[DA] Papers for Source-free Domain Adaptation 1
0628_SFDA
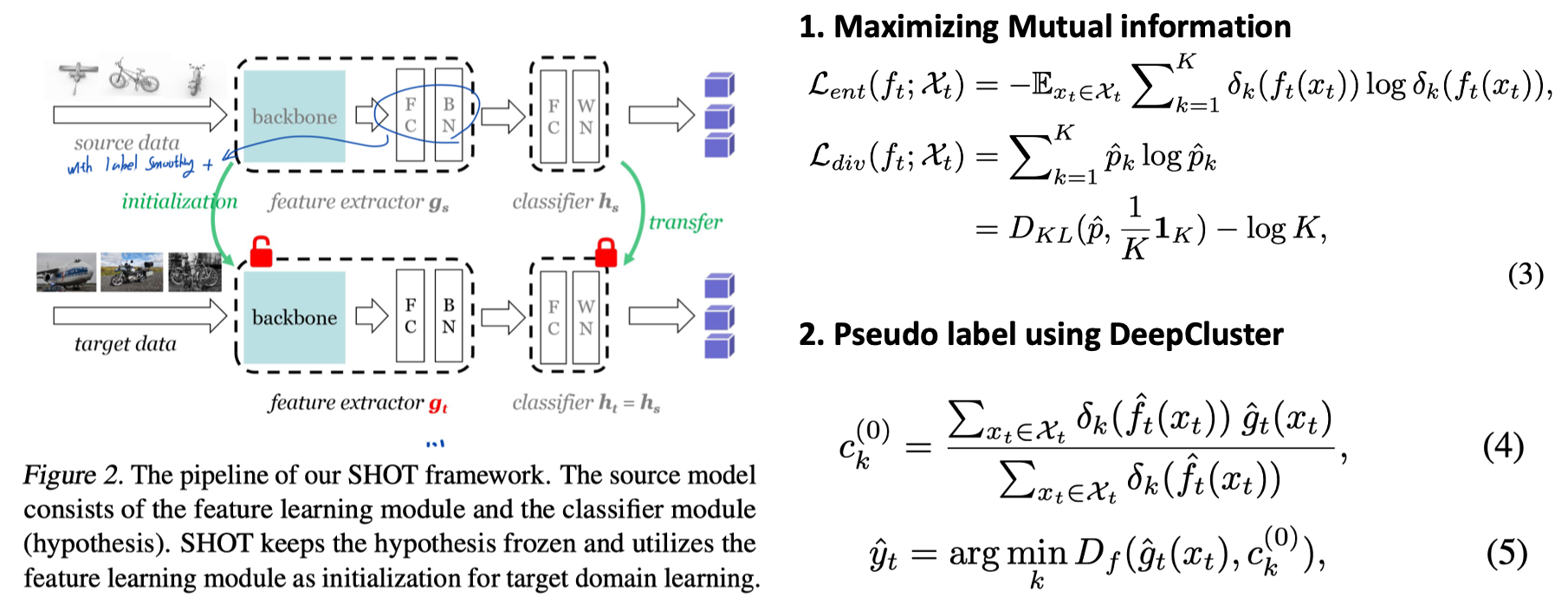
1. SHOT: Do we really need to access the source data? ICML, 2020.
- Method
- During source model training, (1) we adopt label smoothing, (2) we adopt WN and FC back at the encoder.
- [Method1] SHOT freezes the source classifier (=hypothesis) and fine-tunes the source encoding module by maximizing the mutual information(IM). (See Equ. (3)) The IM loss works with entropy minimization and the diversity-promoting objective.
