[CVinW] Compution vision and Language papers 2
CVinW papers2
1. Fine-tuned CLIP Models are Efficient Video Learners_CVPR23
- Previous works
- Massive vision-language pretraining, such as CLIP and Lseg, is laborious for videos.
- Recent video-based approaches adopt additional learnable components while keeping the CLIP backbone frozen. However, these designs require modality-specific inductive biases (Image에서 잘 동작하는 CLIP이 Video에서 잘 동작하지 않음). = Fne-tuning pre-trained CLIP encoders along with the newly introduced temporal modeling components can hinder the generalization capability of CLIP.
- Method
- Full fine-tuning to achieve better visual-language alignment on videos improves synergy. (See Fig. 1)
- When applying full fine-tuning, our proposed ‘simple fine-tuning of CLIP’ is sufficient to learn video-specific inductive biases. (See Fig. 3)
- Furthermore, we propose a two-stage ‘bridge and prompt’ approach. 1) fine-tunes vanilla CLIP on videos to bridge the modality gap and 2) vision-language prompt learning approach (Fig. 6) in both visual and language branches of the CLIP model for low-data regimes.
- Note that CLIP fine-tuning is not always feasible, especially on low-data regimes.

2. Conv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets_arXiv22
- Motivation
- PEFT -> Computer vision
- To our knowledge, we are the first to systematically investigate the feasible solutions of general parameter efficient tuning (PET) for ConvNets. This investigation can narrow the gap between NLP and CV for PET.
- Method (See Figure 2 and Figure 3)
- Experimental results
- Among the four variants, Convolution Parallel achieves the best trade-off between performance and parameter efficiency.
- Conv-Adaptor with convolution Parallel strategy can be applied with ResNet50, ConvNext-B, and Swin-B and Swin-L.

3. Open-Vocabulary Panoptic Segmentation with MaskCLIP_arXiv22
- Motivation
- CLIP + Panoptic Segmentation
- The problem of open-vocabulary instance+panoptic segmentation has not been previously studied.
- An easy way to do this is simply masking or cropping the image and then sending the obtained image to the CLIP pre-trained image encoder. But it is not computationally efficient and also loses the ability to see the global image context information.
- Method
- To solve this, we propose Mask Class Tokens for efficient feature extraction from images without losing the global image context information.
- Our pipeline, shown in Figure 1, contains two stages. The first stage is a class-agnostic mask proposal network. The second stage is built on the CLIP ViT architecture.
- Evaluation: In this part, we train our proposed MaskCLIP method using COCO training data and test on other datasets under the open vocabulary setting.

