[Note] Hot papers in March 2023
HotPapers_Mar23
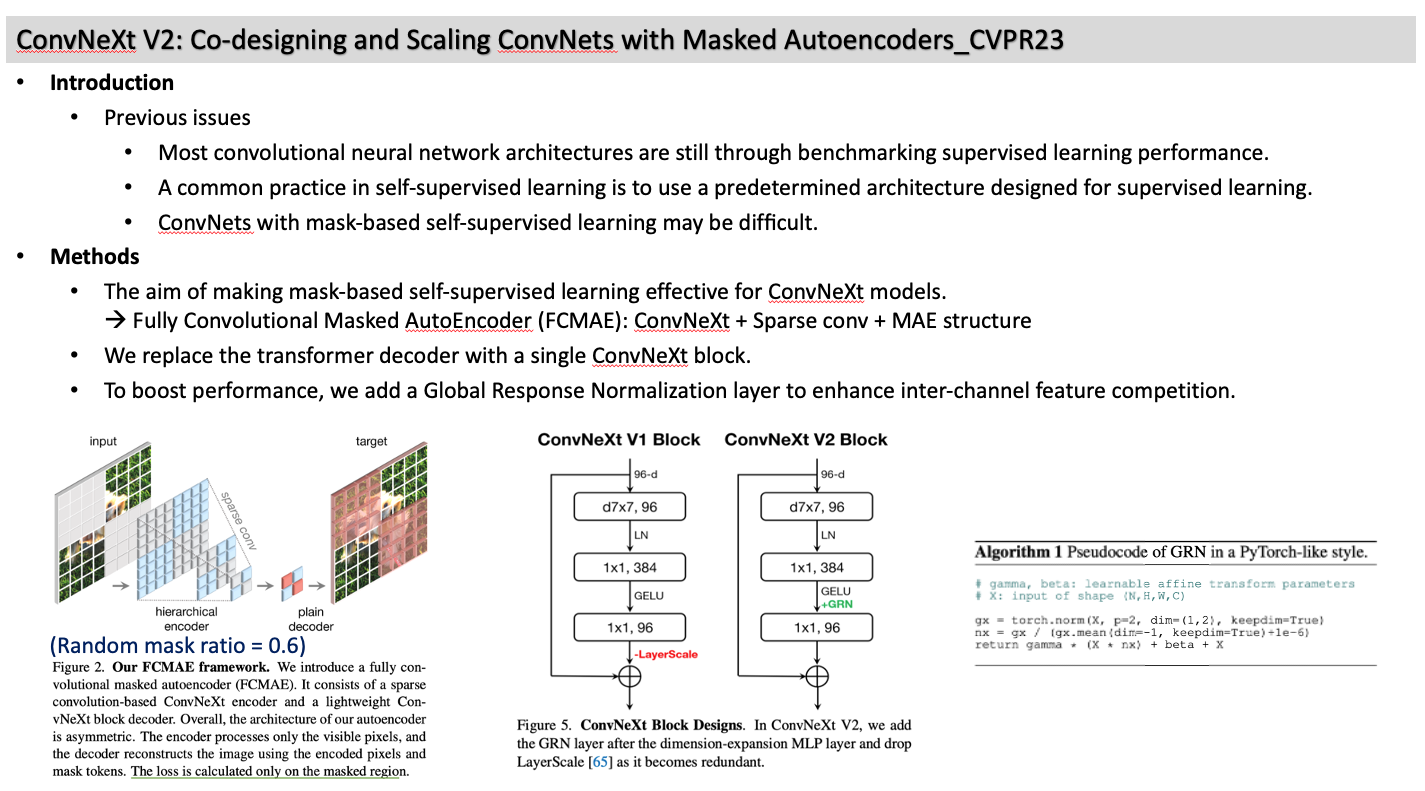
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders_CVPR23
- Introduction
- Previous issues
- Most convolutional neural network architectures are still through benchmarking supervised learning performance.
- A common practice in self-supervised learning is to use a predetermined architecture designed for supervised learning.
- ConvNets with mask-based self-supervised learning may be difficult.
- Methods
- The aim of making mask-based self-supervised learning effective for ConvNeXt models. Fully Convolutional Masked AutoEncoder (FCMAE): ConvNeXt + Sparse conv + MAE structure
- We replace the transformer decoder with a single ConvNeXt block.
- To boost performance, we add a Global Response Normalization layer to enhance inter-channel feature competition.