- [Method2] In order to obtain cleaner pseudo labels, we use one technique from self-supervised learning (i.e., DeepCluster). We first attain the centroid for each class and then compute the sufficiently good pseudo labels. (See Equ. (5,6))
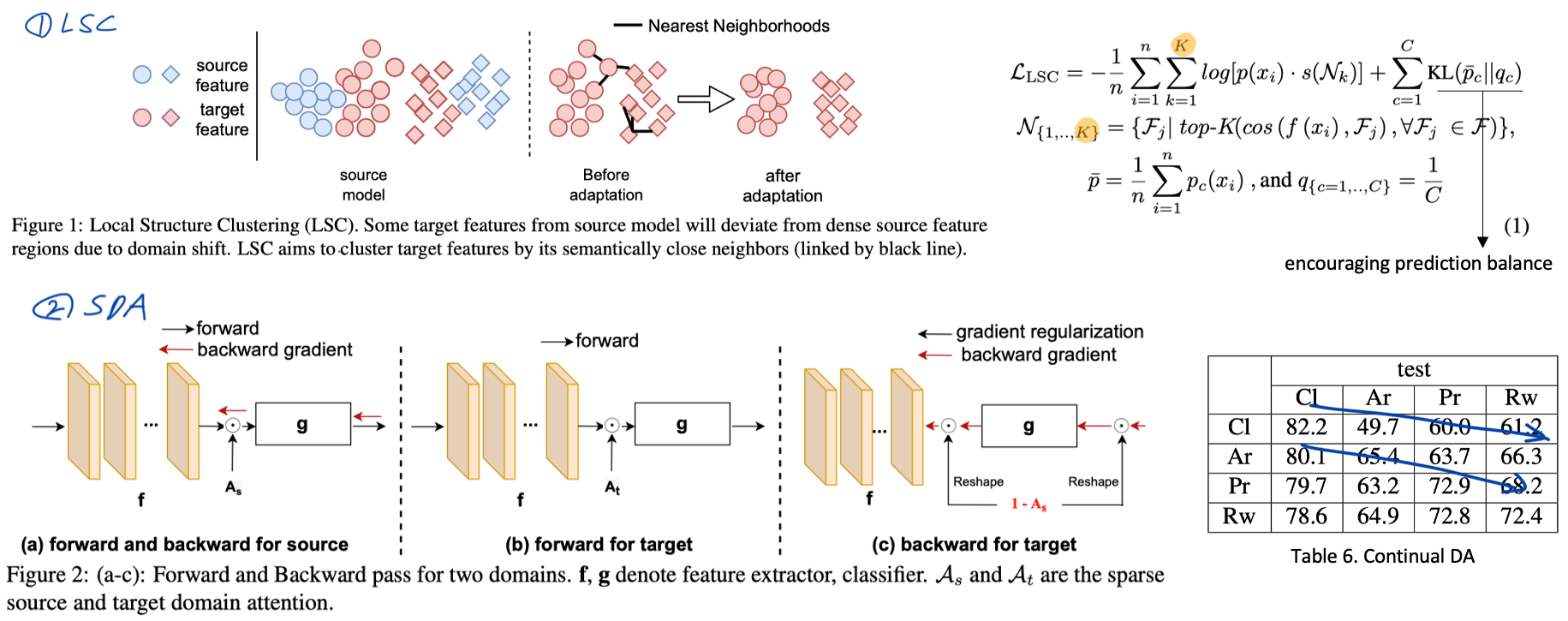
2. Generalized source-free domain adaptation. ICCV, 2021.
- Motivation
- Previous methods do not consider keeping source performance.
- Method
- [Local Structure Clustering]
- Mot.1: we expect that classes in target dataset still form clusters in the feature space.
- Mot.2: The nearest neighbors of target features have a high probability to share category labels.
- We build a feature bank F and only use a few neighbors from the feature bank to cluster the target features with a consistent regularization, which is different from previous works using NN.
