[SAM] Papers related to Segment Anything
1. Details of SAM
- Method: https://www.junha.page/2023/04/misc-hot-papers-in-april-2023.html
- Presentation material:
Onedrive/Davian/Study/Generative/EfficientSAM.pptx
- SAM outputs multiple valid masks and associated confidence scores. 따라서 AR@100, 1000 구현 가능하다. 논문 21페이지 참조.
- Zero-Shot Object Proposals: the standard average recall (AR) metric on LVIS v1 (1200개 카테고리) / Object proposal에서 AR 의 정의와 사용하는 이유
- Zero-Shot Instance Segmentation: COCO, LVIS 사용, AP^{S,M,L} 측정
- 단, 위 2개의 평가 지표인 Object proposal이랑 Instance segmenation proposal 각각의 matrix가 무엇이고 어떤 차이가 있는지 조사가 필요하다.
2. Fast Segment Anything
- Motivation
- Segment anything model (SAM) has had a significant influence. However, its huge computation costs prevent it from being used in wider applications in industry scenarios.
- Solution
- Use YOLOv8-seg (built on YOLACT) as a model architecture, and train the model on 2% of the SA-1B dataset.
- Advantage: Regardless of the number of points (segment everything task = segmentation with points on 32*32 grid), the inference time is the same.
- Experiments
- The FastSAM's performance of box generation is comparable to SAM. FastSAM, however, has a limited capacity for mask generation.
- Their performance was mainly computed in a COCO dataset.
- 오른쪽 위 실험결과: Zero-Shot Object Proposal
- 오른쪽 중간 실험결과: Instance segmentation proposal
- Question
- SAM이 ViT 를 사용한 이유는 Vision foundation model을 만들기 위함이 아니었나 싶다. / Language 모델이 모델 사이즈 증가, 토큰(?) 증가로 좋은 능력을 가지는 것은 확인할 수 있었다. 하지만, SAM을 봐서는 Vision에서 같은 양상을 가지는 것은 아닌듯 하다. / 근거는 다음 2가지다. 1) Generalization 능력이 올라가지 않는다 (인규형 발표, 차오닝 관련 논문들) 2)
작은 모델, 적은 데이터 학습시킨 모델과 성능이 유사하다. Efficeint SAM의 Table4, 5/ Figure7 에서는 SAM이 작은 모델보다 성능은 좋다.
- ViT가 CLIP 기법으로 매우 높은 Zero-shot classificaiton 능력을 가질 수 있음을 보여줬다. 하지만 Segmentation, Detection에서는 CLIP과 같은 경향이 보이지 않은 것 같다.
- probability score가 있는게 아닌데, NMS 어떻게 한거지? -> 아래 Detect 모듈에 box probability score가 있다고 생각하자. 구체적인 것은 코드를 봐야할 것 같다.
- References

3. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
- Motivation
- Meta Research team proposed SAM and believe it to be a GPT moment for vision. SAM has attracted attention for several reasons: 1) SAM follows NLP to pursue a path that combines the foundation model with prompt engineering. 2) It performs label-free segmentation. 3) SAM is easy to be compatible with other models (ex, Grounded DINO, editor application.)
- As shown in the official demo, the SAM can work on resource-constrained devices.
