[Note] Hot papers in June 2023
HotPapers_June02
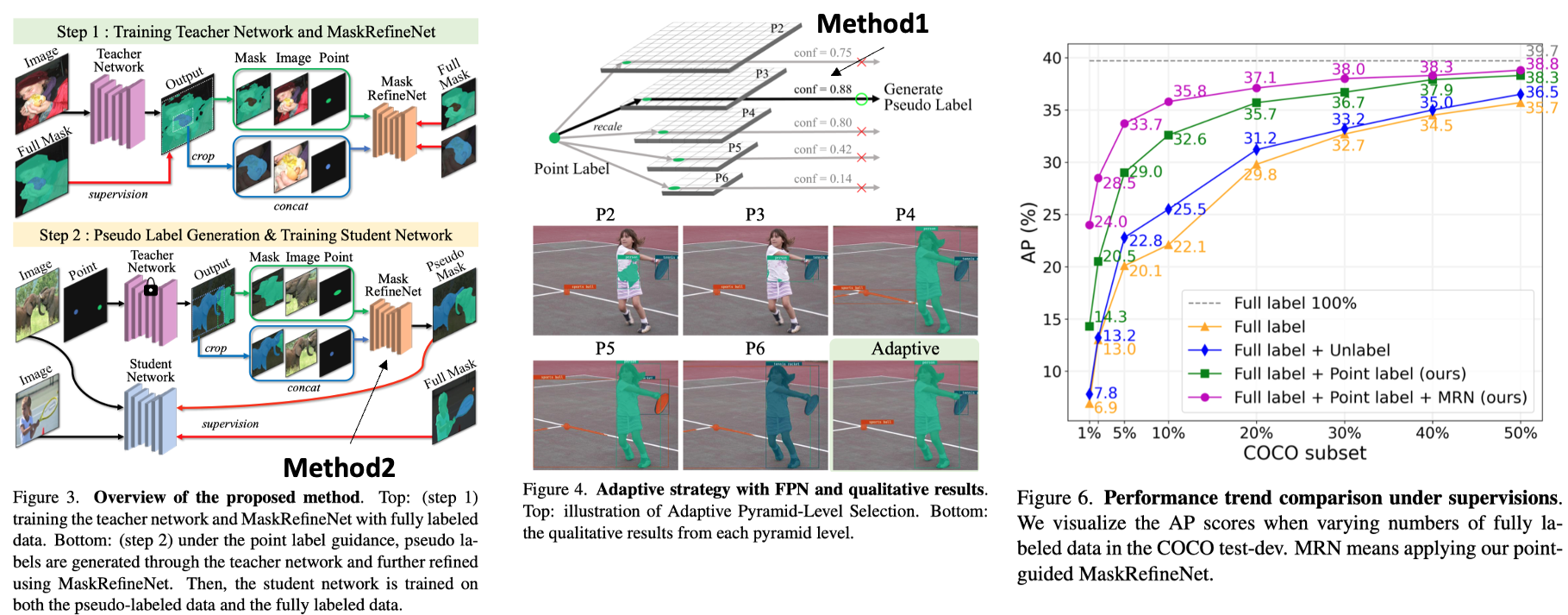
1. The Devil is in the Points: WS-SIS: Weakly Semi-Supervised Instance Segmentation via Point-Guided Mask Representation CVPR 2023
- [New task] We propose new task, Weakly Semi-Supervised Instance Segmentation (WSSIS).
- Weakly-supervised: using weak labels such as image-level, point, bounding box labels, Semi-supervised: using a part of labled data
- A few fully-labeled images and a lot of point-labeled images
COCO 10% means using 10% of the fully labeled data and the rest of 90% of the point labeled data. - We use a centroid point of an instance mask label as a point label.
- Training pipeline can be founded in Figure 3.
- [Method1] Adaptive Pyramid-Level Selection
- Motivation: point labels do not have instance size information.
