[CVinW] Compution vision and Language papers 1
CVinW papers1
1. CLIP-Learning Transferable Visual Models From Natural Language Supervision_OpenAI21
- We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet.
- We use a very large minibatch size of 32,768.
- For many datasets, we observed these labels may be chosen somewhat haphazardly.

2. Frozen- Multimodal Few-Shot Learning with Frozen Language Models _ NeurIPS/DeepMind21
- Instruction
- Despite these impressive capabilities, such large-scale language models are blind.
- Goal: Frozen is a multimodal few-shot learner.
- Method
- we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained (frozen) language model prompted with this vision prefix (image embeddings).
- We use the final output vector of the NF-Resnet after the global pooling layer.
- Limitations
- The key limitation is that it achieves far from state-of-the-art performance, compared to systems that use full training.

3. GroupViT: Semantic Segmentation Emerges from Text Supervision_CVPR22
- Introduction
- Deep learning for grouping: (i) learning is limited by the high cost of per-pixel human labels; and (ii) the learned model is restricted only to a few labeled categories and cannot generalize to unseen ones.
- Method
- We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses with only text supervision and without any pixel-level annotations. We use a 2-layer MLP to project the visual and text embedding vectors into the same latent space.
- Our key idea is to leverage the Vision Transformer (ViT) [24] and incorporate a new visual grouping module into it. (See the paper for the details)
- Results
- GrouViT (ViT-S based) trained on the Conceptual Caption and Yahoo Flickr Creative Commons datasets.
- Zero-shot semantic segmentation: 52.3% mIoU on the PASCAL VOC 2012.
- During inference, GroupViT predicts only the foreground classes by thresholding the softmax-normalized-similarity between the embedding of the output image segments and the text segmentation labels, where we set the threshold to 0.9 and 0.5 for PASCAL VOC 2012 and PASCAL Context,

4. VL-Adapter- Parameter-Efficient Transfer Learning for Vision-and-Language Tasks_CVPR22
- Introduction
- if we use GPT-3 with 175B parameters as a backbone of V&L model, we would need 700 GB of memory to store its entire parameters.
- Untill now, no work has utilized this efficient method for more challenging downstream V&L problems.
- Method
- We then insert (1) Adapter with weight-sharing technique (2) Hyperformer, (3) Compacter, and (4) adapter-based approaches with prompt tuning.
- Findings
- (1) Compacter does not stand out in terms of efficiency, (2) Hyperformer is more efficient, but (3) our adapter training with the weight-sharing technique can achieve the same performance as full fine-tuning.
- Freezing of the CLIP parameters achieves a better trade-off between performance and parameter efficiency than the fine-tuning the CLIP encoder.
- We find that using a single set of adapter modules across all tasks achieves the best results.
- We also demonstrate that the results of training adapters on top of V&L pre-trained weights can match or even exceed.

5. Supervision Exists Everywhere- Data efficient CLIP (DeCLIP) _ICLR22
- Motivation:
- CLIP is quite data-hungry and requires 400M image-text pairs for pre-training.
- Method
- They make the training process more complicated than CLIP,
- For example, (1) Self-supervision (Masked language modeling), (2) Multi-View Supervision (MVS = Visual contrastive learning), and (3) newly proposed Nearest Neighbor Supervision(NNS).
- NNS: we sample the NN texts in the embedding space and utilize them as additional supervisory signals. (image1 <-> text1 + text2, where text2 is fined by Nearest Neighbor.)
- Findings
- DeCLIP-ResNet50 can achieve 60.4% zero-shot top1 accuracy on ImageNet, which is 0.8% above the CLIP-ResNet50 while using 7.1× fewer data.
- Our model has much better data efficiency in 8 out of 11 datasets.

6. Prompting Visual-Language Models for Efficient Video Understanding_ECCV22
- Method
- This paper presents a simple but strong baseline to efficiently adapt the pre-trained I-VL model (Image-based visual language).
- We propose to optimize a few random vectors, termed as continuous prompt.
- To bridge the gap between static images and videos, temporal information is encoded with lightweight Transformers stacking on top of frame-wise visual features.

- Motivation
- These large-scale pretrained models are powerful, but deploying fine-tuned models to many clients can also cause substantial storage and deployment costs.
- How do we adapt large- scale pretrained vision models on the downstream image classification datasets?
- Method
- KronA + Fastfood transform (Compactor).
- Selecting layers: We measure the local intrinsic dimension of each module in ViTs using Fastfodd transform motivated by compactors.
- Fastfodd transform: By performing experiments with gradually larger values of d, we can find the subspace dimension d t at which the performance of the model M reaches 90% of the full accuracy. 최소 d를 가지는 layer들에 대해서 아래의 KronA PEFT를 적용한다.
- Reparameterization: Kronecker Adaptation
- Results
- The local intrinsic dimension d_t to the attention module is lower than that of the MLP.
- We add Adapters in the attention layers.
- Around 45% parameters of LoRA (Hu et al. 2021) and 0.09% of all the model parameters in CLIP under the few-shot setting.

