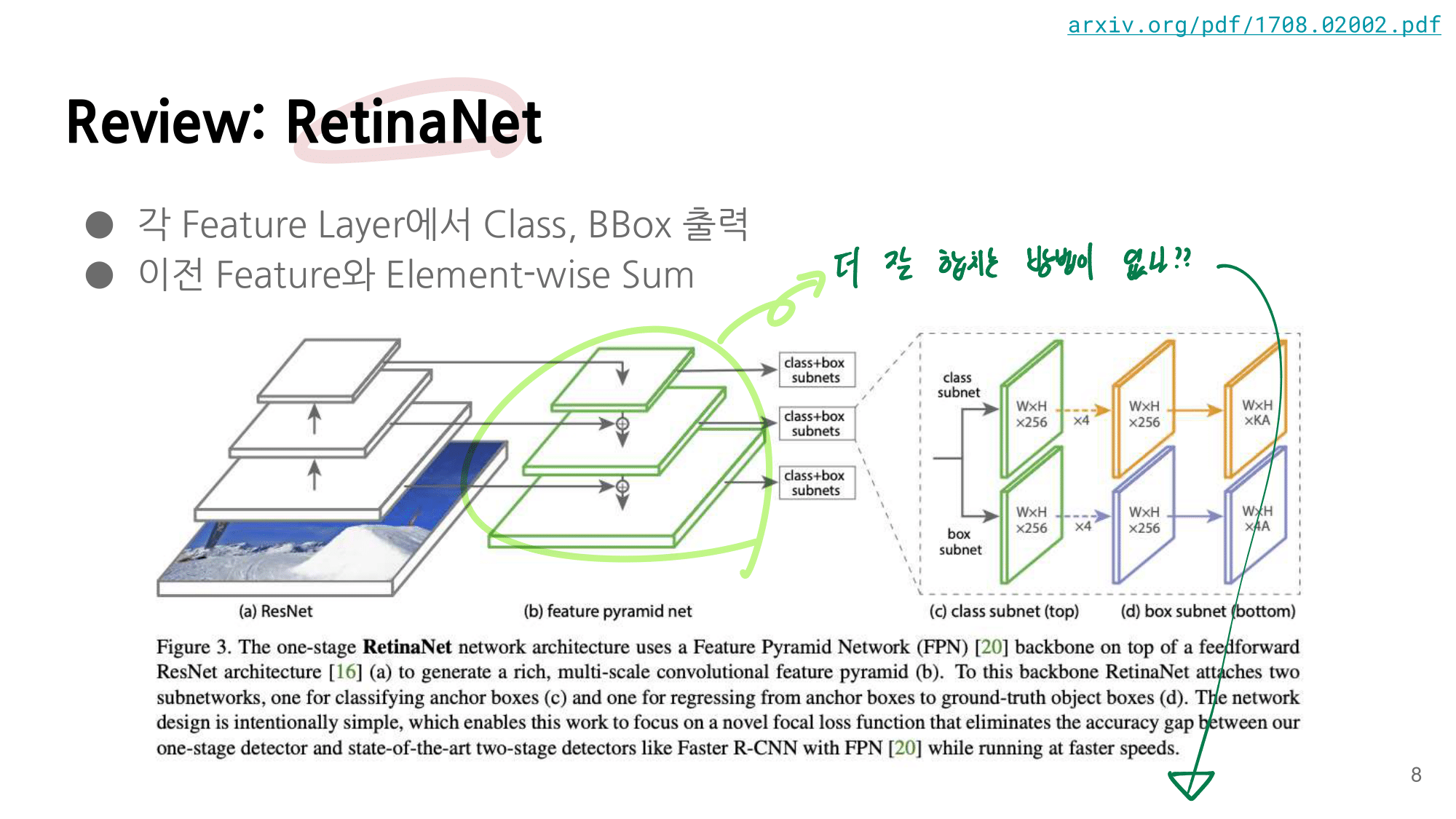
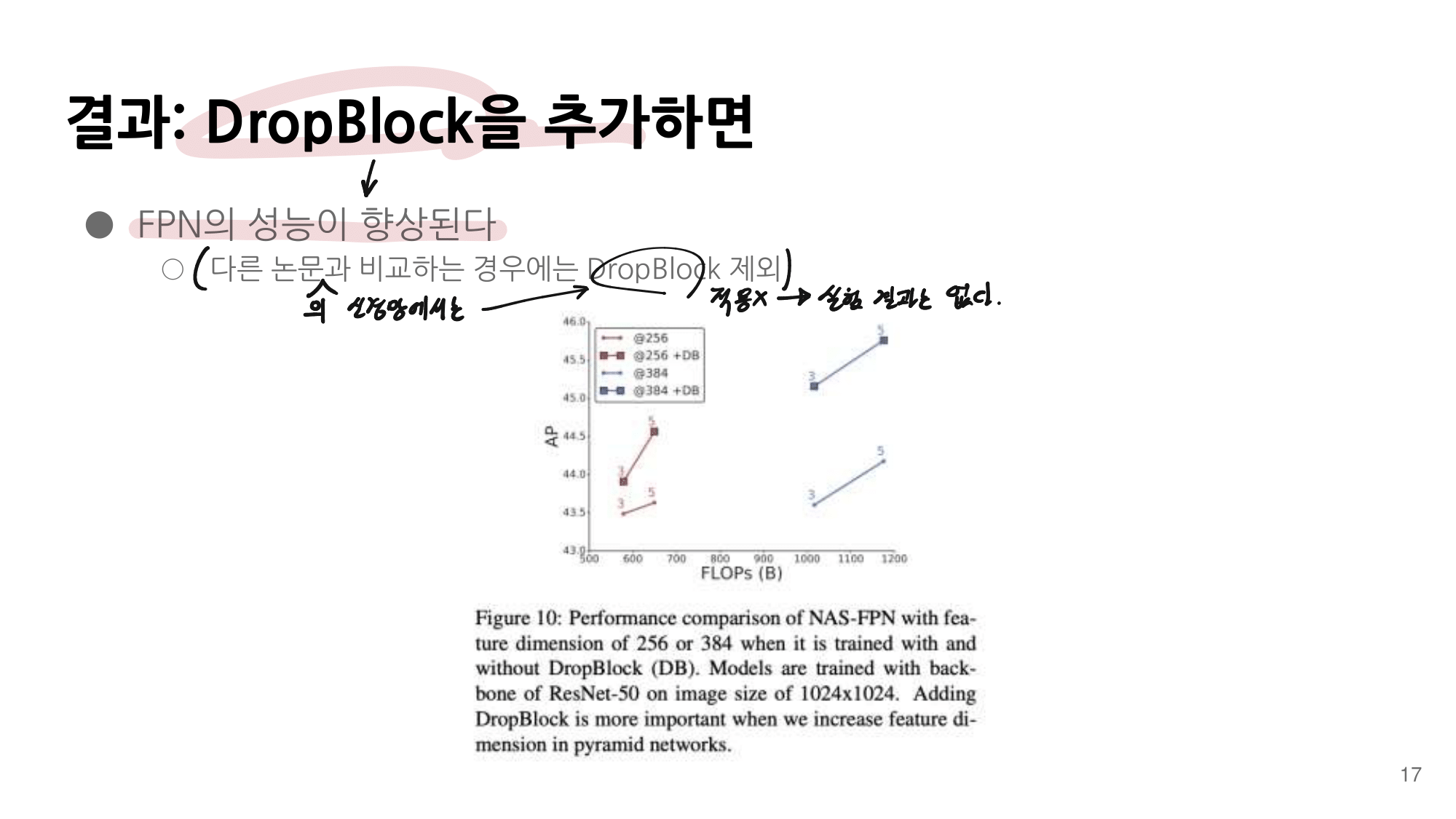
- 논문에 나오는 최종 모델 (아래 그림에서 (a) -> (f)는 모델의 발전 과정이다.)