- We rescale the coordinate of point labels according to the resolution of each level and extract confidence scores for all levels, as shown in Figure 4 (see
conf score).
- [Method2] Mask Refinement Network
- Motivation: when the amount of fully labeled data is extremely small (e.g., using only 1% images), the mask representation by the network would produce rough instance masks.
- Networks inputs: (1) image (2) rough mask from teacher networks (3) point heatmap (gausian kernel with a large sigma (ie, 6)) as shown in Figure 3.
- We expect that this networks learns how to calibrate common errors of predictions from the teacher network.
2. Self-Supervised Models are Continual Learners CVPR 2022
- [New task] In this paper, we tackle the same forgetting phenomenon in the context of SSL: called Continual Self-Supervised Learning (CSSL).
- [Evaluation] After each task, we train a linear classifier on top of the obtained backbone f b . With this linear classifier we report accuracy on the test set.
- 3 types of CL tasks: Class-incremental, Data-incremental, Domain-incremental
- [Method] Knowledge distillation with predictor: As shown in Figure 2, we propose to use a predictor network g to project the representations from the new feature space to the old one. (해석, 과거 모델을 그대로 Knowledge distillation하면 성능이 안 좋다. 그래서 current model에 predictor를 하나 더 붙여서 past model과 같은 예측을 하도록 만든다. Equ 5 참조)
- [Results]
- Table2: [31,18] Prior works [18, 31] that leverage knowledge distillation for CL are only mildly effective in a CSSL scenario.
