[SSDA] Semi supervised domain adaptation 1
0704_SSLandDA
1. Semi-Supervised Domain Adaptation with Source Label Adaptation CVPR23
- Motivation
- Previous works typically require the target data to closely match some semantically similar source data. (Target을 Source에 맞추려고 하지말고, Source를 Target에 맞추자.)
- That is, source labels can be viewed as a noisy version of the ideal labels for target classification. i.e., our key idea is to view the source data as a noisily-labeled version of the ideal target data. (Noisy Label Learning (NLL) problem).
- Method
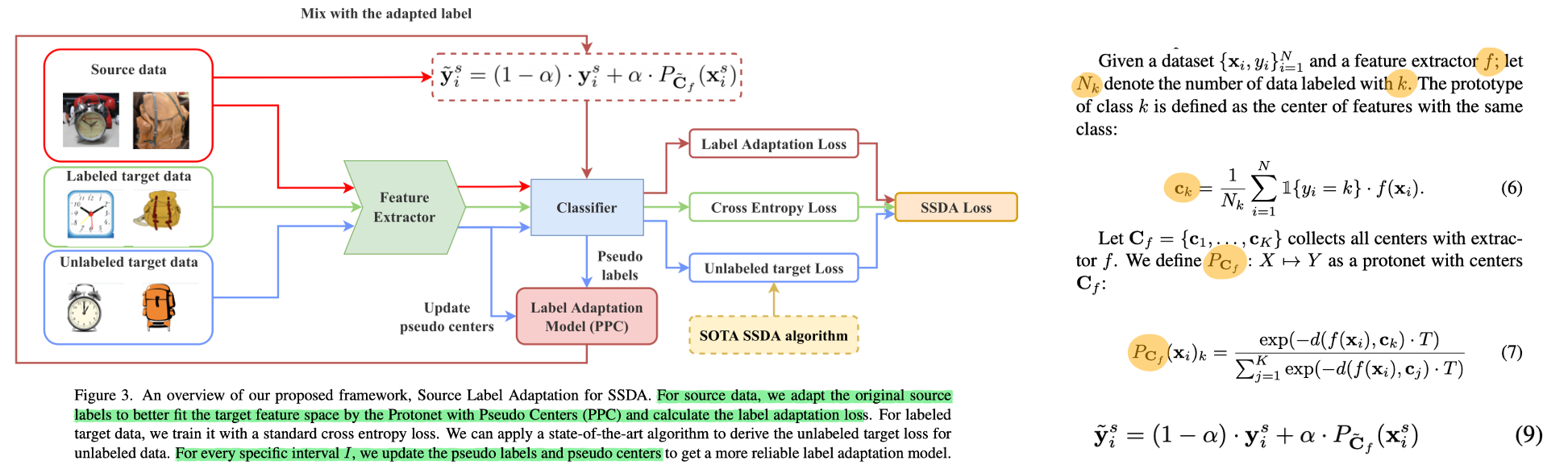
- The main contribution of this paper in Figure 3 is
Label Adaptation Model (PPC). Unlabeled target loss comes from the algorithm of previous methods (ex, MME, and CDAC).
- Label Adaptation Model (PPC) = For source data, we adapt the original source labels to better fit the target feature space by the Protonet with Pseudo Centers (PPC) and calculate the label adaptation loss.
- Source label 을 그대로 사용하지 않고, (labeled + unlabeled) Target prototype 과의 euclidean distance 를 사용해 refine한 label 과 융합하여 사용한다. (Eq. (9)) + (Eq. (7)에서 unlabeled target data까지 고려해 만든 centroids를 사용한 것이 tilde(C_f))
2. AdaMatch- A Unified Approach to Semi-Supervised Learning and Domain Adaptation_ICLR22
- Motivation
- While SSDA has received less attention than both SSL and UDA, we believe it describes a realistic scenario in practice and should be equally considered.
- Method
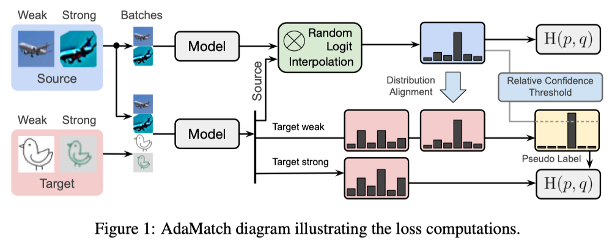
- AdaMatch extends FixMatch with:
- (1) Adjusting the pseudo-label confidence threshold on-the-fly: 각 에폭마다, [Source 데이터들의 probability 평균 x 0.9] 를 Threshold 로 사용한다.