- Motivation
- MOCO, SimCLR, BYOL: Impressive performance have been achieved by CNN-based SSL.
- Aiming to improve the efficiency of Transformer-based SSL, this paper presents Efficient self-supervised Vision Transformers (EsViT).
- BERT (MAE)
- Sparse self-attentions (ex, Swin) can significantly reduce modeling complexity but with a cost of losing the ability to capture fine-grained correspondences between image regions.
- Method
- We believe that the SSL system efficiency is highly related to two ingredients: the network architecture and the pre-train task.
- Architecture: Swin Transformer (sparse self-attention module)
- New proxy task: A region-level matching objective
- Our L_R considers softmax with cross-entropy in the objective, rather than MSE (BERT, MAE).

9. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection_arXiv23
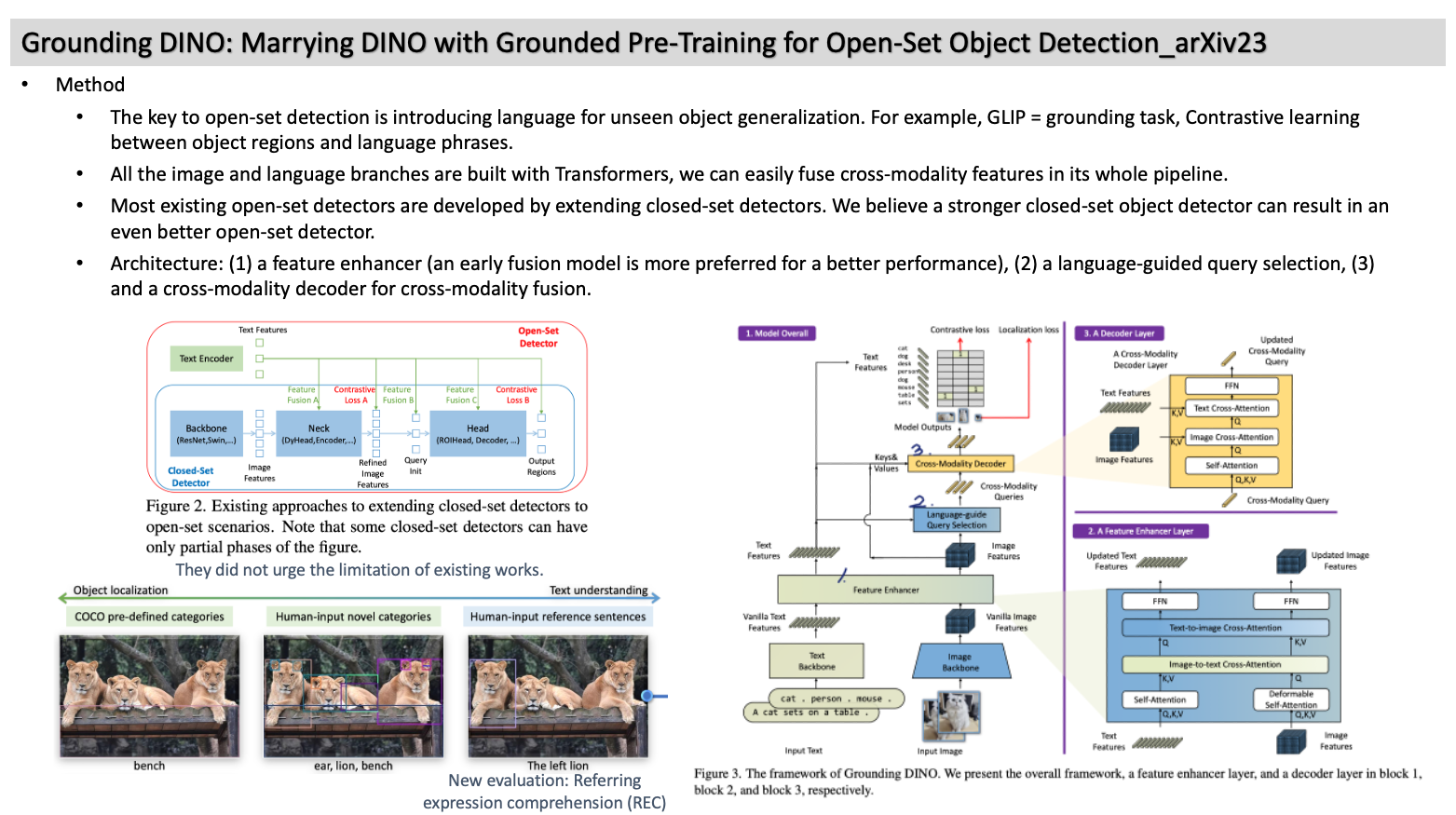
- Method
- The key to open-set detection is introducing language for unseen object generalization. For example, GLIP = grounding task, Contrastive learning between object regions and language phrases.
- All the image and language branches are built with Transformers, we can easily fuse cross-modality features in its whole pipeline.
- Most existing open-set detectors are developed by extending closed-set detectors. We believe a stronger closed-set object detector can result in an even better open-set detector.
- Architecture: (1) a feature enhancer (an early fusion model is more preferred for a better performance), (2) a language-guided query selection, (3) and a cross-modality decoder for cross-modality fusion.