- [Sparse Domain Attention]
- We propose to only activate parts of the feature channels of f(x) ∈ R^d for different domains,
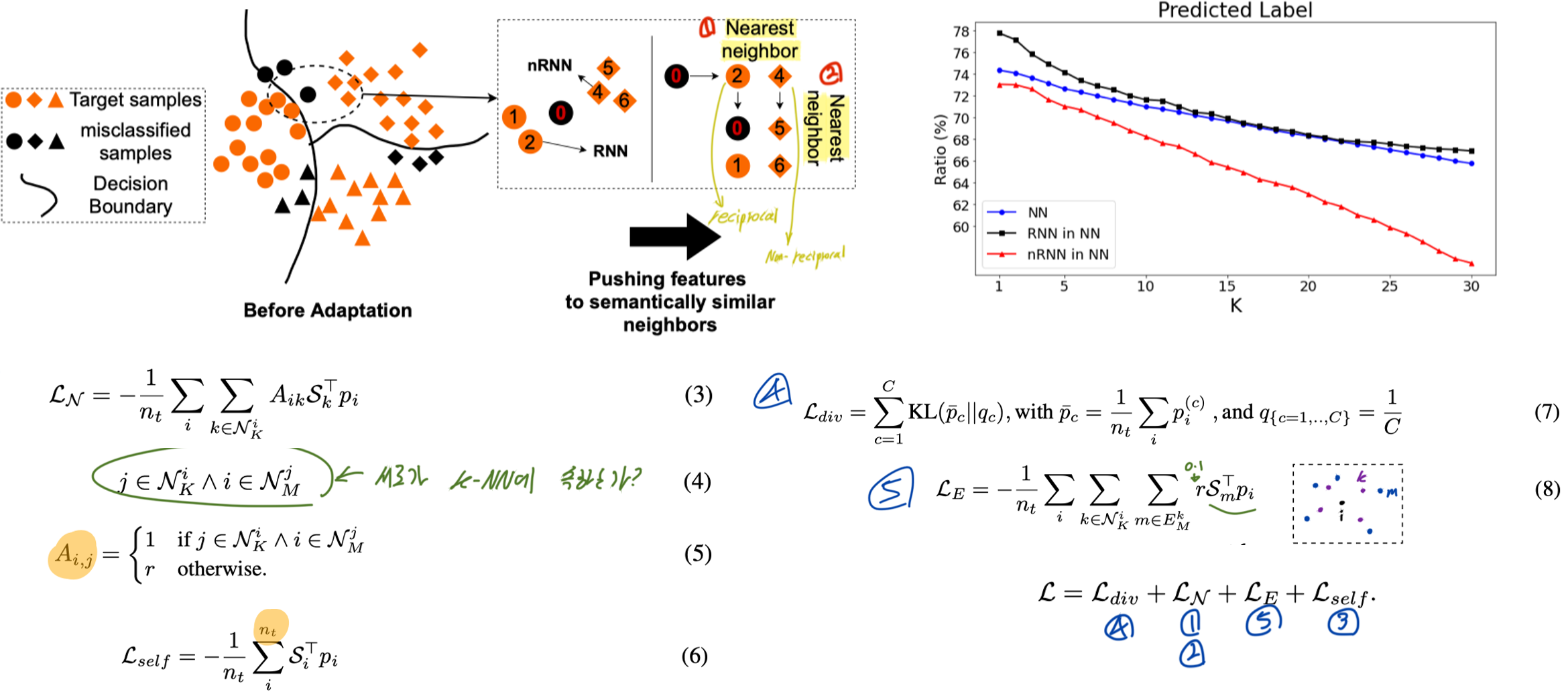
3. Exploiting the intrinsic neighborhood structure for source-free domain adaptation. NeurIPS, 2021.
- Motivation
- Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. The nearest neighbors of points are expected to belong to the same class. However, this assumption is not enough to create refined-pseudo labeld. So, we consider reciprocal nearest neighbors (RNN=두 point가 neighbors로 서로를 포함함).
- Methods
- Encouraging Class-Consistency (See Equ. (4,5)) with Neighborhood Affinity (See Equ. (7))
- To further reduce the potential impact of noisy neighbors in N K , which belong to the different class but still are RNN, we propose a simply yet effective way dubbed self-regularization. (See Equ. (6))
- Expanded Neighborhood Affinity (See Equ. (8))
- A better way to include more target features is by considering the M-nearest neighbor of each neighbor in N_K, i.e., the expanded neighbors. (내 친구의 NN = E_M)