- (2) A modified version of distribution alignment of ReMixMatch: source와 target간의 distribution alignment 수행한다.
- (3) Random logit has the effect of producing batch statistics that are more representative of both domains (Section 3.1)
- Notes
- 위와 동일한 SSL + DA 보다는 UDA 세팅을 기본으로 한다.
- 실험에 사용하는 모델은 scratch model 이다. imagenet pre-trained model 조차 사용하지 않는다. 따라서 UDA 기법들 성능이 당연히 안 나올만 하다.
3. Multi-level Consistency Learning for Semi-supervised Domain Adaptation IJCAI21
- Methods
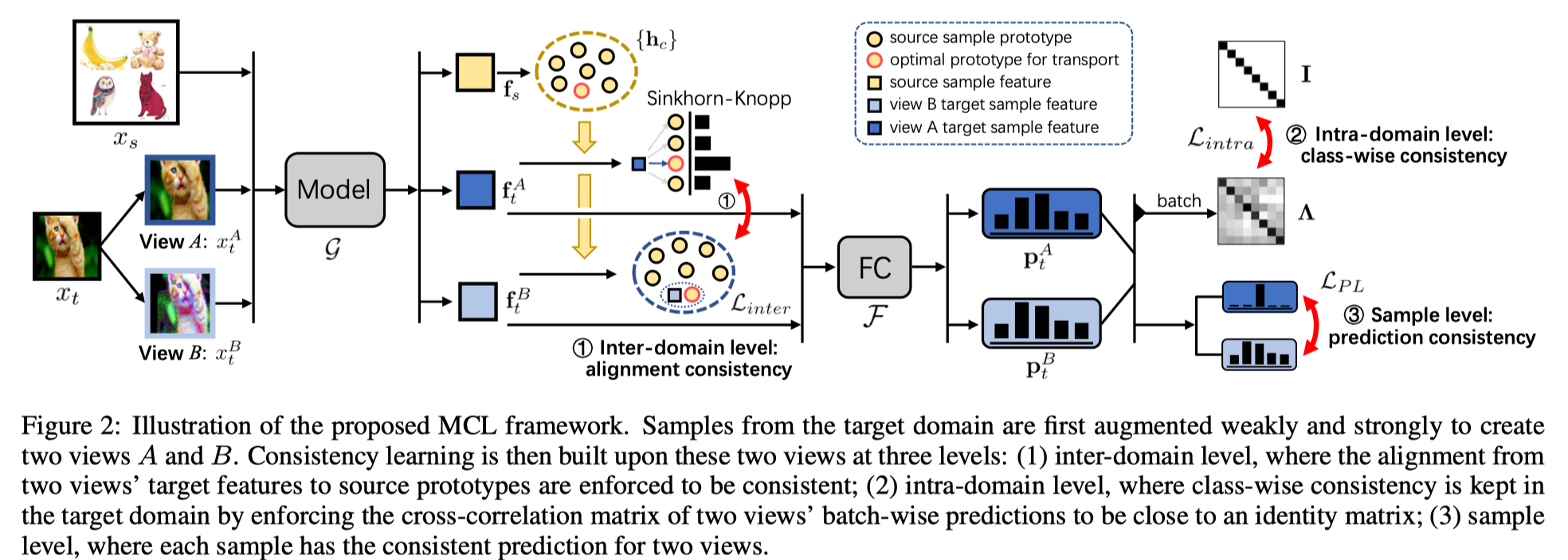
- (Figure2. [1]) inter-domain level: we first solve the optimal transport mapping between one view of the target samples and the source prototypes, and leverage the solved mapping to cluster another view to the source prototypes. (Weak target 과 가장 가까운 source prototype을 찾고, strong target이 그 prototype과 가까워지도로 mapping.)
- (Figure2. [2]) intra-domain level: computing the class-wise cross-correlation between the predictions from two views (target samples) in a mini-batch, and increasing the correlation of two views in the same class while reducing those from different classes.
- (Figure2. [2]) the sample level: enforcing the predictions of the weakly-augmented and the strongly-augmented views to be consistent.
4. Deep Co-Training with Task Decomposition for Semi-Supervised Domain Adaptation ICCV21
- Motivation
- Several recent works, however, show that adding merely a tiny amount of target labeled data (e.g., just one labeled image per class) can notably boost the performance suggesting that this setting may be more promising for domain adaptation to succeed.
- First, the amount of labeled source data is much larger than that of labeled target data. Second, the two data are inherently different in their distributions. ➔ A single classifier learned together with both sources of supervision is thus easily dominated by the labeled source data and is unable to take advantage of the additional labeled target data.
