[Note] Hot papers in May 2023
HotPapers_May20
- Summary [src]
- The paper compares two self-supervised classes of methods for vision transformers, namely contrastive learning and masked reconstruction.
- Through several quantitative analyses of pre-trained models, the authors expose a series of findings on the learning properties of these methods.
- The main findings for contrastive learning are: it captures global low-frequency patterns, its intermediate representations are rather homogeneous, and self-attention is its key component.
- Conversely, for masked reconstruction, the main findings are: it focuses on local high-frequency patterns, its intermediate representations maintain diversity, and the MLPs are its key component.

- Motivation
- 1) Finetuning requires expensive human labels, and 2) distillation requires large amounts of unlabeled data which can be hard to obtain
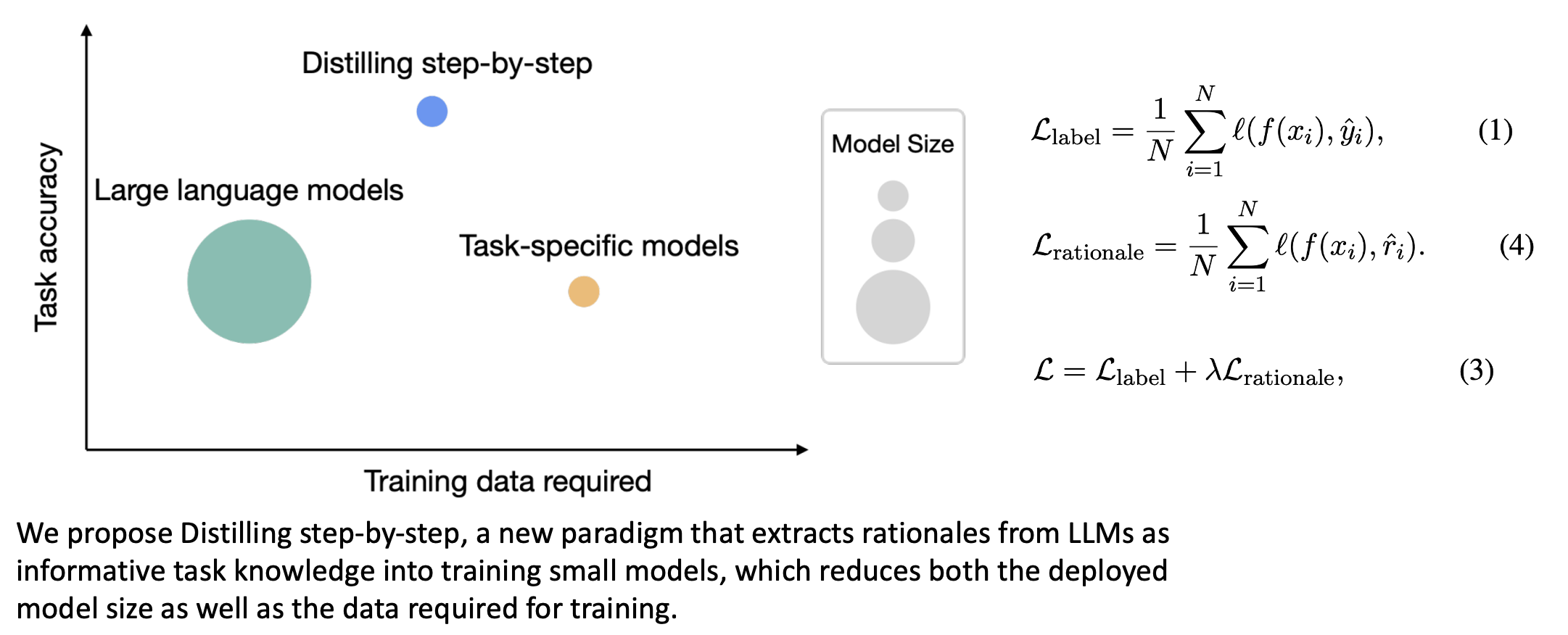
- We introduce Distilling step-bystep, a new simple mechanism for training smaller models with less (labled and unlabeled) training data.
- Method
- Core to our mechanism is viewing that LLMs can produce natural language rationales.
