[SSL] Papers for semi-supervised learning 2
0630_SSL2
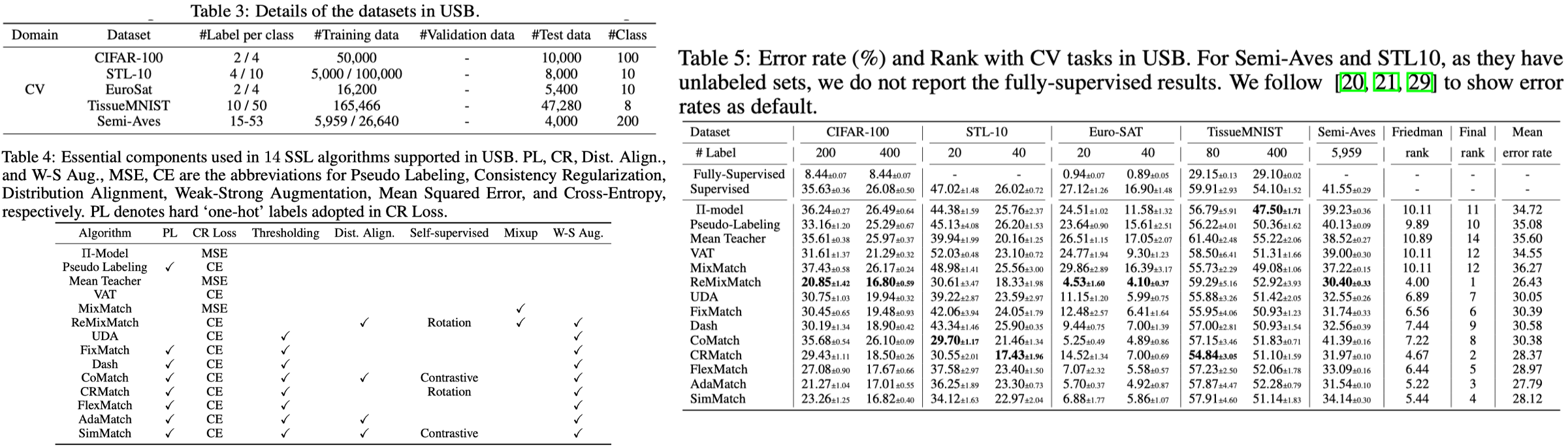
9. USB- A Unified Semi-supervised Learning Benchmark for Classification. NeurIPS, 2022.
- Contributions
- We further provide the pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning.
- Dataset: See Table 3. (PS, CIFAR-10 and SVHN in TorchSSL are not included in USB because the state-of-the-art SSL algorithms have achieved similar performance on these datasets to fully-supervised training with abundant fully labeled training data)
- Algorithm: See Table 4
- Experimental setup
- We follow [21] to report the best number of all checkpoints.
- We adopt the pre-trained Vision Transformers (ViT) [4, 34, 30, 71] instead of training ResNets from scratch for CV tasks.
- Results and Findings
- The pre-trained ViT, SSL algorithms, even without using thresholding techniques, often achieve much better performance. Notice that SSL algorithms with self-supervised feature loss generally perform well than other SSL algorithms.
- Since TissueMNIST is a medial-related dataset, the biased pseudo-labels might produce a destructive effect. The de-biasing of pseudo-labels and safe semi-supervised learning would be interesting topics in future work.
- Limitations
- Moreover, it is of great importance to extend current SSL to distributional shift settings, such as domain adaptation, etc.
- we hope that our finding can serve as the motivation to delve into deep learning based robust SSL methods.