- Methods
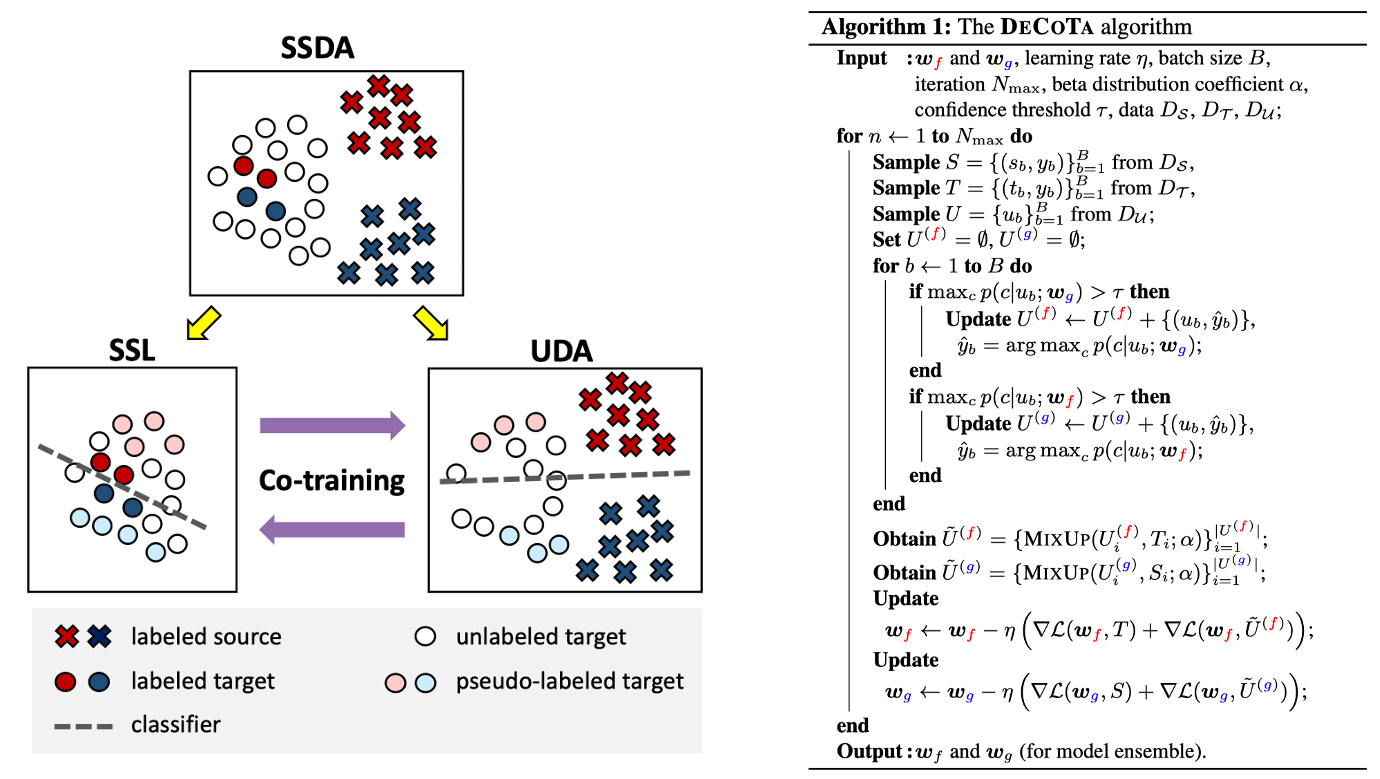
- Learn two distinct classifiers. ➔ To this end, we pair the labeled source data and the unlabeled target data to learn one classifier.
- The approach is straightforward: train a separate classifier on each task using its labeled data, and use them to create pseudo labels for the unlabeled data. As the two classifiers are trained with distinct supervision, they will yield different predictions.
