[SSL] Papers for semi-supervised learning 1
0628_SSL
1. Mixmatch: A holistic approach to SSL. NeurIPS, 2019.
- Method
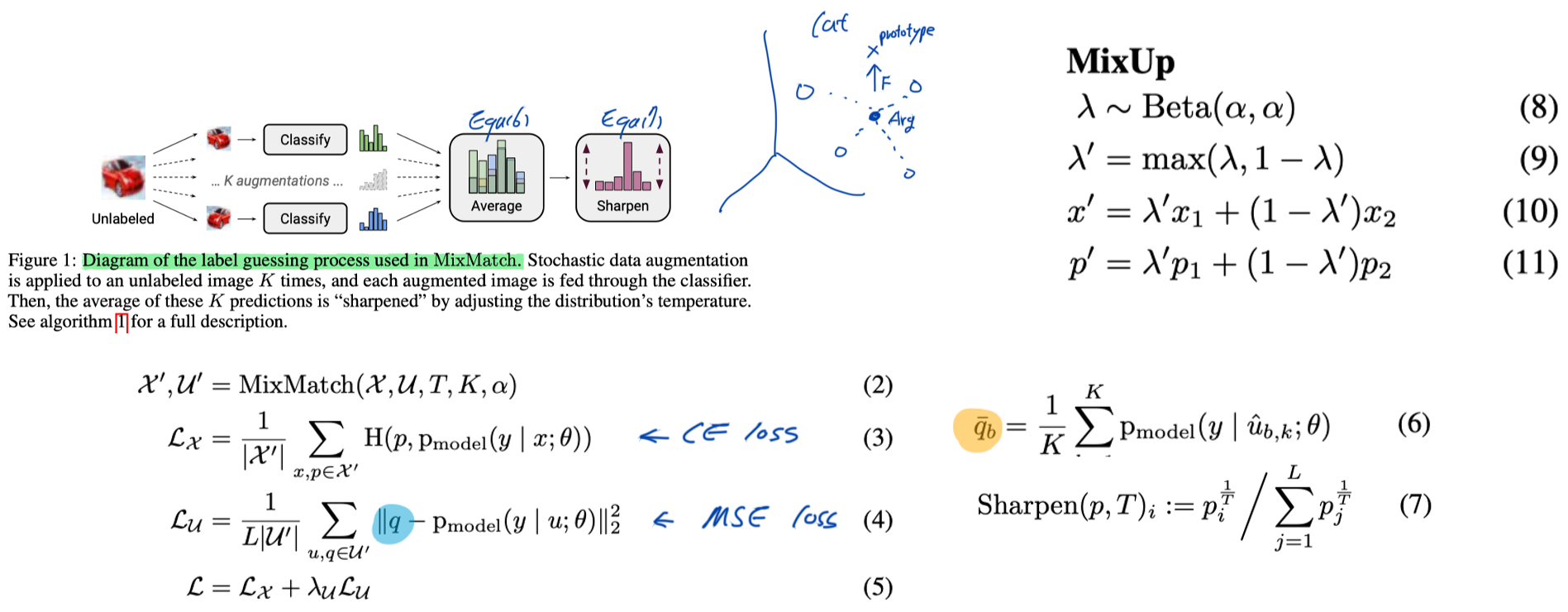
- [Figure1] Average (Prediction of augmented images), Sharpening (Equ. 7), MSE loss for unlabeled data
- MixUp: We use MixUp for semi-supervised learning, and unlike past work for SSL, we mix labeled and unlabeled examples with label guesses.
2. ReMixMatch: SSL with Distribution Alignment and Augmentation Anchoring. ICLR, 2019.
- MixMatch = Sharpening (MSE loss), Mixup
- ReMixMatch = MixMatch (
MSE loss) + (1) Distribution Alignment (2) CE loss with Augmentation Anchor (3) CTAugment
- Methods
- Distribution Alignment: 이름과 역사만 거창하지, 사실상 거의 효과도 없고 의미 없는 loss 인 듯 하다. (See Figure 1.)
