[Note] Hot papers in April 2023
HotPapers_April9
1. PaLM-E: An Embodied Multimodal Language Model_Google Robotics_23
- Introduction
- We train embodied(=sensor modalities) language models end-to-end for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning.
- connecting those representations to real-world visual and physical sensor modalities is essential to solving a wider range of grounded real-world problems in computer vision and robotics.
- Method
- Inputs such as images and (3D) state estimates are embedded into the same latent embedding as language tokens. Specifically, PaLM-E represents images and text as “multimodal sentences” of latent vectors, allowing it to process multiple images in a flexible way within any part of a sentence.
- Q: What happened between <img 1> and <img 2>? where <img i> represents an embedding of an image, where ViT is used to map an image into a number of token embeddings.
- When PaLM-E is tasked with producing decisions or plans, we assume that there exists a low-level policy or planner that can translate these decisions into low-level actions.
- Results
- Our results indicate that multi-task (multimodal) training improves performance compared to training models on individual tasks.
- PaLM-E-562B can do zero-shot multimodal chain-of-thought reasoning. PaLM-E also generalizes, zero-shot, to multi-image prompts despite only being trained on single-image prompts.


2. Back Razor: Memory-Efficient Transfer Learning by Self-Sparsified Backpropagation_NeurIPS22
- Introduction
- Memory Efficient Transfer Learning.
- The assumption that freezing the weight W like TinyTL reduces the required memory size is broken by the emergence of ViT. Since the most operation of ViT would involve updating weights.
- Method
- Asymmetric sparsifying: Our method replaces it with a pruned activation which carries a lower memory cost. During the backward phase, the gradients are calculated with the approximated(= pruned) activation, but only with a small error between those with the exact(=whole) activation.
- Total memory cost for each layer is n/8 + lambdanc_type, where n, lambda, and c means the total number of tensors, pruning rate, and the count of bytes for each tensor. 1/8 is applied since it denotes bool type.
- Results
- Our method retains a similar convergence rate as vanilla SGD.
- Compared with FT-Full, Back Razor@90% use 8.7x times smaller memory while achieving comparable performance.

- SA-1B Dataset
- Total number of images: 11M / There are no class labels for the images or mask annotations