- Table4: CaSSLe always improves with respect to fine-tuning. (CL setting에서 SSL만 적용하는 것보다 위에서 제안한 Knowledge distillation with predictor를 사용하는 것이 좋다.)

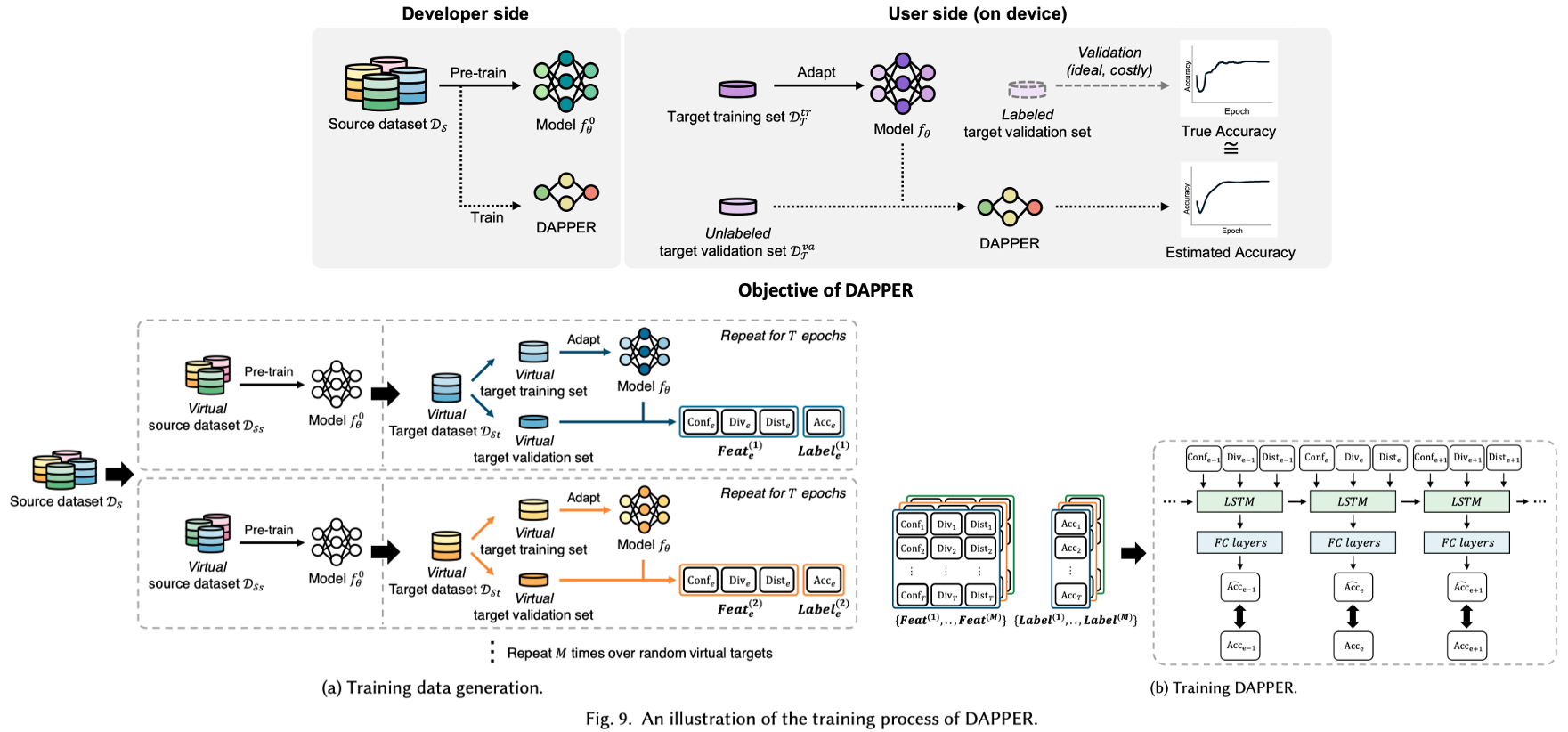
3. DAPPER: Performance Estimation of Domain Adaptation in Mobile Sensing arXiv21
- Introduction
- [Motivation1] We argue that accurately estimating the performance in untrained domains could significantly reduce performance uncertainty. (See Fig.1)
- Our objective is to estimate model performance (i.e., accuracy).
- Model outputs as a proxy of model performance
- Conf: Softmax score
- Div: Class의 diversify = entropy
- Dist: 현재 데이터 셋의 Class 분포 p = [p1, p2, p3,] p1= class1으로 예측된 이미지의 비율
- Method (DAPPER)
- 6 inputs: Conf, Div, and Dist, the difference from the previous values (Eq.10)
- Figure 6 (a) shows the prcess to generate datas for DAPPER.
- We utilize a conventional LSTM network as DAPPER architecture.
- Results
- [Fig.10] The estimated performance seems to be similar to the real accuracy calculated using the GT.
- [Fig.11] It shows the ablation study of inputs for DAPPER.
- [Note1] DA시에 성능 예측이 필요하다는 사실은 인트로에 잘 설명했다. 하지만 DAPPER을 구체적으로 어떻게 사용해여하는지에 대한 이야기가 없어서 아쉽다. 현재 성능을 예측하는게 의미가 부족할 수 있는 것이.. 언제 얼마나 좋은 이미지가 들어올지 예상할 수 없다. 현재 성능이 고점이라고 DA를 멈춘다고 차후 데이터에도 잘 반응한다는 보장이 있는가? 현재 상태가 고점이라고 어떻게 결정할 수 있는가? 주식마냥 조금 떨어지기 시작하면 DA를 멈추고 방금 전에 저장한 모델을 복구 해서 사용하는가? 언제 DA를 다시 시작하는가?
- [Note2] Figure 1에서 보면 UDA를 Client device에서 한다고 가정한다. TTA상황과 유사하다. 이런 점에서 생각해본다면 DA의 방향을 TTA상황으로 가정해서 보는게 맞는 듯 하다. 그리고 이 상황에서 Adaptation을 계속하면서 규제 기법을 적용하던가, 필요한 상황을 감지해서 양질의 자료만 사용하는 방법이 더 현실적인가?