- CE loss with Augmentation Anchor
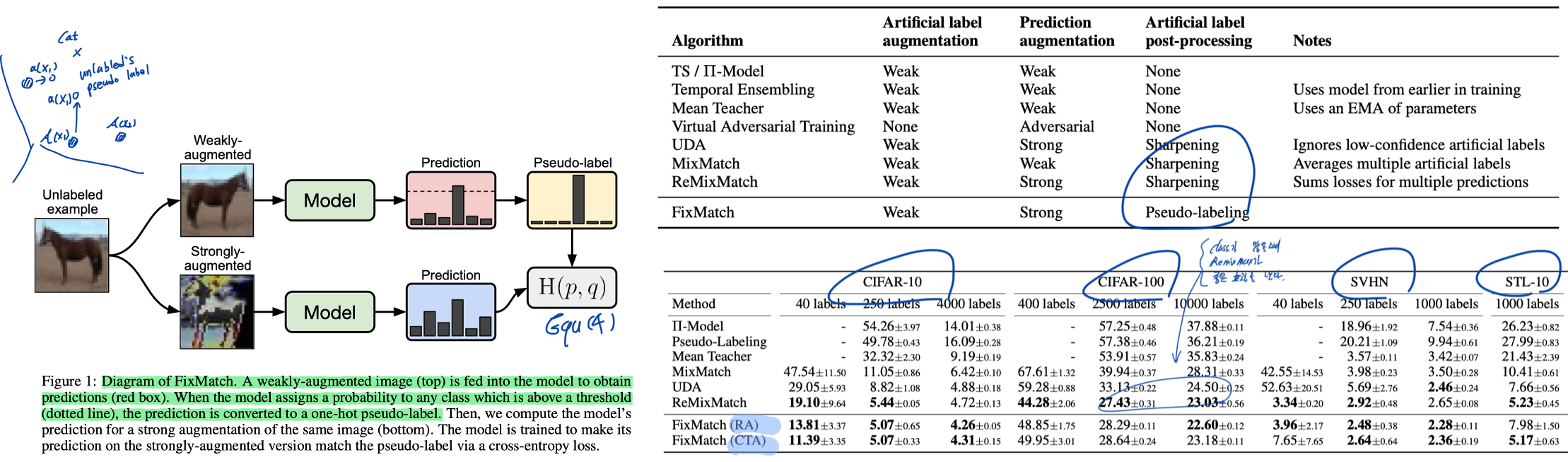
- Recent work (FixMatch) found that applying stronger forms of augmentation can significantly improve performance. See Figure 2.
- we found it enabled us to replace MixMatch’s unlabeled-data mean squared error loss with a standard cross-entropy loss.
- CTAugment: MLP기반의 Architecture, Reinforcement learning 를 사용한 Transformation sampling (Online approach <-> RandAugment = Offline approach) 기법이라 생각하자.
- Self-supervised loss with rotation proxy task.

3. Fixmatch: Simplifying SSL with consistency and confidence. NeurIPS, 2019.
- Method
- Weak (with thresholding) <<= CE loss = Strong (RandomAgment or CTAugment)
- Hyperparameter optimization
- Introduction
- Our algorithm, FixMatch, produces artificial labels using both consistency regularization and pseudo-labeling.
- We also note that it is typical in modern SSL algorithms to increase the weight of the unlabeled loss term (λ u ) during training, We found that this was unnecessary for FixMatch, which may be due to the fact that max(q_b) is typically less than τ early in training.
- SSL for image classification can heavily depend on the architecture, optimizer, training schedule. We endeavor to quantify their importance.