- Tables
- Table1: MAE decoder ablation experiments
- Table2: GRN ablations
- Table4: Comparison with previous MAE approaches
- Table4: ImageNet-1K
- Table4: COCO object detection & Instance segmentation
- Table4: ADE20K semantic segmentation

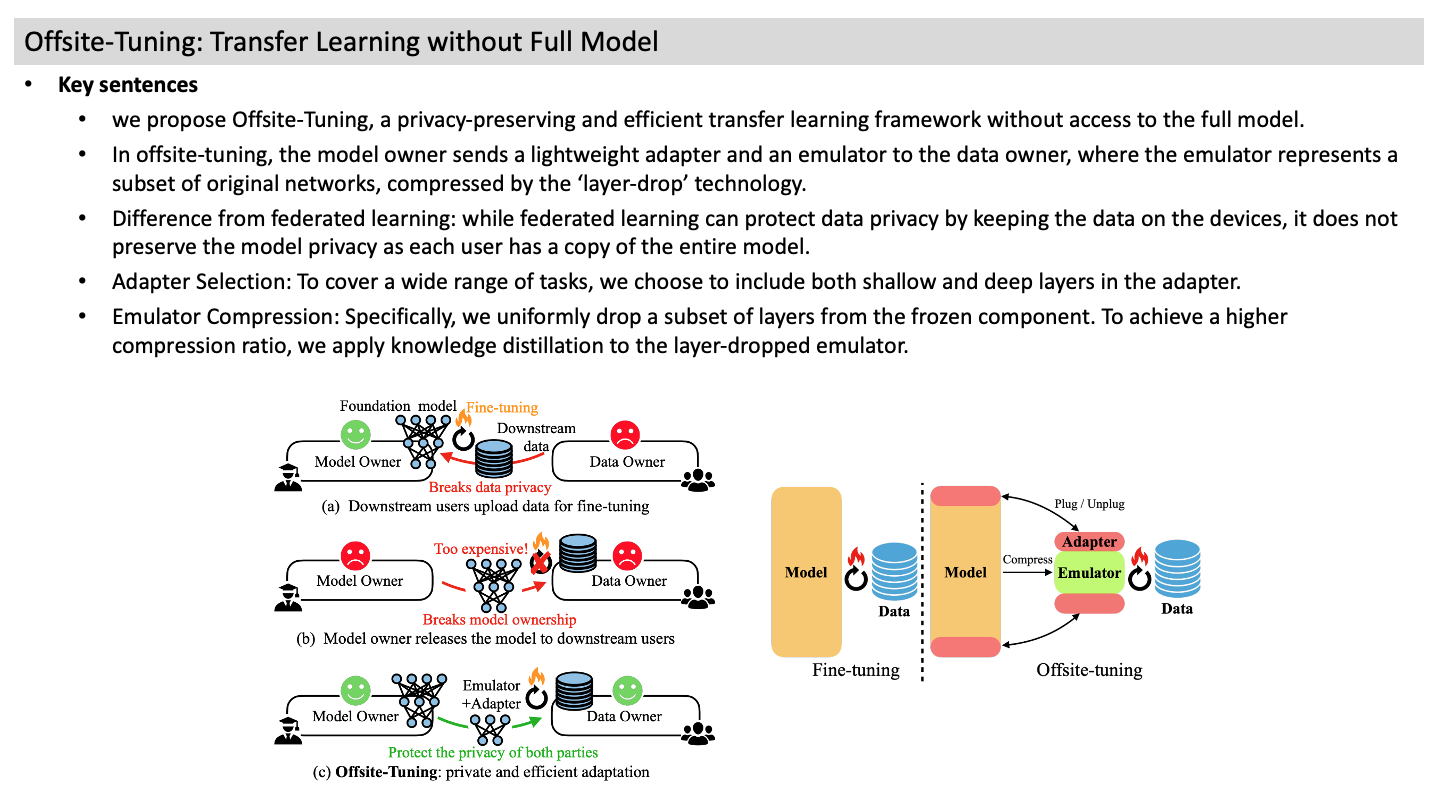
Offsite-Tuning: Transfer Learning without Full Model
- Key sentences
- we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework without access to the full model.
- In offsite-tuning, the model owner sends a lightweight adapter and an emulator to the data owner, where the emulator represents a subset of original networks, compressed by the ‘layer-drop’ technology.
- Difference from federated learning: while federated learning can protect data privacy by keeping the data on the devices, it does not preserve the model privacy as each user has a copy of the entire model.
- Adapter Selection: To cover a wide range of tasks, we choose to include both shallow and deep layers in the adapter.
- Emulator Compression: Specifically, we uniformly drop a subset of layers from the frozen component. To achieve a higher compression ratio, we apply knowledge distillation to the layer-dropped emulator.
The Forward-Forward Algorithm: Some Preliminary Investigations, Geoffrey Hinton, 2022
- Introduction
- Learning without ever storing activities or stopping to propagate derivatives.
- The perceptual system needs to perform inference and learning in real time without stopping to perform backpropagation.
- Method
- The Forward-Forward algorithm is inspired by Noise Contrastive Estimation.
- The positive pass operates on real data and adjusts the weights to increase the goodness in every hidden layer. The negative pass operates on "negative data" and adjusts the weights to decrease the goodness in every hidden layer.
- Drawback
- The forward-forward algorithm is somewhat slower than backpropagation and does not generalize quite as well on several of the toy problems investigated in this paper so it is unlikely to replace backpropagation for applications.