- (Details are in the paper) Step1. Extracting rationales from LLMs by utilizing Chain-of-Thought (CoT) prompting (Wei et al., 2022). Step2. Training smaller models with rationales
- Summary
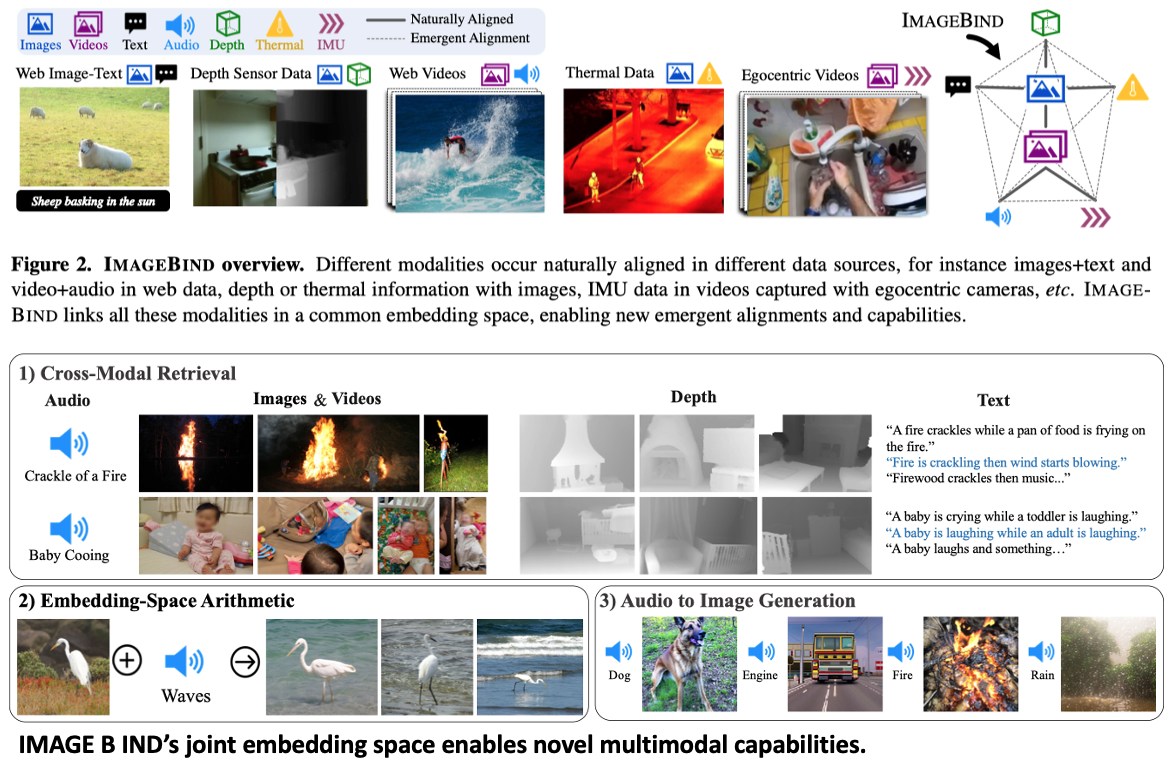
- Contribution: We show that all combinations of paired data are not necessary to train such a joint embedding, and only image-paired data is sufficient to bind the modalities together.
- Results: The emergent capabilities improve with the strength of the image encoder. We achieve a new state-of-the-art on emergent zero-shot recognition tasks.
4. Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime. VGG group and DeepMind, 2023.