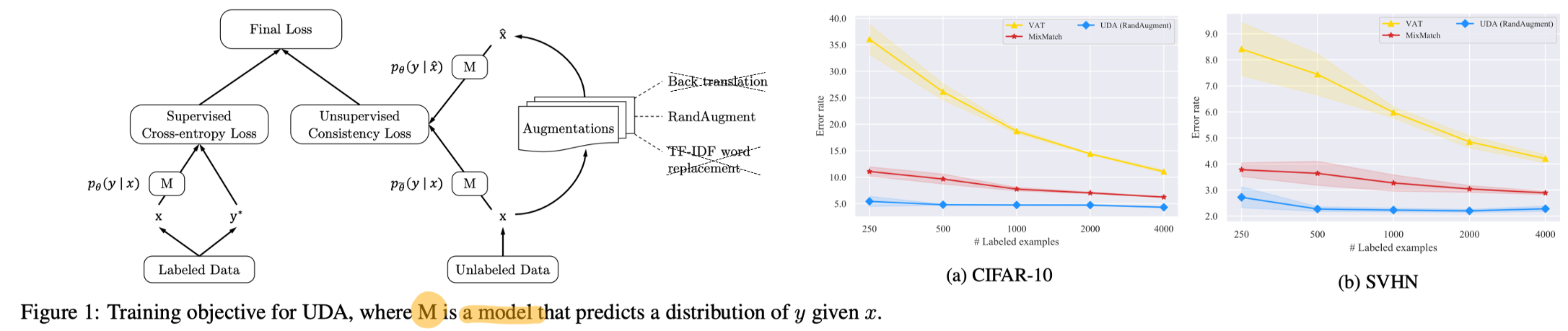
4. UDA: Unsupervised Data Augmentation for Consistency Training. NeurIPS, 2020.
- In this work, we investigate the role of noise injection in consistency training and observe that advanced data augmentation methods, specifically those work best in supervised learning, also perform well in semi-supervised learning.
- Fixmatch와 Method는 거의 동일하다. 유일한 차이점은 UDA used sharpened ‘soft’ pseudo labels with a temperature whereas Fixmatch adopted one-hot ‘hard’ labels. (from, FlexMatching) 이다.
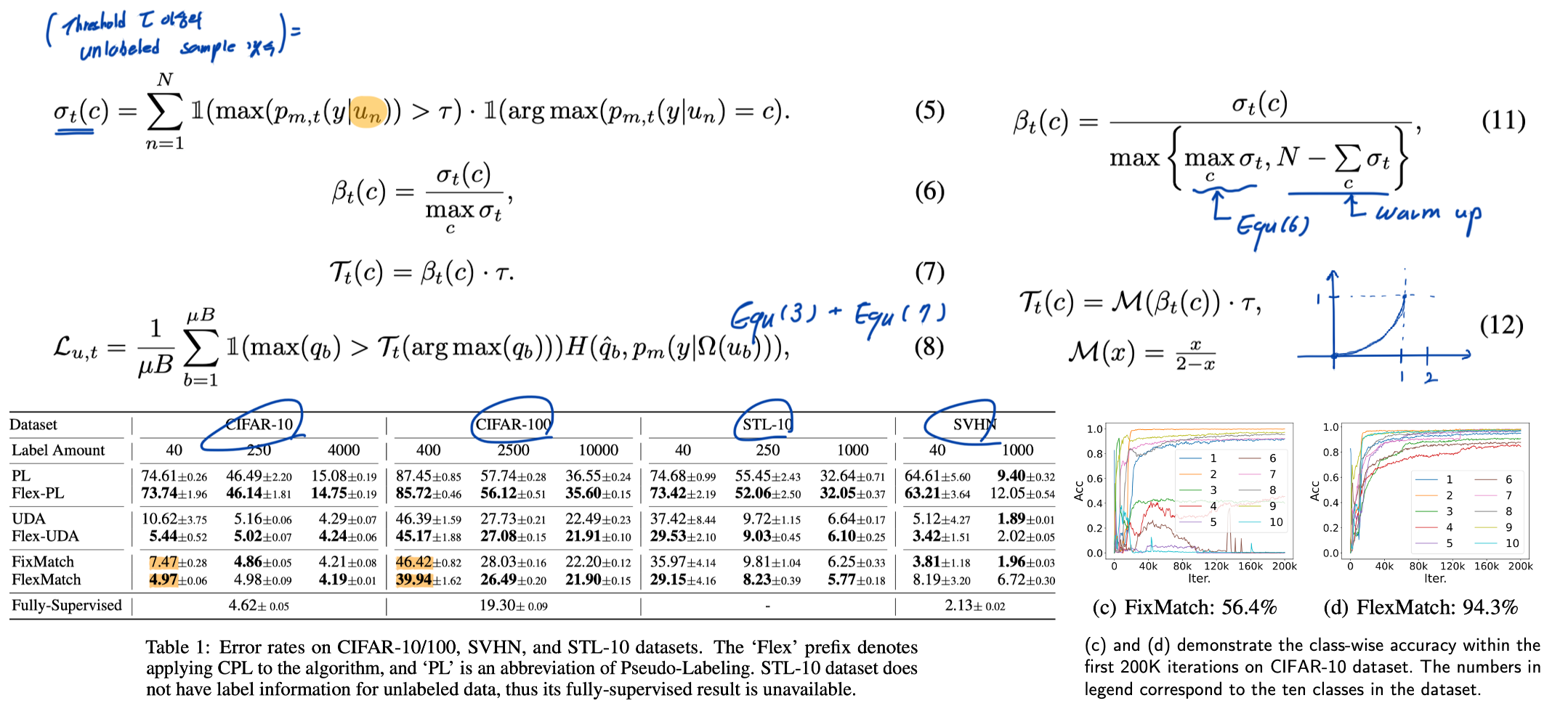
5. Flexmatch: Boosting SSL with curriculum pseudo labeling. NeurIPS, 2021.
- Contributions: (1) Fixmatch with threshold dynamically adjusted for each class. (2) TorchSSL
- Introduction