- Largest ever segmentation dataset
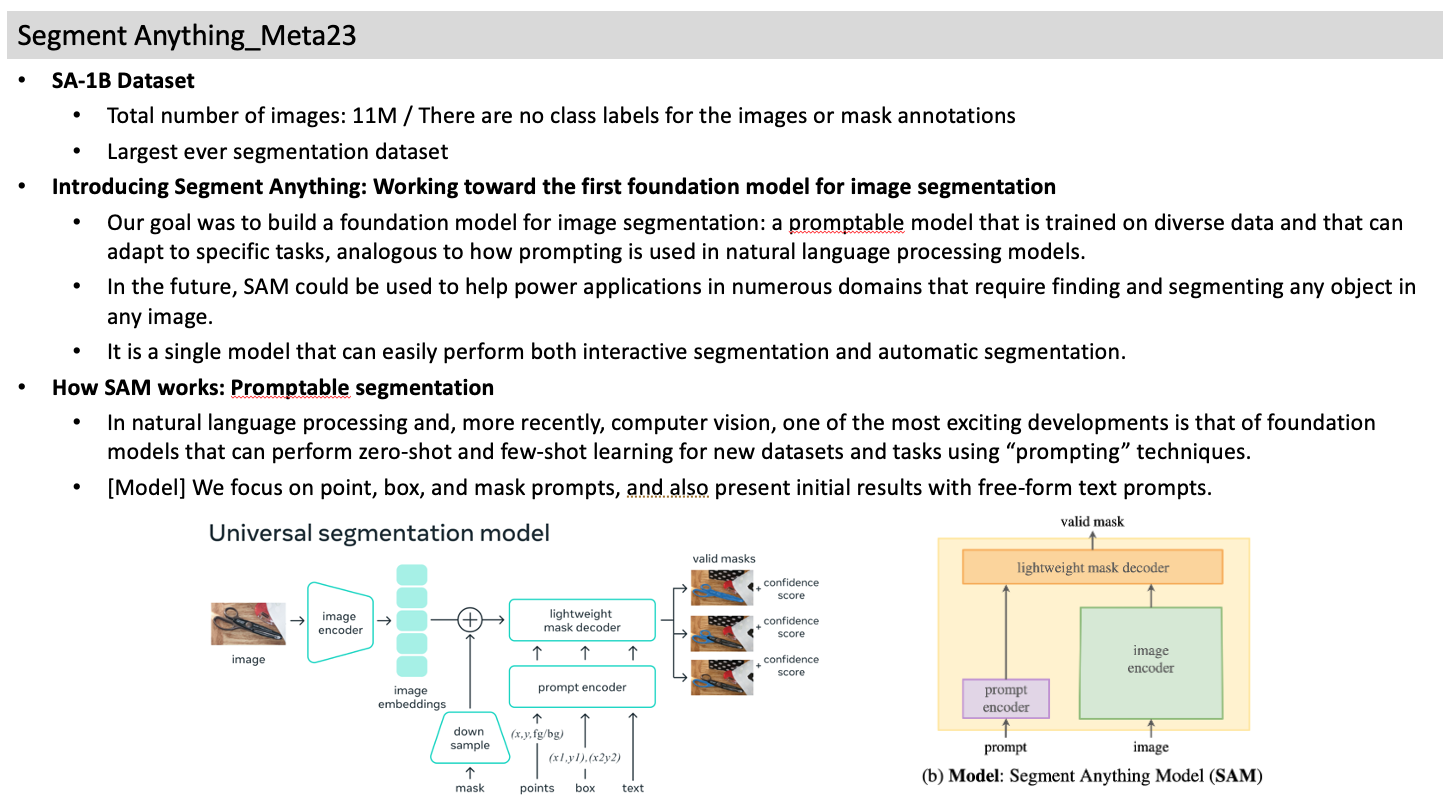
- Introducing Segment Anything: Working toward the first foundation model for image segmentation
- Our goal was to build a foundation model for image segmentation: a promptable model that is trained on diverse data and that can adapt to specific tasks, analogous to how prompting is used in natural language processing models.
- In the future, SAM could be used to help power applications in numerous domains that require finding and segmenting any object in any image.
- It is a single model that can easily perform both interactive segmentation and automatic segmentation.
- How SAM works: Promptable segmentation
- In natural language processing and, more recently, computer vision, one of the most exciting developments is that of foundation models that can perform zero-shot and few-shot learning for new datasets and tasks using “prompting” techniques.
- [Model] We focus on point, box, and mask prompts, and also present initial results with free-form text prompts.
4. LORA: Low-rank adaptation of large language models_Microsoft21
- Motivation
- When adapting to a specific task, Aghajanyan et al. (2020) shows that the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace. Inspired by this, we hypothesize the updates to the weights also have a low “intrinsic rank” during adaptation.
- Method
- We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
- Example code for convolution layer

5. Language-driven Semantic Segmentation_ICLR22
- Introduction
- Semantic segmentation assumes a limited set of semantic class labels. Few-shot approaches still require labeled data that includes the novel classes. / Zero-shot methods (experimental setup) generate related features between seen and unseen classes without the need for additional annotations. (open-set recognition)
- Language-driven classification > CLIP / Language-driven object detection > ViLD, MDETR
- We can transfer the flexibility of the text encoder to the visual recognition module.
- Method
- During training, we encourage the image encoder to provide pixel embeddings that are close to the text embedding of the corresponding ground-truth class. Given the text embeddings and the image embedding, we aim to maximize the dot product.
- Loss = A pixel-wise softmax objective over the whole image + A per-pixel softmax with cross-entropy loss
- The upsampling module should be no interactions between the input channels, so it (named, BottleneckBlock or Spatial regularization blocks) consists of depthwise convolutions.