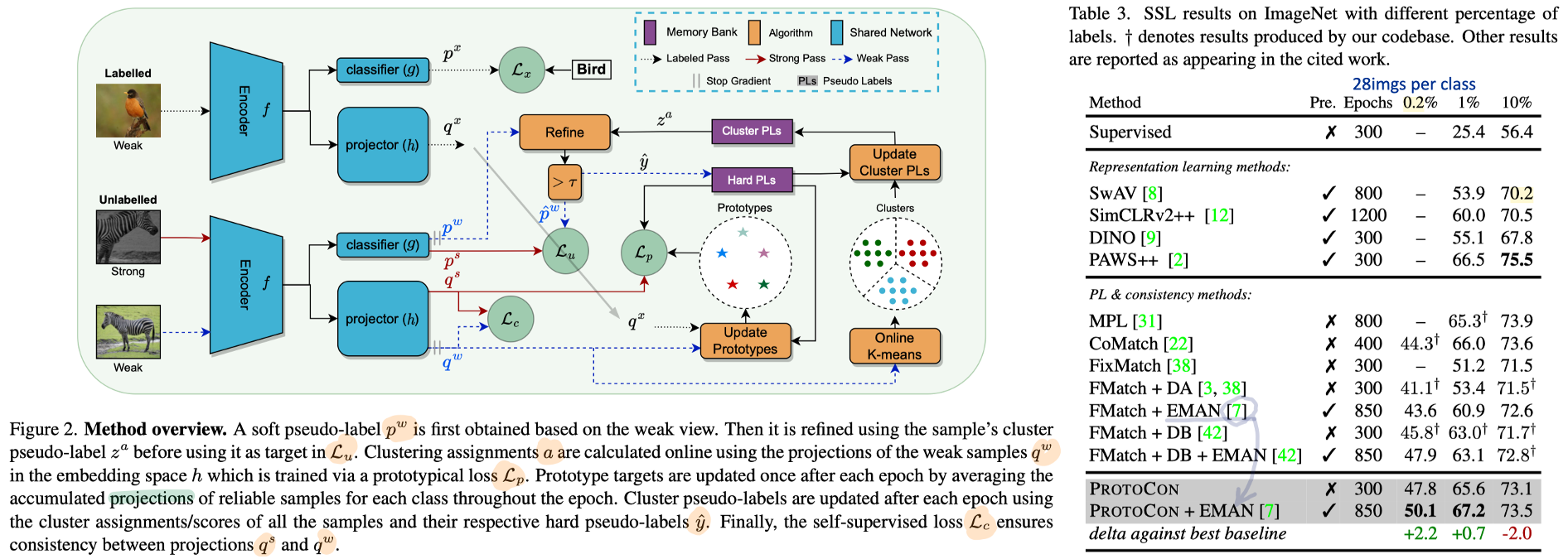
10. PROTOCON: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning. CVPR, 2023 highlight!
- Method
- we perform the refinement: for each image, we obtain two different labels and combine them to obtain our final pseudo label. we employ a non-linear projection to map our encoder’s representation. (Neighborhood 찾는데 사용하는 feature는 projector에서 나온 것 사용)
- Additionally, we design our method to be fully online. we employ a constrained objective lower bounding each cluster size; thereby, ensuring that each sample has enough neighbours in its cluster. (CD-TTA 논문의 online k-means가 아니고, 각 클러스터에 포함되는 일부 feature만을 계속 저장해주는 방식.)
- To boost the initial training signal, we adopt a self-supervised instance-consistency loss applied on samples that fall below the threshold. (DINO + Sharpening. Positive만 고려한 Self-sup loss)