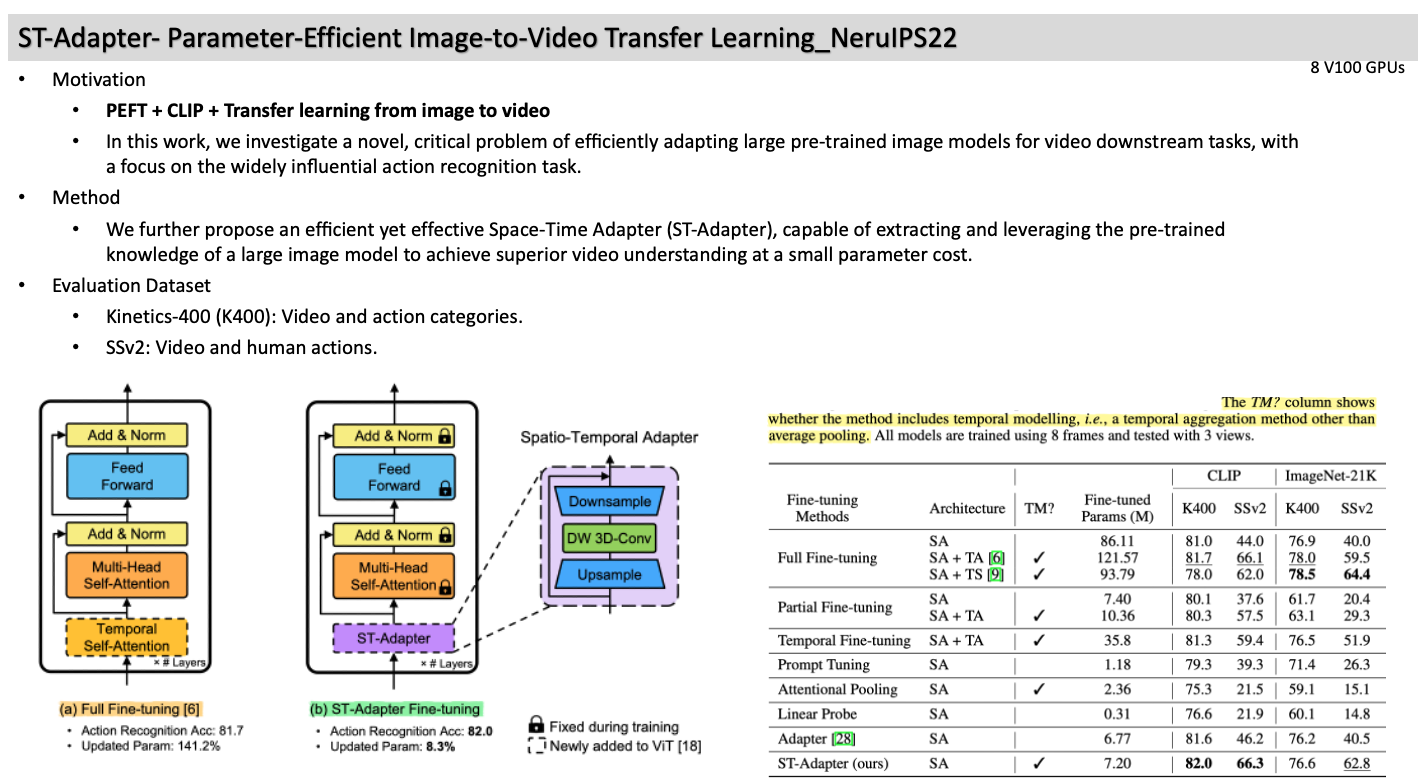
4. ST-Adapter- Parameter-Efficient Image-to-Video Transfer Learning_NeruIPS22
- Motivation
- PEFT + CLIP + Transfer learning from image to video
- In this work, we investigate a novel, critical problem of efficiently adapting large pre-trained image models for video downstream tasks, with a focus on the widely influential action recognition task.
- Method
- We further propose an efficient yet effective Space-Time Adapter (ST-Adapter), capable of extracting and leveraging the pre-trained knowledge of a large image model to achieve superior video understanding at a small parameter cost.
- Evaluation Dataset
- Kinetics-400 (K400): Video and action categories.
- SSv2: Video and human actions.
5. Polyhistor- Parameter-Efficient Multi-Task Adaptation for Dense Vision Tasks_NeurIPS22
- Motivation
- PEFT to Computer Vision tasks with Vision Transformers remains under-explored.
- A limitation of adapter + hierarchical vision transformers (HVTs): Adapter-based methods cannot be efficiently integrated with HVTs. (See Figure. 1 (c))
- We provide an extensive multi-task parameter-efficient benchmark for vision tasks.
- Method
- To overcome this issue, we propose Polyhistor and Polyhistor-Lite, consisting of Decomposed Hyper-Networks and Layer-wise Scaling Kernels, to share information across different tasks with a few trainable parameters.
- The hypernetworks include Template Kernels and Scaling Kernels, where these two kernels are multiplied via Kronecker Product.
- Multi-tasks specific adapter: Template Kernels shared by all tasks (See Figure 2 (b))
- Encoder: we use Swin-Transformer / Decoder: the All-MLP decoder of Segformer (for the number of output dimensions to different tasks)
- Experiment results
- We follow prior works on multi-task learning for dense prediction tasks: 21-class semantic segmentation, 7-class human part segmentation, surface normals estimation, and saliency detection.
- Compared with the state-of-the-art multi-tasking parameter-efficient adaptation method, Hyperformer, our method achieves competitive performance improvement with ∼ 90% reduction in the trainable parameters of their method.