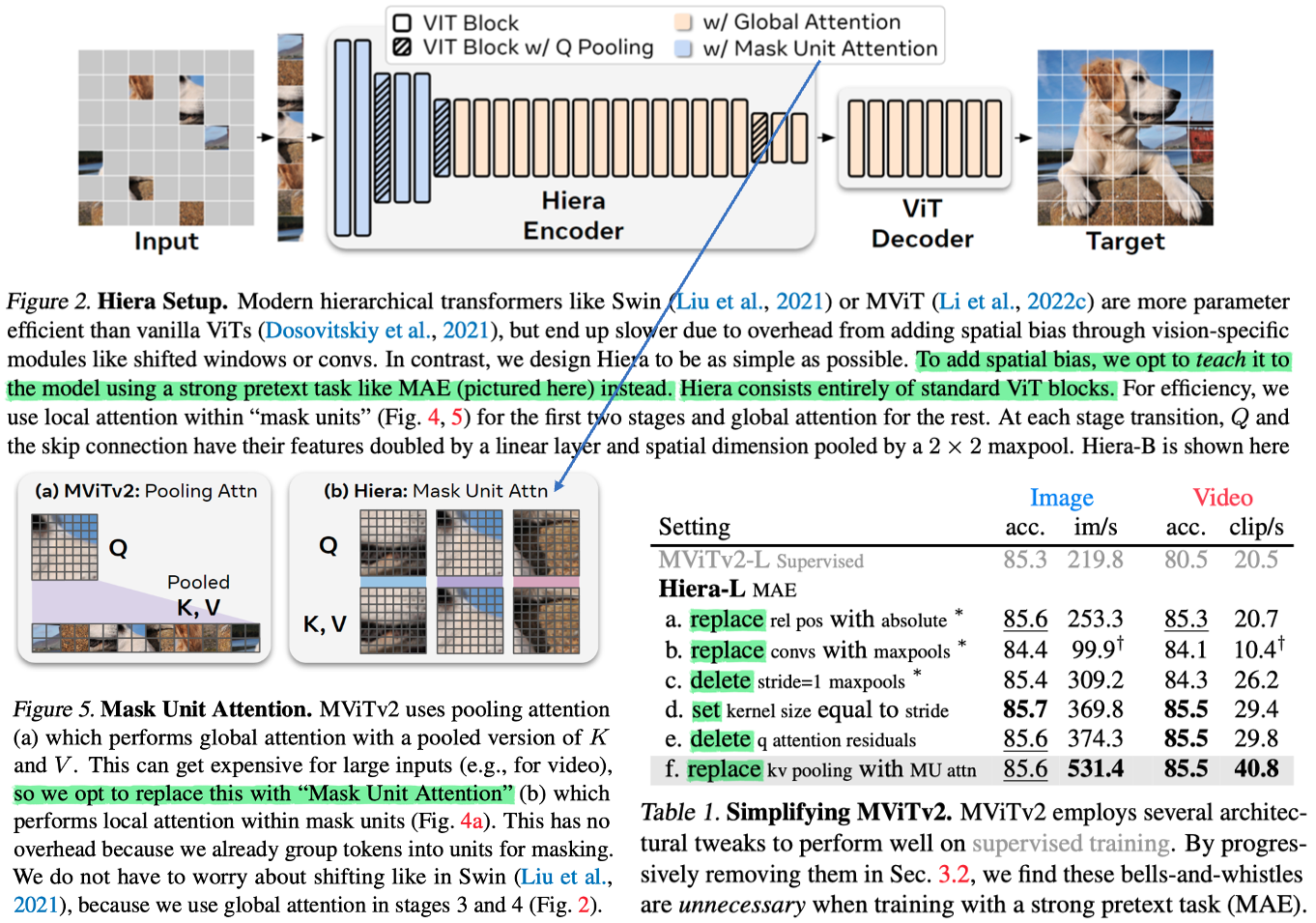
- This paper remove on unneccessary components of Swin and MViTv2, and instead apply MAE pre-training.