- [Mot.] Drawback of FixMatch and other popular SSL algorithms is that they rely on a fixed threshold. Moreover, they handle all classes equally.
- [Equ. 5,6,7] We propose Curriculum Pseudo Labeling (CPL), which has flexible thresholds that are dynamically adjusted for each class.
- [Equ. 11] Threshold warm-up: We noticed in our experiments that at the early stage of the training, the model may blindly predict most unlabeled samples into a certain class. In Equ. (11), the term for warm up can be regarded as the number of unlabeled data that have not been used.
- [Equ. 12] Therefore, it is preferable if the flexible thresholds can be more sensitive when β t (c) is large and vice versa.
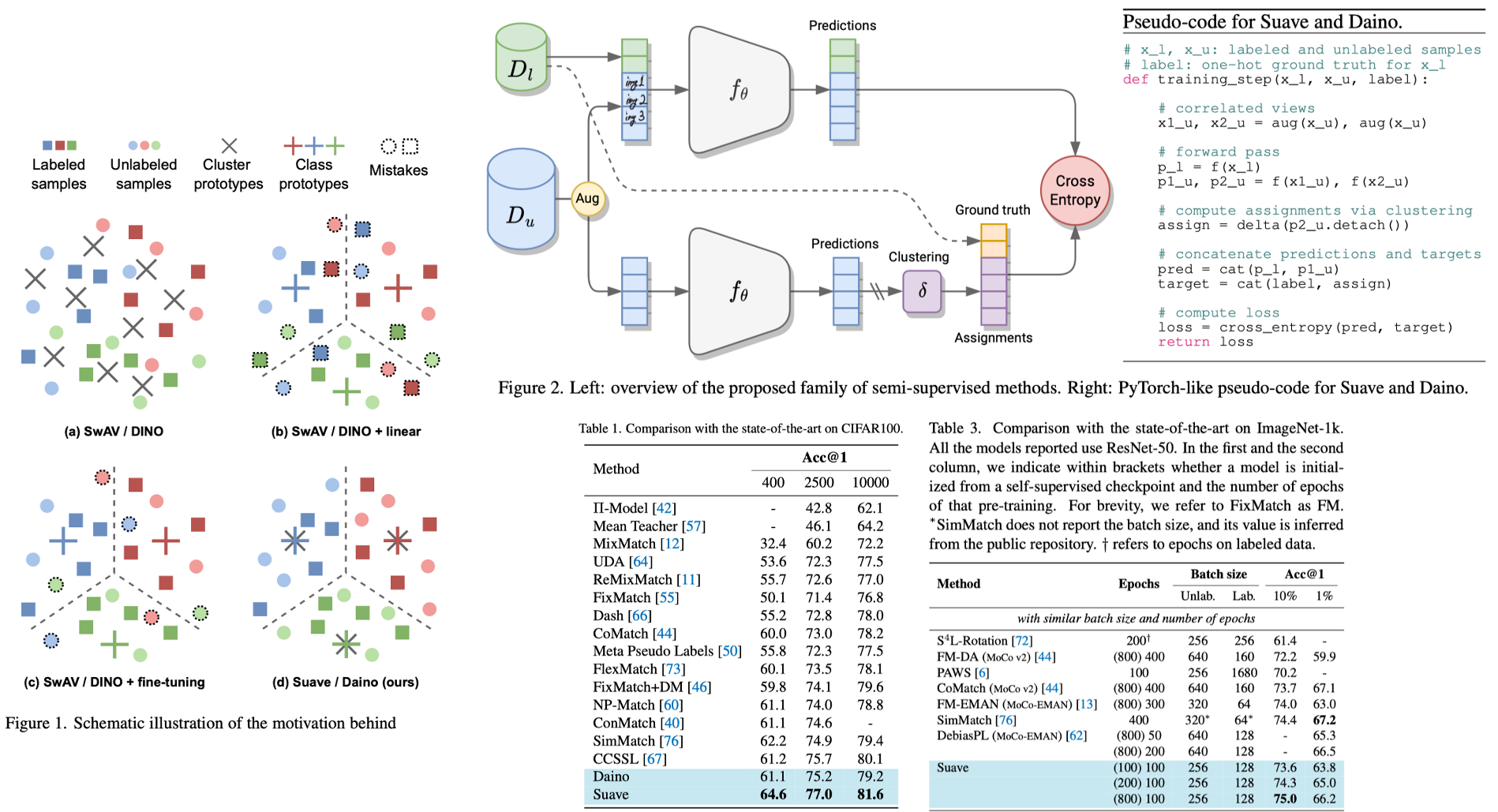
6. Semi-supervised learning made simple with self-supervised clustering. CVPR, 2023.
- Instruction
- In the self-supervised learning landscape, arguably the most successful methods belong to the clustering-based family, such as DeepCluster v2, SwAV and DINO.
- In this paper, we propose a new approach for semisupervised learning: the cluster prototypes can be replaced with class prototypes learned with supervision and the same loss function can be used for both labeled and unlabeled data. (See Figure1)
- Method
- Our main intuition is to replace the cluster centroids with class prototypes learned with supervision. In this way, unlabeled samples will be clustered around the class prototypes, guided by the self-supervised clustering-based objective.