4. Test-time training with self-supervision for generalization under distribution shifts. ICLR, 2020.
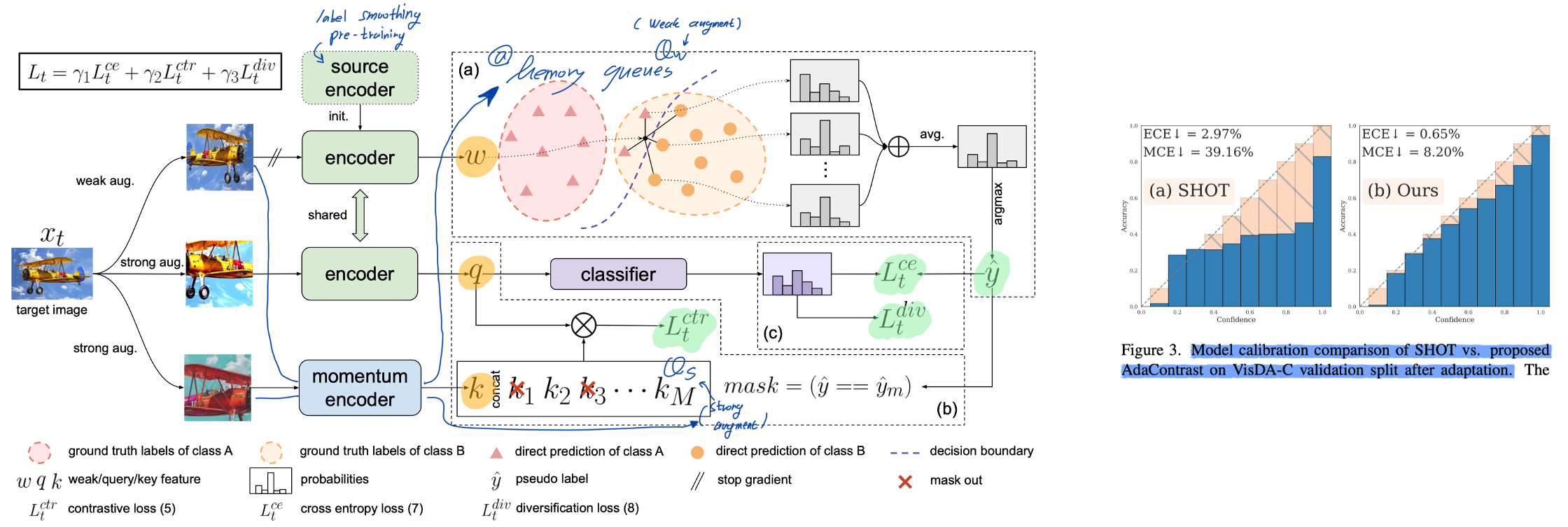
5. Contrastive test-time adaptation. CVPR, 2022.
- Method
- Supervised Contrastive learning + Test-time Adaptation
- [Mot.] The intuition is that a better target representation facilitates learning the decision boundaries, while the useful priors contained in pseudo labels further enhance the effectiveness of contrastive learning.
- Online pseudo label refinement by using soft k-nearest neighbors.
- [Mot.] The current classifier makes incorrect decisions for some target samples due to domain shift; however, we can get a more informed estimate by aggregating knowledge of nearby points.
- Weak-strong consistency inspired by FixMatch.
- Diversity Regularization to encourage class diversification.
- Experiments
- [Fig.3] We calculate two scalar summary statistics of calibration.
- Specifically, we show performance with queue size M ∈ { 128, 256, · · · , 32768, 55388 } and number of neighbors in soft voting N ∈ { 1, 2, 3, 6, 11, 21, 41 }. While we report the strongest results of AdaContrast in Tab. 1 with memory size M = 55388, queue update, and N = 11 nearest neighbors for soft voting.