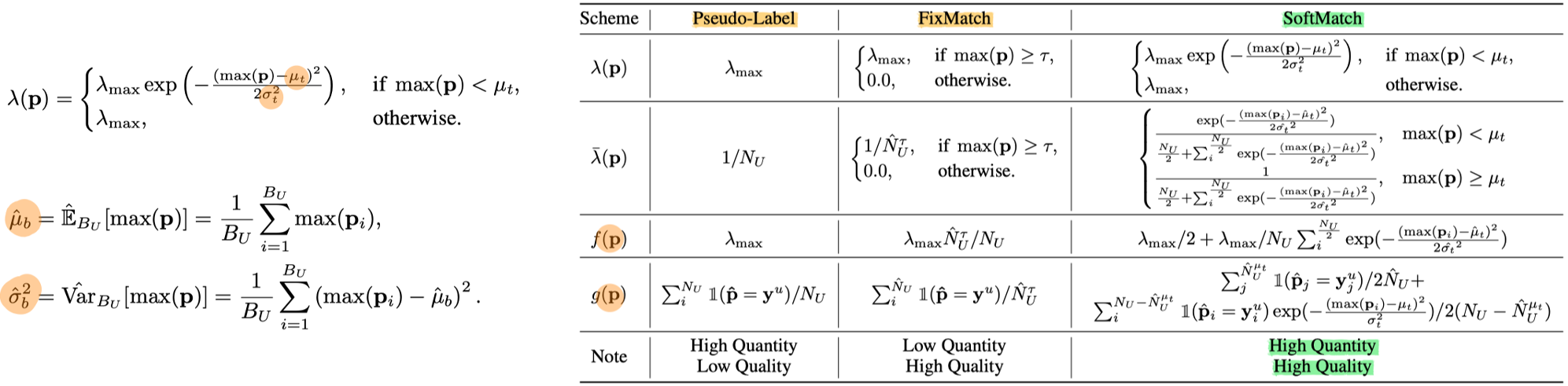
11. SoftMatch- Addressing the Quantity-Quality Trade-off in Semi-supervised Learning. ICLR, 2023.
- [Motivation] In summary, the quantity-quality trade-off with a confidence threshold limits the unlabeled data utilization, which may hinder the model’s generalization performance. (Threshold 를 높이고 낮춤에 따라, Pseudo label의 양과 퀄리티가 바뀌는 현상)
- [Method] We propose SoftMatch to overcome the trade-off by maintaining high quantity and high quality of pseudo-labels during training. We assign lower weights to possibly correct pseudo-labels according to the deviation of their confidence from the mean of Gaussian. (Thresholding 설정 방법을 데이터셋 성향에 따라서 정하겠다.)
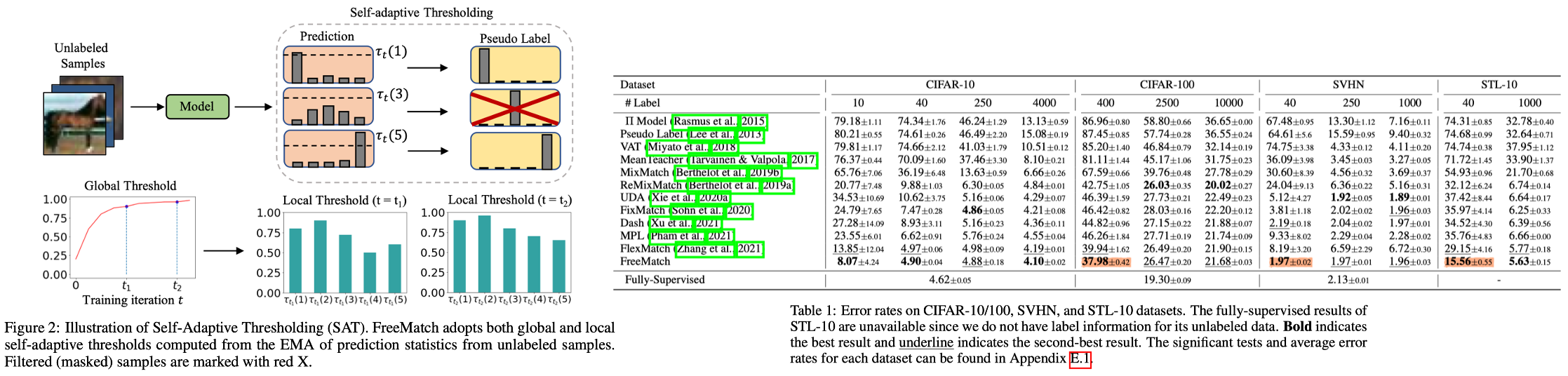
12. FreeMatch- Self-adaptive Thresholding for Semi-supervised Learning. ICLR, 2023.
- The code can be found in USB repository. This link provides reviews of this paper.
- Motivation
- We argue that existing methods might fail to utilize the unlabeled data more effectively since they either use a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme.
- Method
- Self-adaptive Global Threshold
- Self-adaptive Local Threshold (class-specific)