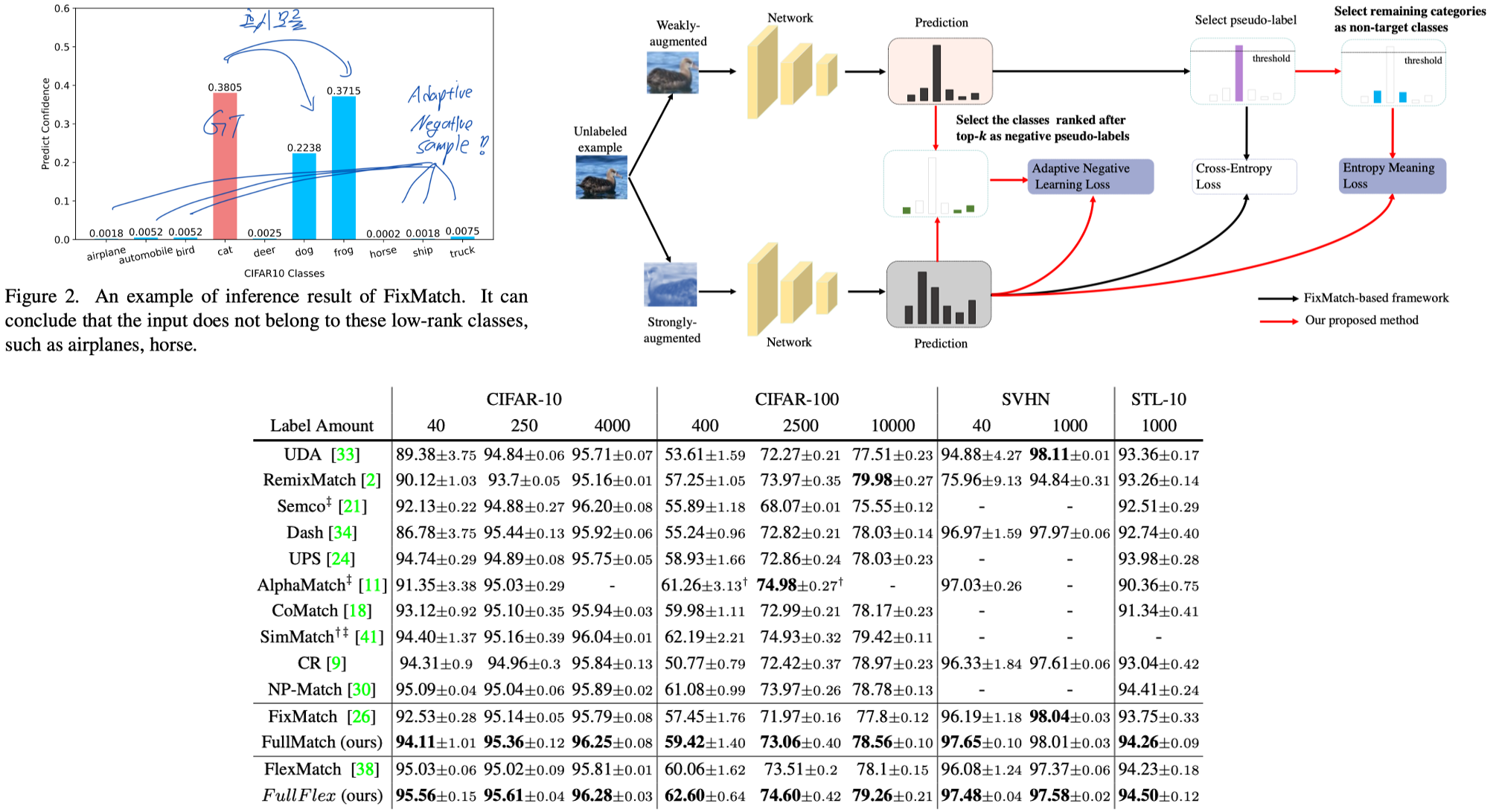
7. Boosting Semi-Supervised Learning by Exploiting All Unlabeled Data. CVPR, 2023.
- Motivation
- Related methods for SSL suffer from the waste of complicated examples since all pseudo-labels have to be selected by a high threshold to filter out noisy ones.
- We argue the competition between partial classes (main class들만 잘 학습되는 현상) leads to failure to produce highconfidence prediction.
- Method
- Entropy Meaning Loss (EML) enforces a uniform distribution of nontarget classes.
- Unlike adjusting the threshold, we aim to strengthen the representation ability of the model itself to produce more predictions far from the decision boundary.