- The two areas in which the forward-forward algorithm may be superior to backpropagation are as a model of learning in cortex and as a way of making use of very low-power analog hardware without resorting to reinforcement learning (:= supervised learning).

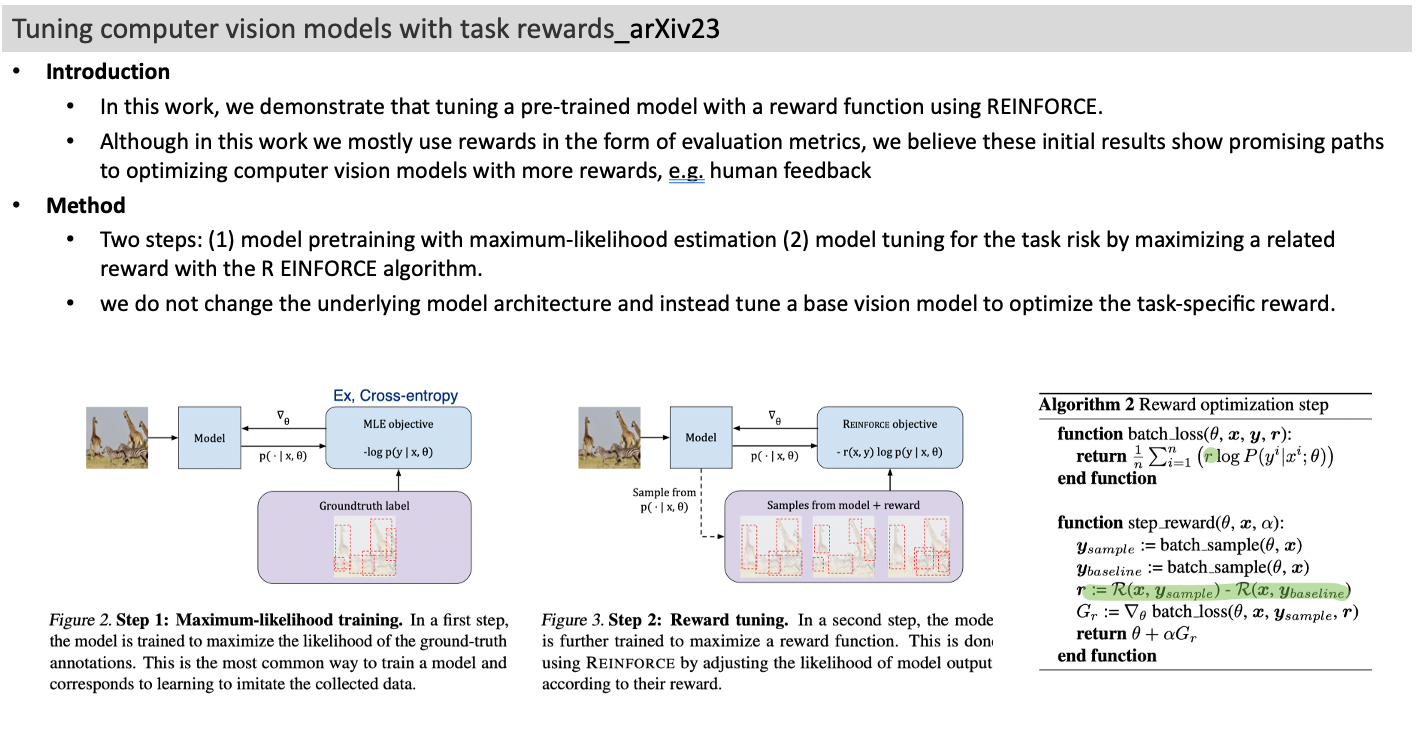
Tuning computer vision models with task rewards_arXiv23
- Introduction
- In this work, we demonstrate that tuning a pre-trained model with a reward function using REINFORCE.
- Although in this work we mostly use rewards in the form of evaluation metrics, we believe these initial results show promising paths to optimizing computer vision models with more rewards, e.g. human feedback
- Method
- Two steps: (1) model pretraining with maximum-likelihood estimation (2) model tuning for the task risk by maximizing a related reward with the R EINFORCE algorithm.
- we do not change the underlying model architecture and instead tune a base vision model to optimize the task-specific reward.
MIC- Masked Image Consistency for Context-Enhanced Domain Adaptation_arXiv23
- Introduction
- A common problem is the confusion of classes with a similar visual appearance on the target domain, such as road/sidewalk or pedestrian/rider.
- Therefore, we design a method to explicitly encourage the network to learn comprehensive context relations in the whole image.
- Method
- we propose to specifically encourage learning context relations on the target domain to provide additional clues for robust recognition of classes with similar local appearances.
- To train the network to use the remaining context clues, we let the model reconstruct the correct label without access to the entire image.
- Results
- Classes that most profits from MIC are sidewalk, fence, pole, traffic sign, terrain, and rider. These classes have a comparably low UDA performance, meaning that they are difficult to adapt. Here, context clues appear to play an important role in successful adaptation.