- Introduction
- [Motivation] Previous works add specialized modules to add inductive bias (e.g., crossshaped windows in CSWin (Dong et al., 2022), decomposed relative position embeddings in MViTv2 (Li et al., 2022c)). These complexity makes these models slower overall. We argue that a lot of this bulk is actually unnecessary.
- [Insight] MAE pretraining has shown to be a very effective tool to teach ViTs spatial reasoning.
- [Result] Just a pure, simple hierarchical ViT that is both faster and more accurate.
- Approach
- [Chanllenge] MAE makes pretraining efficient, but poses a problem for existing hierarchical models (Swin and MViT) as it breaks the 2D grid that they rely on. So, they propose how to calibrate MAE and hierarchical model step by step (see Table 1): e.g., Mask Unit Attention.
- Notes
- To remove the heavy process of self-attention, they use Masked unit attention & Global pooling. → The model is charge with MLP mixing and patchfing. (ViT Efficiency를 위해서 Archtecture를 뒤죽박죽하는게 큰 의미가 없겠다는 생각도 든다.)
5. Recognize Anything: A Strong Image Tagging Model arXiv 2023
- Introduction
- [Goal] RAM introduces a new paradigm for image tagging (=Multi-label image recognition), which aims to provide semantic labels by recognizing multiple labels of a given image.
- [Motivation1] The difficulty lies in collecting large-scale highquality data to train the model for image tagging.
- [Motivation2] There is a lack of efficient and flexible model design/framework.
- Method
- Label system: We begin by establishing a universal and unified label system.
- Dataset: We automatically annotate large-scale tagged images.
- Data Engine: Since the image-text pairs from the web are inherently noisy, we employ region clustering techniques to identify and eliminate outliers within the same class to filter out tags that exhibit overllaped predictions.
- Model: Tag2Text which has superior image tagging capabilities by the integration of image tagging.
- [Note] 차오닝이 다음과 같은 이야기를 했다: "SAM의 발전이 무섭다. 중국에서는 SAM을 빠르게 dominate하려 노력하고다. SAM = masked prediction = Vision foundation model 이라고 봐야한다." 현재 Label prediction 방법들은 정말 구식의 방법이 될까? User's gaze Video를 보면 여러가지 생각이 든다.

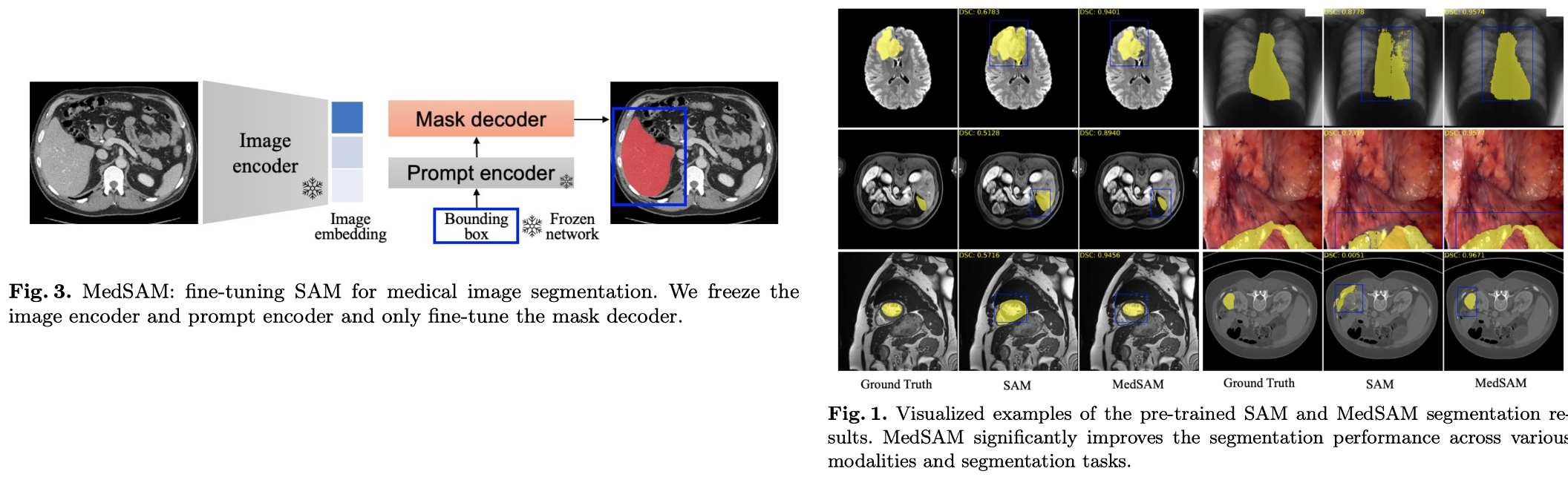
6. Segment Anything in Medical Images arXiv 2023
- [Motivation] Segment anything model (SAM) has limited performance on medical image.