- We impose an additional constraint on the rest of the categories (i.e., all non-target classes) (= Label smoothing)
- Adaptive Negative Learning (ANL) renders negative pseudo-labels (See Fig. 2) with very limited extra computational overhead for all unlabeled data. (Top-K 의 정확도가 100%가 되는 K값을 적절히 설정하고, 그들을 모두 Label로 사용한다. 이렇게 함으로써 threshold를 넘지 못해 학습되지 못하는 샘플들이 학습에 사용될 수 있도록 돕는다,)
8. Others
8.1 CHMATCH: Contrastive Hierarchical Matching and Robust Adaptive Threshold Boosted Semi-Supervised Learning. CVPR, 2023.
- Instance-wise adaptive thresholding
- contrastive learning considering an accurate affinity grapy (= class realationship)
8.2 MarginMatch: Improving Semi-Supervised Learning with Pseudo-Margins. CVPR, 2023.
- We take advantage of the flexible confidence thresholds to allow the model to learn from larger and more diverse sets of unlabeled examples, but unlike FlexMatch, we train the model itself to identify the characteristics of mislabeled pseudo-labels simply by monitoring the model’s training dynamics on unlabeled data over the iterations.
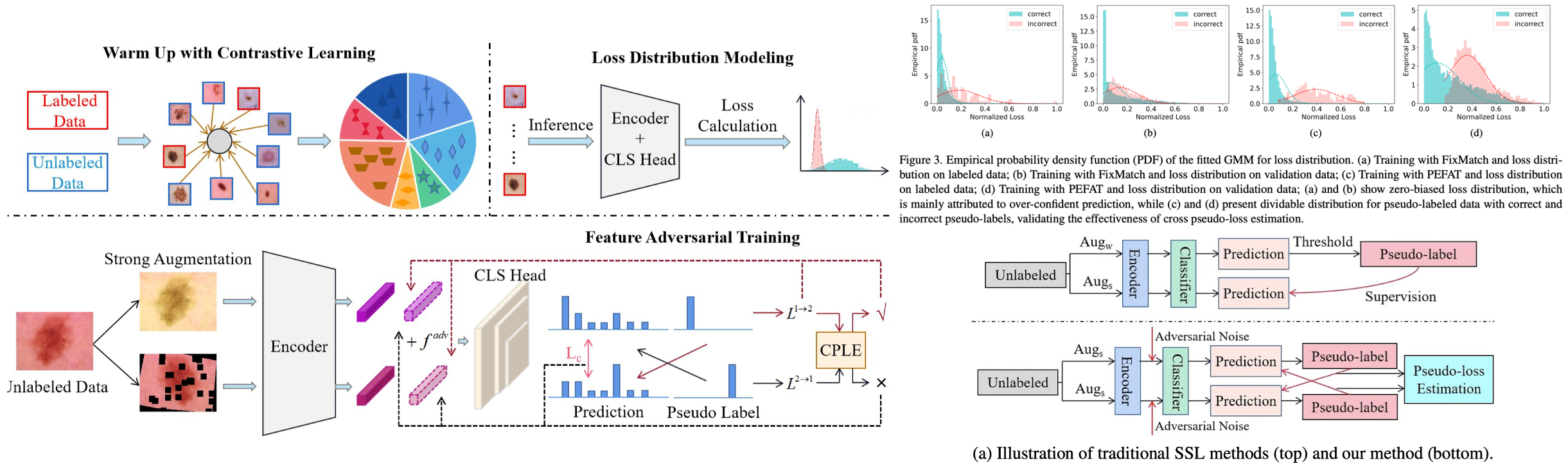
8.3 PEFAT: Boosting Semi-supervised Medical Image Classification via Pseudo-loss Estimation and Feature Adversarial Training. CVPR, 2023.
- Motivations
- Unreliable pseudo-labels are a problem with the thresholdselecting data method.
- Informative unlabeled samples are underutilized as unselected data with low probabilities typically cluster around the decision boundary.