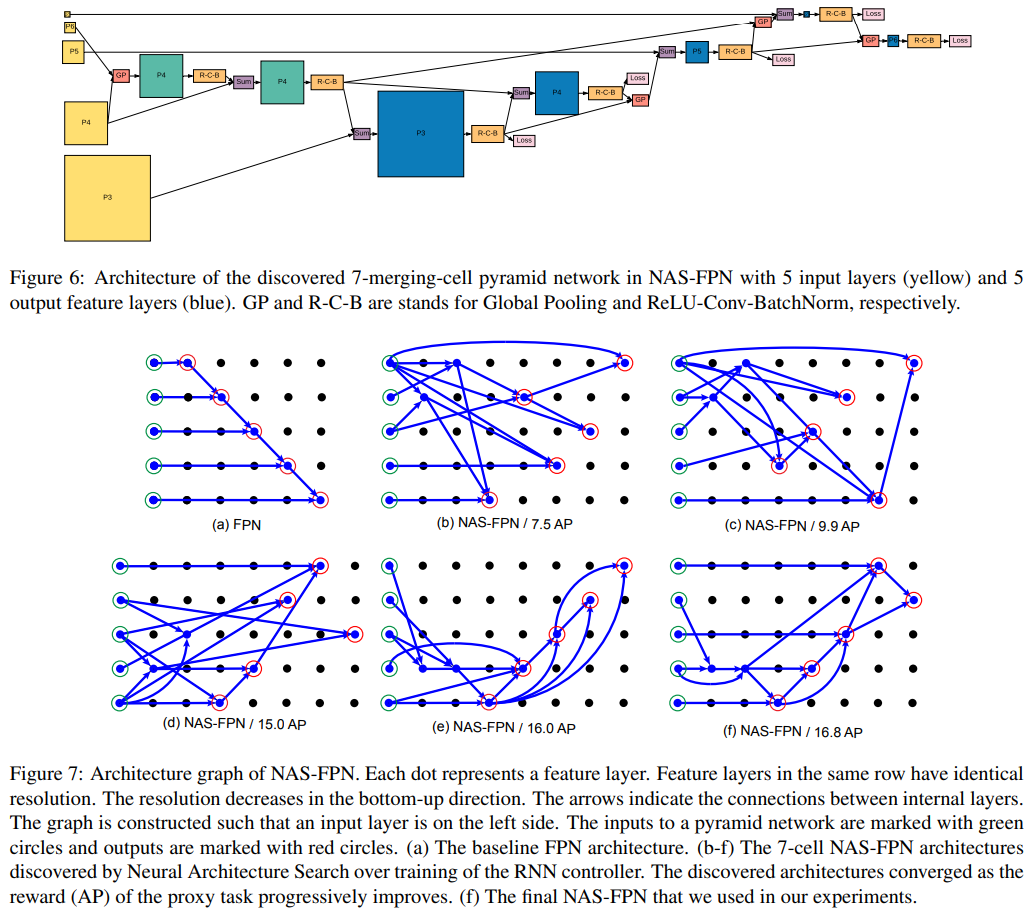
- 강의 필기 자료


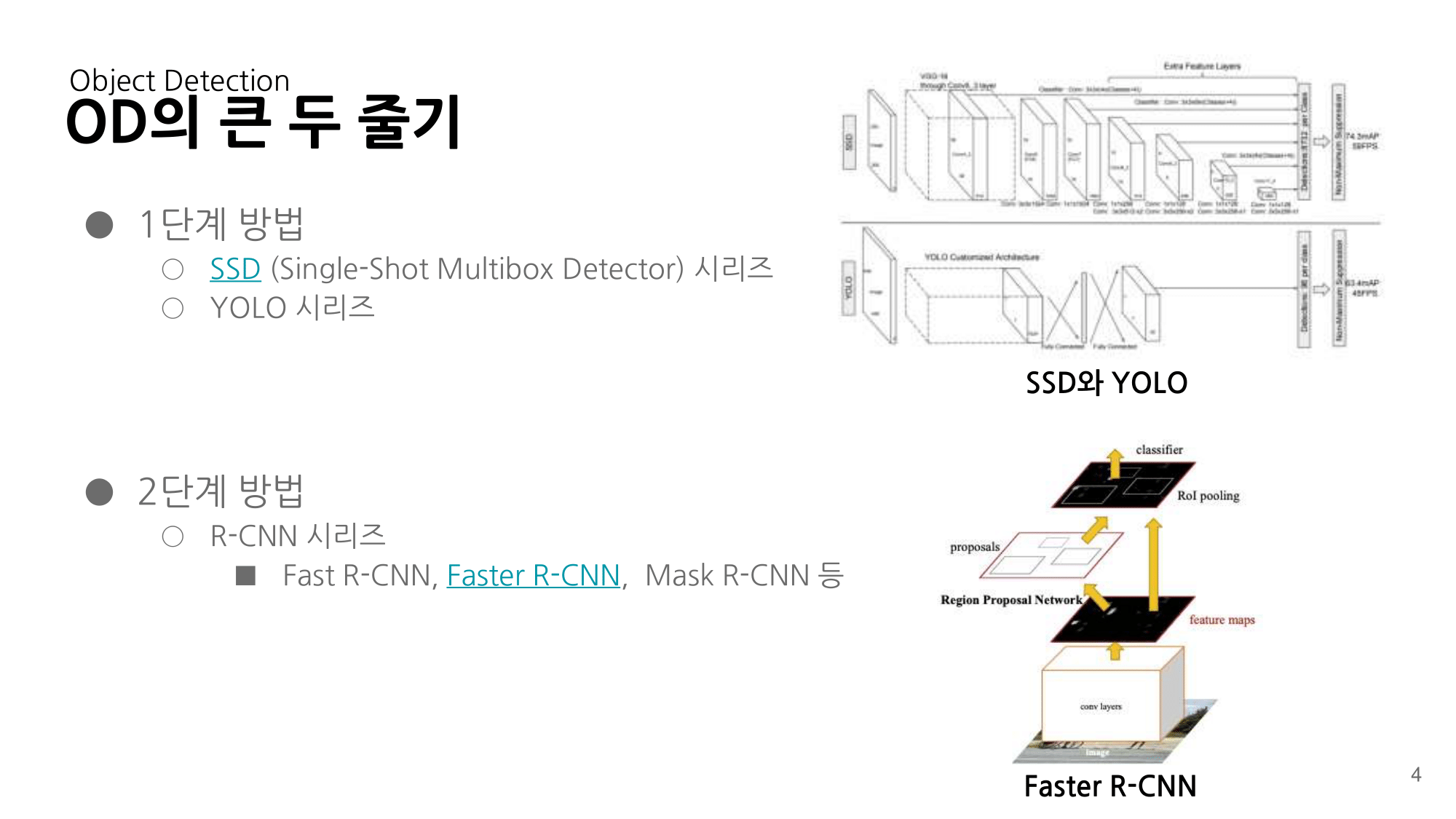




3. code - MnasNet-PyTorch
- Github1 - AnjieCheng/MnasNet-PyTorch <- MnasNet.py 파일 1개만 있다.
- Github2- Cadene/pretrained-models.pytorch <- NASNet 뿐만 아니라, Backbone으로 사용하기 좋은 pretrained-model들이 다앙햐게 있다.
# MnasNet.py
class MnasNet(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MnasNet, self).__init__()
# setting of inverted residual blocks
self.interverted_residual_setting = [
# t, c, n, s, k
[3, 24, 3, 2, 3], # -> 56x56
[3, 40, 3, 2, 5], # -> 28x28
[6, 80, 3, 2, 5], # -> 14x14
[6, 96, 2, 1, 3], # -> 14x14
[6, 192, 4, 2, 5], # -> 7x7
[6, 320, 1, 1, 3], # -> 7x7
"""
t : expand_ratio(Channel 몇 배로 확장 후 축소)
c : output_channel
n : 같은 block 몇번 반복?
s : stride
k : kernel
"""
]
assert input_size % 32 == 0
input_channel = int(32 * width_mult)
self.last_channel = int(1280 * width_mult) if width_mult > 1.0 else 1280
# building first two layer
# 여기서 Conv_3x3, SepConv_3x3 함수는 nn.Sequential( ... )를 return 하는 함수이다.
self.features = [Conv_3x3(3, input_channel, 2), SepConv_3x3(input_channel, 16)]
input_channel = 16
# building inverted residual blocks (MBConv)
for t, c, n, s, k in self.interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(InvertedResidual(input_channel, output_channel, s, t, k))
else:
self.features.append(InvertedResidual(input_channel, output_channel, 1, t, k))
input_channel = output_channel
# building last several layers
self.features.append(Conv_1x1(input_channel, self.last_channel))
self.features.append(nn.AdaptiveAvgPool2d(1))
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(-1, self.last_channel)
x = self.classifier(x)
return x