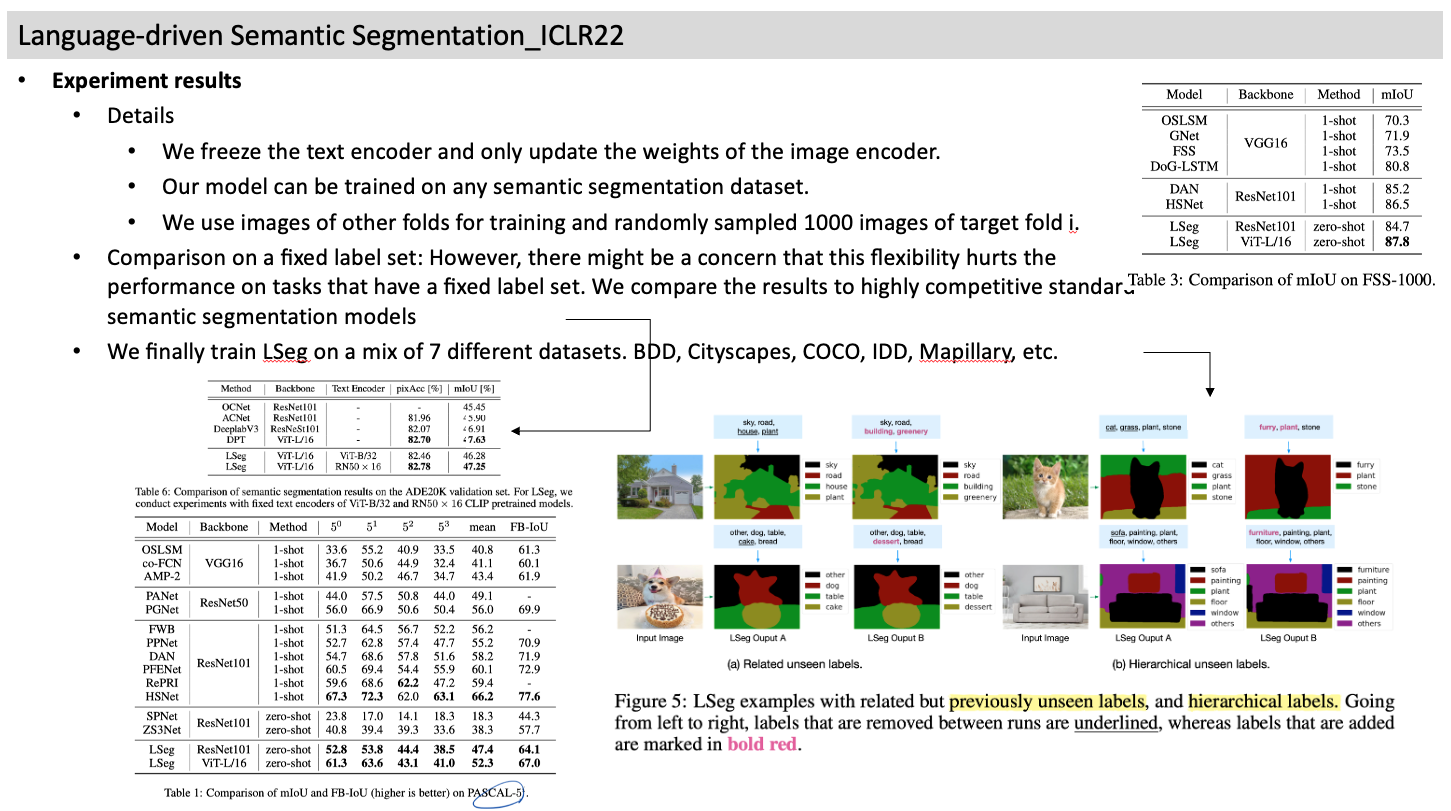
- Experiment results
- Details
- We freeze the text encoder and only update the weights of the image encoder.
- Our model can be trained on any semantic segmentation dataset.
- We use images of other folds for training and randomly sampled 1000 images of target fold i.
- We train with a batch size of 6 on six Quadro RTX 6000.