- Method: We propose a novel SSL method called Pseudo-loss Estimation and Feature Adversarial Training (PEFAT) for multi-class and multi-label medical image classification.
- We feed cross pseudo-loss to the fitted GMM and obtain the trustworthy pseudo-labeled data with posterior probability.
- We propose a feature adversarial training (FAT) strategy that injects adversarial noises in the feature-level to smooth the decision boundary.
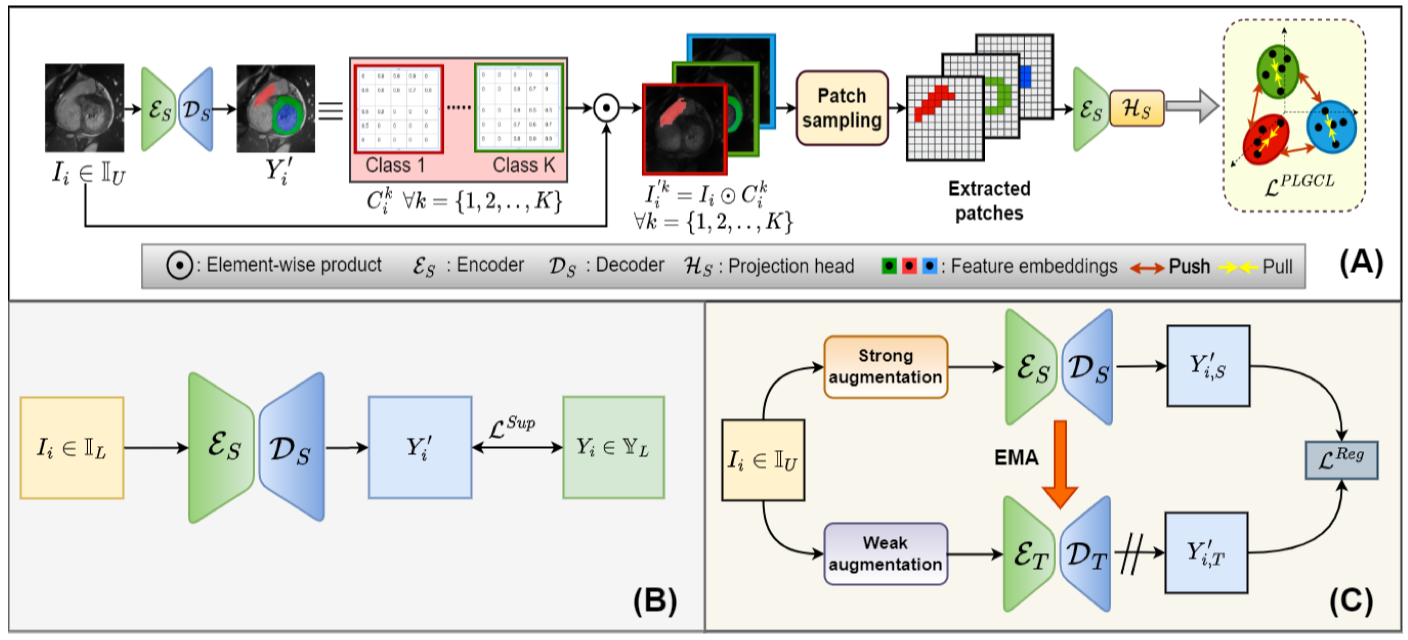
8.4 Pseudo-label Guided Contrastive Learning for Semi-supervised Medical Image Segmentation. CVPR, 2023.
- The pseudo-labels generated in SemiSL aids CL by providing an additional guidance to the metric learning strategy, whereas the important class discriminative feature learning in CL boosts the multi-class segmentation performance of SemiSL.
- 1) Fixmatch 기법을 기대로 적용해서 Semi-sup을 적용했다. 2) Contrastive leanring 을 segmentation 맵의 pixel 단위로 적용했다.