- Method
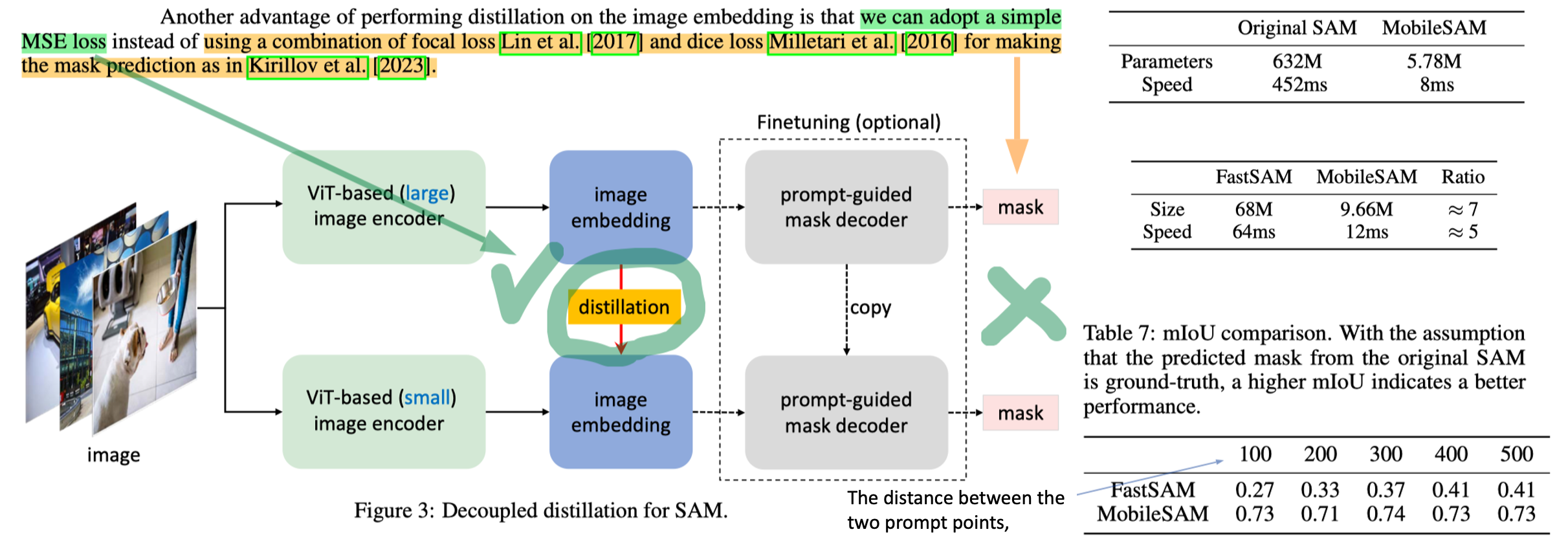
- The key to obtaining a mobile-friendly SAM lies in replacing the heavyweight image encoder with a lightweight one, which also automatically keeps all the functions and characteristics of the original SAM.
- Mask를 distilled 하는 방식을 coupled, image embedding을 distilled 하는 방식을 deccoupled distillation이라고 부른다. Empirically, the latter shows a better performance, even without fine-tuning the decoder model.
- Results
- SA 데이터에서 학습하고, SA 데이터에서 Eval한 결과만 있다. COCO같은 데이터셋도 사용되어 성능이 측정되었다면 좋았을 듯 하다. 대신 original SAM output과 fasterSAM의 output의 mIoU를 비교하는 실험 결과를 제시한다. 차라리 이게 더 옳은가 평가인가 라는 생각도 든다. -> EfficientSAM에서 COCO 성능 측정했는데 MobileSAM 성능이 FastSAM 보단 좋다.
- anything task (one object) 에서는 FasterSAM이 모델 사이즈 때문에 빠를진 몰라도, FastSAM은 포인트 갯수에 상관없이 같은 속도를 가지기 때문에, 뭐가 더 빠르다 비교하기는 힘들 듯 하다.
4. MobileSAMv2: Anything to everything
- Introduction
- Following the success of foundation models in NLP, vision foundation models like CLIP have been developed. More recently, a vision foundation model termed SAM was released.
- Image segmentation often involves predicting their corresponding semantic labels from a predefined class set. However, it is far from practical applications because there can be unlimited classes in the real world. (Github: CLIP-SAM, Segment-Anything-CLIP, segment anything-with-clip)
- 모든 grid에 대해서 decoder를 통해서 segmentation 결과를 추출하는 것은 비효율적이므로, object내부 points들 전체를 사용하지 않아도 되는 방법을 제안하겠다.
- Method
- YOLOv8을 SA-1B에 학습시킨다. -> 여기서 나오는 Box 정보만 모은다. 그 박스를 Prompt-aware이라고 간주하고 SAM original model에 다시 이미지를 Inference 해서 sementation 결과를 추출한다.
- YOLOv8에서 나오는 Mask의 center point를 이용해도 되지만, 이는 1) 낮은 성능을 유도하고, 2) ambiguity issue (사람 전체 vs 사람 팔 vs 사람 손가락) 를 유도한다.
- Results
- 웃긴 점은, MobileSAM (fasterSAM) 처럼 작은 size의 image encoder를 사용하지 않았다.