- Introduction
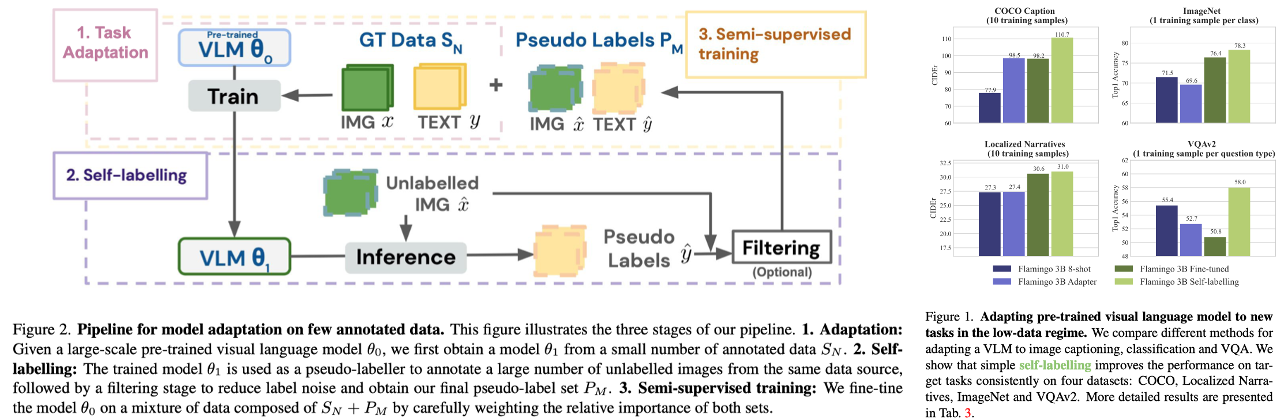
- While humans are known to efficiently learn new tasks from a few examples, deep learning models struggle with adaptation from a few examples.
- And we show the important benefits of self-labeling: using the model’s own predictions to self-improve when having access to a larger number of unlabelled images. >> Our work focuses on the data-efficient adaptation.
- Methods
- Fine-tunning: We start from Flamingo (which shows the pre-trained model can be adapted to new tasks with in-context learning.).
- Self-training: (1) train a pseudo-labeller, (2) use it to obtain pseudo-labels and then (3) re-train the original model using the pseudo-labels and the small amount of annotated data.
- Adapter: We follow the approach in [26] and add MLP adapter layers.
- Threshold: We choose the top N samples with the highest likelihood.
- My thought
- Main difference with DA: (a) conducting experiments on multiple tasks (2) using visual & language encoder (3) New setup: small labled data + large unlabed data
- Overfitting does not considered. (모든 UDA, Semi-supervised learning 에 적용할 수 있는 Regularization? De-overfitting 기법이 뭐가 있을까? Overfitting 이라는 표현이 맞나? 그냥 Collapes가 아닌가? 원인이 무엇인가?)
- Note that CLIP model has already the ability for zero shot prediction .
- Project page
- [Diff1] Unlike many recent reconstruction-based self-supervised learning methods, our model requires no fine-tuning.
- [Diff2] CLIP-based models ignores important information that typically isn’t explicitly mentioned in those text descriptions.
- [Approach1] Making progress from DINO to DINOv2 required overcoming several challenges:
- Creating a large and curated training dataset
- Two key ingredients: 1) discarding irrelevant images, 2) balancing the dataset across concepts
- 25 public datasets -> a set of seed images -> extending it by retrieving images (crawled web data) sufficiently close to those seed images -> producing 142 million images out of the 1.2 billion source images.
- Improving the training algorithm and implementation
- Challenge1: Increasing the model size makes the training more challenging because of potential instability. -> additional regularization 1, 2
- Challenge2: Larger models require more efficient implementations. -> Pytorch 2, xFormers
- Designing a functional distillation pipeline
- Model distillation allows us to compress our highest-performance architecture into significantly smaller ones at only a minimal cost in accuracy, for a dramatically decreased inference cost.
- [Result1] DINOv2 combines with simple linear classifiers to achieve strong results across multiple tasks beyond the segmentation sub-field.
6. Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning. ACL, 2023.
- In this paper, we systematically study the effect of catastrophic forgetting and mitigation strategies in a massively multilingual setting covering up to 51 languages on three different tasks.
- We propose
LR ADJUST. Our intuition is that models are susceptible to catastrophic forgetting when we provide a higher learning rate, so the learning rate should be toned down.
- Baselines for continual learning method are (1) Experienced replay, (2) Averaged GEM, and (3) Elastic Weight Consolidation (using fisher information matrix)

7. A Survey on Segment Anything Model (SAM): Vision Foundation Model Meets Prompt Engineering. arXiv, 2023.
- SAM
- SAM performs promptable segmentation, where the role of prompt behaves like attention.
- SAM exclusively solves mask prediction (not label prediction), which seem to be trivial task but contributes to the development of vision foundation model.
- Can SAN really segment anything?
- Projects (X anything)
- Grounded SAM
- SAM + Label
- Image editing
- Tracking in Video
- 3D
- Medical