- Comparison on a fixed label set: However, there might be a concern that this flexibility hurts the performance on tasks that have a fixed label set. We compare the results to highly competitive standard semantic segmentation models
- We finally train LSeg on a mix of 7 different datasets. BDD, Cityscapes, COCO, IDD, Mapillary, etc.

6. Scaling Down to Scale Up- A Guide to Parameter-Efficient Fine-Tuning_arXiv23
- Motivation
- In-context learning (Radford et al., 2019) thus became the new normal, the standard way to pass downstream task training data to billion-scale language models.
- Parameter-efficient fine-tuning, which we denote as PEFT, aims to resolve this problem by only training a small set of parameters.
- Most parameter-efficient fine-tuning methods for Transformers only rely on the basic MHA + FFN structure.
- Taxonomy
- Additive methods: [Adapters] extra parameters or layers [Prompts] control the behavior of a model by modifying the input text.
- Selective methods: Sparse parameter updates present multiple engineering and efficiency challenges.
- Reparametrization: Reparametrization-based parameter-efficient fine-tuning methods leverage low-rank representations.
- Notable works
- Ladder-Side Tuning (LST): trains a small transformer network on the side of the pre-trained network.
- LoRa: Parameter update for a weight matrix in LoRa is decomposed into a product of two low-rank matricies.
- KronA: matrix factorization through a Kronecker product.
- Compacter: utilizes Kronecker product, low-rank matrices, and parameter sharing across layers to produce adapter weights.
- Issues and discussions.
- LoRa and Compacter, these implementations (official code) stand out for their user-friendliness and adaptability.
- As a community, we need to prioritize code that is easy to understand and features simple, reusable implementations.
- However, in practice, matching the performance of full fine-tuning remains a challenge. One of the reasons is high sensitivity to hyperparameters, with optimal hyperparameters often significantly deviating from those used in full fine-tuning due to the varying number of trainable parameters.
- A possible future direction of finding new PEFT models is exploring different reparametrization techniques.
- In many respects, our current situation resembles the challenges from edge machine learning: we consistently face constraints in memory, computation, and even energy consumption.

7. LST- Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning_NeruIPS22
- Motivation
- Parameter-efficient transfer learning (PETL) techniques, they only reduce the training memory requirement by up to 30%.
- Method
- We train a ladder side network, a small and separate network that takes intermediate activations as input via shortcut connections (called ladders).
- (c) our LST does not add trainable parameters inside the pre-trained model, and this completely eliminates the need for expensive backpropagation of a large backbone network and saves substantial memory during transfer learning.
- Results
- LST saves 69% of the memory costs. Moreover, LST achieves higher accuracy.

8. MOAT- Alternating Mobile Convolution and Attention Brings Strong Vision Models_ICLR23
- Motivation
- Previous works (Mobile ViT and CoAtNet) only stack MBConv blocks (inverted residual blocks) and Transformer blocks.
- We taking a deeper look at the combination of MBConv and Transformer blocks. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block.