- We report the results on 100 images randomly sampled from the large vocabulary instance segmentation (LVIS) dataset. (mask AR score)
- SAM은 AR@K에서 K가 작을때 낮은 성능이 나온다.

5. EfficientSAM: Leveraged masked image pretraining for efficient segment anything.
- Introductions
- The image encoder (e.g., ViT-H) is very expensive. It challenging for real-time applications.
- Method
- See Figure 2.
- Cross attention decoder is discared after pretraining. Prompt-guided mask decoder is the same to one of SAM.
- Evaluation
- Transfer leaning (downstream tasks): ImageNet pretraining -> ImageNet, COCO, ADE dataset finetuining -> Evaluation
- Zero shot: ImageNet pretraining -> SA-1B finetuning -> Evalutation
- Question
- MobileSAM, FastSAM은 SA-1B에서 일부 데이터만 사용했다, EfficientSAM은 전체 데이터 사용했다. 학습 이미지 사이즈는 모두 1024로 동일하다. FastSAM, MobileSAM 또한 SA-1B 전체로 Fine-tune 해주고 비교했다면, Figure1이 공정한 실험이었다고 할 수 있겠다.
- 제안된 method가 segmentation specific 한가? 는 모르겠다. Segmentation을 위해서 이미지 전체 에 대한 이해가 왜 필요하지? 주어진 seen patch로 unseen patch를 예측하는 task가 왜, 향후 sementation에 좋은지 모르겠다. 그래서 이 논문 제목의 메인을 pretraining이라고 했구나. Efficient SAM 모델의 구축은 사실 부수적인 것이다.

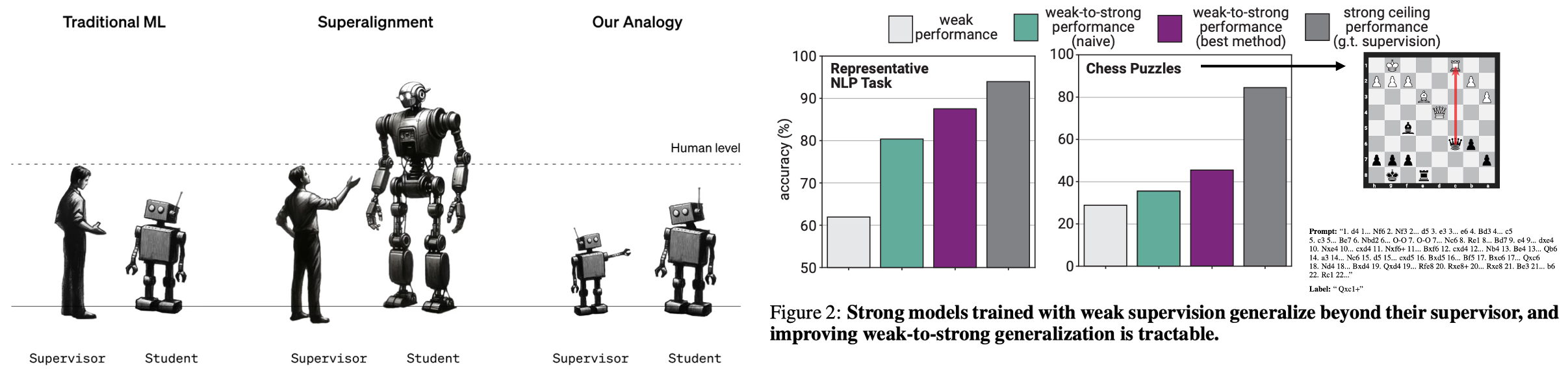
6. Weak-to-strong generalization
- https://openai.com/research/weak-to-strong-generalization
- https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
- Introduction
- How can weak supervisors (humans) trust and control substantially stronger models (AGI, superintelligence, smarter than humans)?
- Results
- (1) naive human supervision—such as reinforcement learning from human feedback (RLHF)—could scale poorly to superhuman models without further work, but (2) it is feasible to substantially improve weak-to-strong generalization.
- Conclusions
- We are releasing open-source code](https://github.com/openai/weak-to-strong) to make it easy to get started with weak-to-strong generalization experiments.
- Figuring out how to align future superhuman AI systems to be safe has never been more important. We are excited to see what breakthroughs researchers discover.