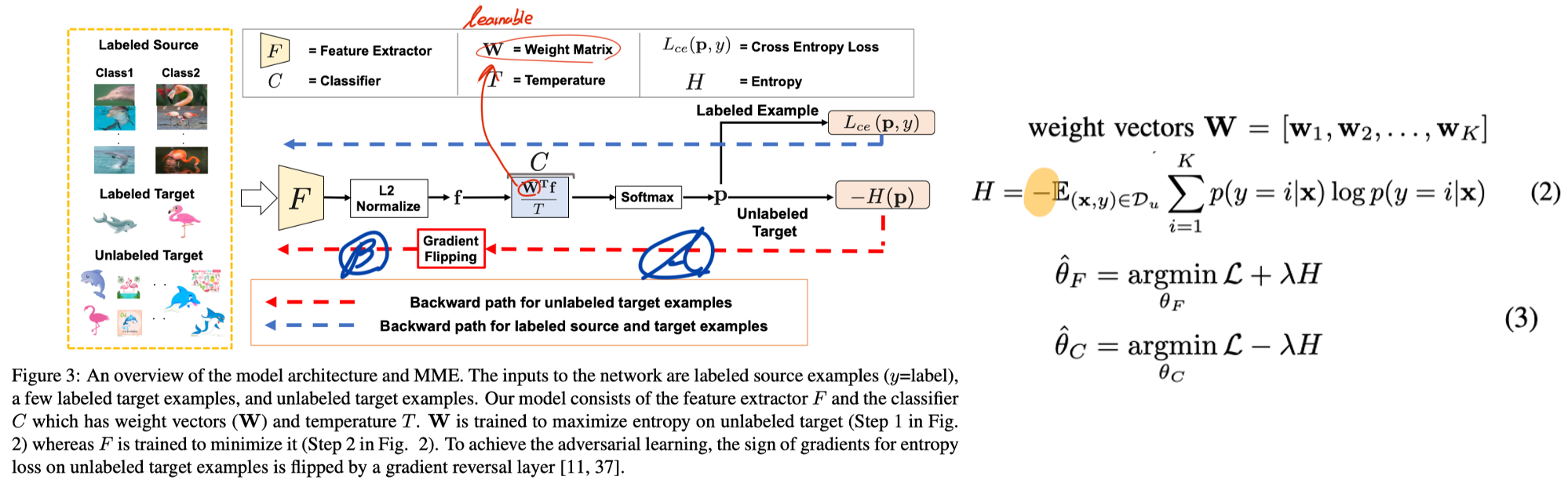
5. Semi-supervised Domain Adaptation via Minimax Entropy_ICCV19
- Motivation
- We show that these UDA techniques perform poorly when even a few labeled examples are available in the target domain.
- While this approach (a cosine similarity-based classifier with K-way weights) outperformed more advanced methods in few-shot learning and we confirmed its effectiveness in our setting.
- Methods
- We exploit a cosine similarity-based classifier, recently proposed for few-shot learning.
- [A in Figure 2] We move the weight vectors towards target by maximizing the entropy of unlabeled target examples in the first adversarial step.
- [B in Figure 2] We update the feature extractor to minimize the entropy of the unlabeled examples.
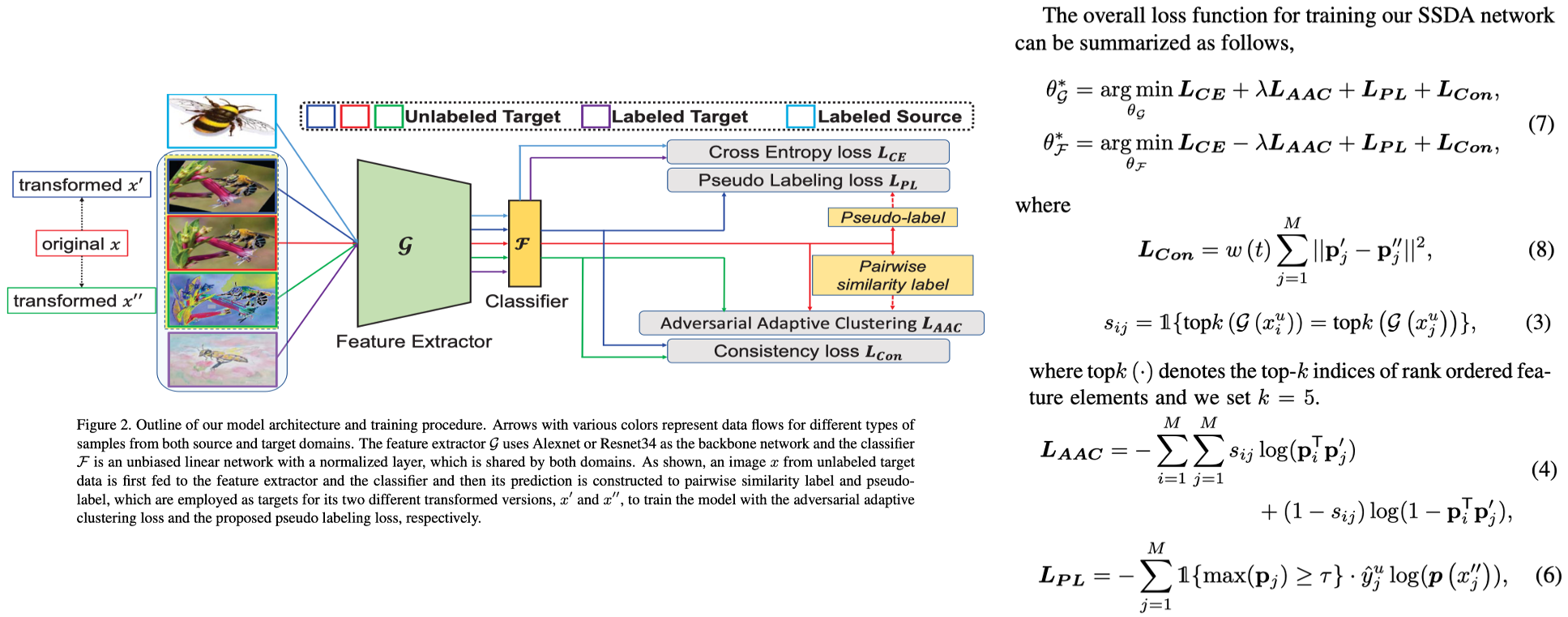
6. Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation_CVPR21
- Summary: Class-wise + Minmax probability + Fixmatch (Pseudo labeling, Weak-strong consistency loss)
- Motivations
- Many existing domain adaptation approaches guide their models to learn cross-domain sample-wise feature alignment. However, such previous work ignores extra information indicated by class-wise subdistributions.
- Several papers (supervised DA) has turned to optimizaing class-wise sub-distributions with the target domain. However, in our setting, we only have a few labeled target samples.
- Method (Cross-domain Adaptive Clustering (CDAC))
- Pseudo labeling (Figure 1 (b) and Eq.(6))
- Intra-domain adaptation: The features of unlabeled target samples are guided by labeled target samples to form clusters by minimizing an adversarial adaptive clustering loss (Loss_AAC in Eq.(4)) with respect to the featuer extractor.