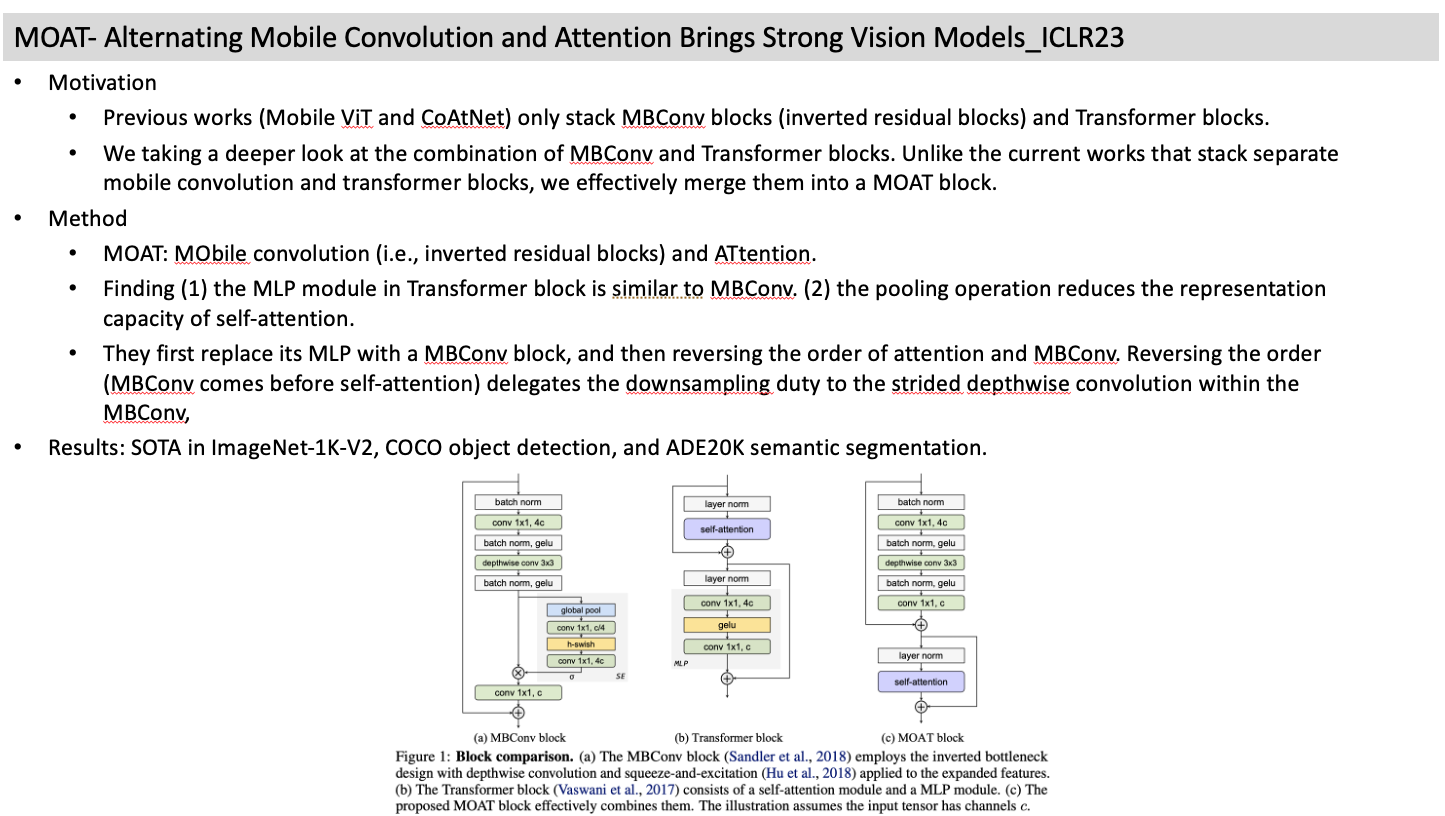
- Method
- MOAT: MObile convolution (i.e., inverted residual blocks) and ATtention.
- Finding (1) the MLP module in Transformer block is similar to MBConv. (2) the pooling operation reduces the representation capacity of self-attention.
- They first replace its MLP with a MBConv block, and then reversing the order of attention and MBConv. Reversing the order (MBConv comes before self-attention) delegates the downsampling duty to the strided depthwise convolution within the MBConv,
- Results: SOTA in ImageNet-1K-V2, COCO object detection, and ADE20K semantic segmentation.
9. Others
- Visual Prompt Tuning for Test-time Domain Adaptation arXiv22
- TTA + Transformer + Training prompts
- Visual prompt tuning ECCV22
- Visual Prompt Based Personalized Federated Learning arXiv23
- Unmasked Teacher: Towards Training-Efficient Video Foundation Models arXiv23
- To increase data efficiency, we mask out most of the low-semantics video tokens.
- Image masking:=> row resolution image
- AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition NeurIPS22
- LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
- Images Speak in Images: A Generalist Painter for In-Context Visual Learning CVPR23
- Painter is a generalist vision model, which can automatically perform vision tasks according to the input task prompts without the task specific heads.
- In-context learning, as a new paradigm in NLP, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples.
- Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
- LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning_ NeurIPS