- [Approach1] We first curate a large-scale medical image dataset, encompassing over 200,000 masks across 11 different modalities.
- [Approach2] We develop a simple fine-tuning method to adapt SAM to general medical image segmentation.
5. Others
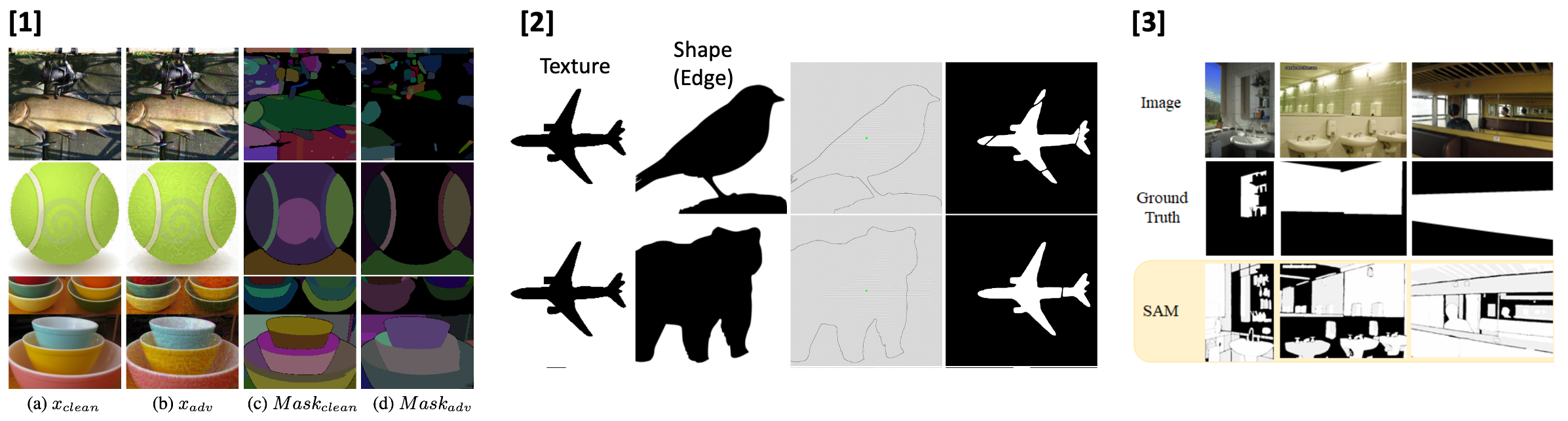
- Attack-SAM: Towards Attacking Segment Anything Model With Adversarial Examples arXiv 2023
- [Finding] SAM can also be fooled by adversarial attacks.
- Segment Anything Model (SAM) Meets Glass: Mirror and Transparent Objects Cannot Be Easily Detected arXiv 2023
- [Finding] SAM has sub-optimal performance to detect things in challenging setups like transparent objects.
- Understanding Segment Anything Model: SAM is Biased Towards Texture Rather than Shape arXiv 2023
- [Finding] SAM is strongly biased towards texture-like dense features rather than shape.