- Inter-domain adaptation: The classifier is trained to maximize the above loss defined on unlabeled target samples. ()
- Class-wise (Eq. (3))
- Consistency loss (Eq.8)
Private Notes
- UDA + SSL 논문들이다. 일부 논문들 인트로에 왜 두개의 Task를 잘 엮는게 중요한지에 대한 이야기가 있다. (DCOTA, MATCH 등) 이런 내용은 참고해도 좋을 듯 하다.
- 그럼에도 불구하고, UDA는 필연적으로 Source data를 사용한다. TTA 그리고 SFDA 논문을 준비한다면, 이들과 비교할 필요는 없어 보인다. 그럼에도 왜 비교를 하지 않았는지, 만약 비교를 한다면 얼마나 성능차이가 발생하는지 등에 대한 이야기는 작게 보여줘도 좋을 듯 하다. (SLA 코드사용)
- 아래의 논문들은 비교를 1-Shot, 3-Shot 으로 하는데 이는 MME ICCV19 논문에 ''왜 이런 세팅으로 실험했는지''에 대한 내용이 있다. 따라서 몇 % , 몇 장의 labeled 라는 형식의 SSL 방식을 따라가는게 더 적합해 보인다.
- UDA + SSL 논문에서 주장하는 Method에 대한 깊이는 그리 크지 않다. UDA, SFDA, SSL에서 unlabeled data를 정교하게 사용하는 방법, Contrastive learning을 더 잘 적용하는 방법에 관한 논문들 처럼 엄청 복잡한 기법들이 나온 것은 아니다.
- MME_ICCV19, CDAC_CVPR21 2개의 논문이 생각보다 많은 Insight를 준다. (나머지 4개의 논문에 비해) 좋은 논문이니, 나중에 디테일하게 읽어볼 필요가 있을 듯 하다. 아이디어가 다시 떠오를 수 있다.
Paper lists
- ✔️ AdaMatch- A Unified Approach to Semi-Supervised Learning and Domain Adaptation_ICLR22.pdf
- ✔️ Deep Co-Training with Task Decomposition for Semi-Supervised Domain Adaptation ICCV21.pdf
- ✔️ Multi-level Consistency Learning for Semi-supervised Domain Adaptation IJCAI21.pdf
- ✔️ Semi-Supervised Domain Adaptation with Source Label Adaptation CVPR23.pdf 🌟
- ✔️Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation (CDAC)_CVPR21.pdf 🌟
- ✔️Semi-supervised Domain Adaptation via Minimax Entropy (MME)_ICCV19.pdf 🌟
Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners arxiv21.pdfFew-Shot Learning via Embedding Adaptation with Set-to-Set Functions CVPR22.pdf