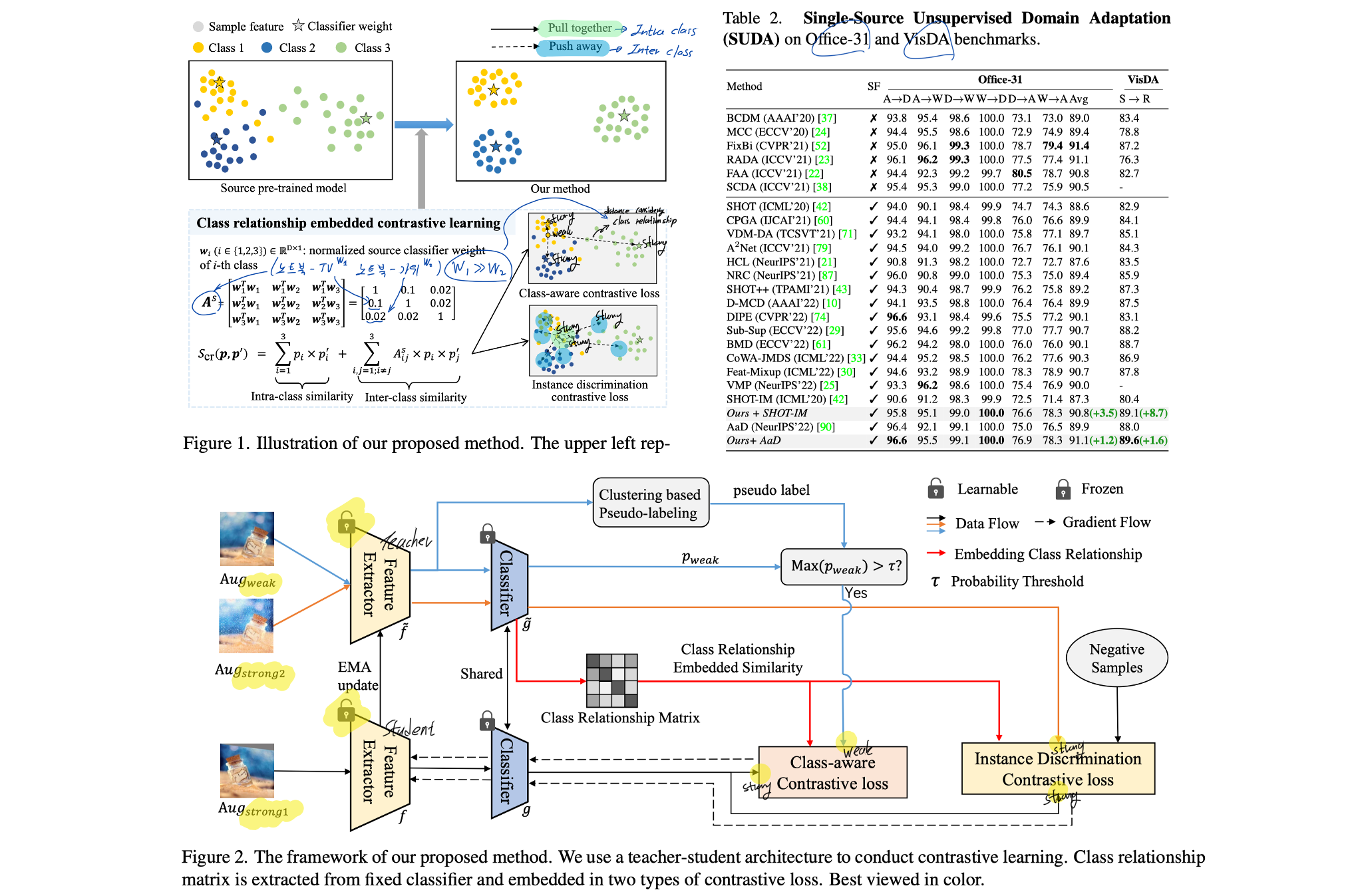
6. Class Relationship Embedded Learning for Source-Free Unsupervised Domain Adaptation. CVPR, 2023.
- Relative works for SFDA가 잘 정리된 것 같으니, 참고.
- Method
- Class Relationship Embedded Similarity
- [Motivations] The class relationship is domain-invariant since the same class in the source and target domains essentially represent the same semantic in spite of domain discrepancy. (TV-노트북 관계가 source and target domain 모두 동일하다. Fig. 1 참조)
- Class relationship을 고려해 두 샘플 사이의 거리를 계산하는 방법이다. 이 거리 계산 방법을 아래의 Contrastive loss 적용에 사용한다.
- Class Relationship Embedded Contrastive Loss (See, Figure 1)
- Class-Aware Contrastive loss: Equation (4) is actually the FixMatch loss [67]. Although FixMatch can improve performance, our CR-CACo loss can greatly outperform it since we consider class relationship.
- Instance Discrimination Contrastive loss: Here, we use the probabilities p s1 and ′ of two strong augmented views from the same image as positive pairs.
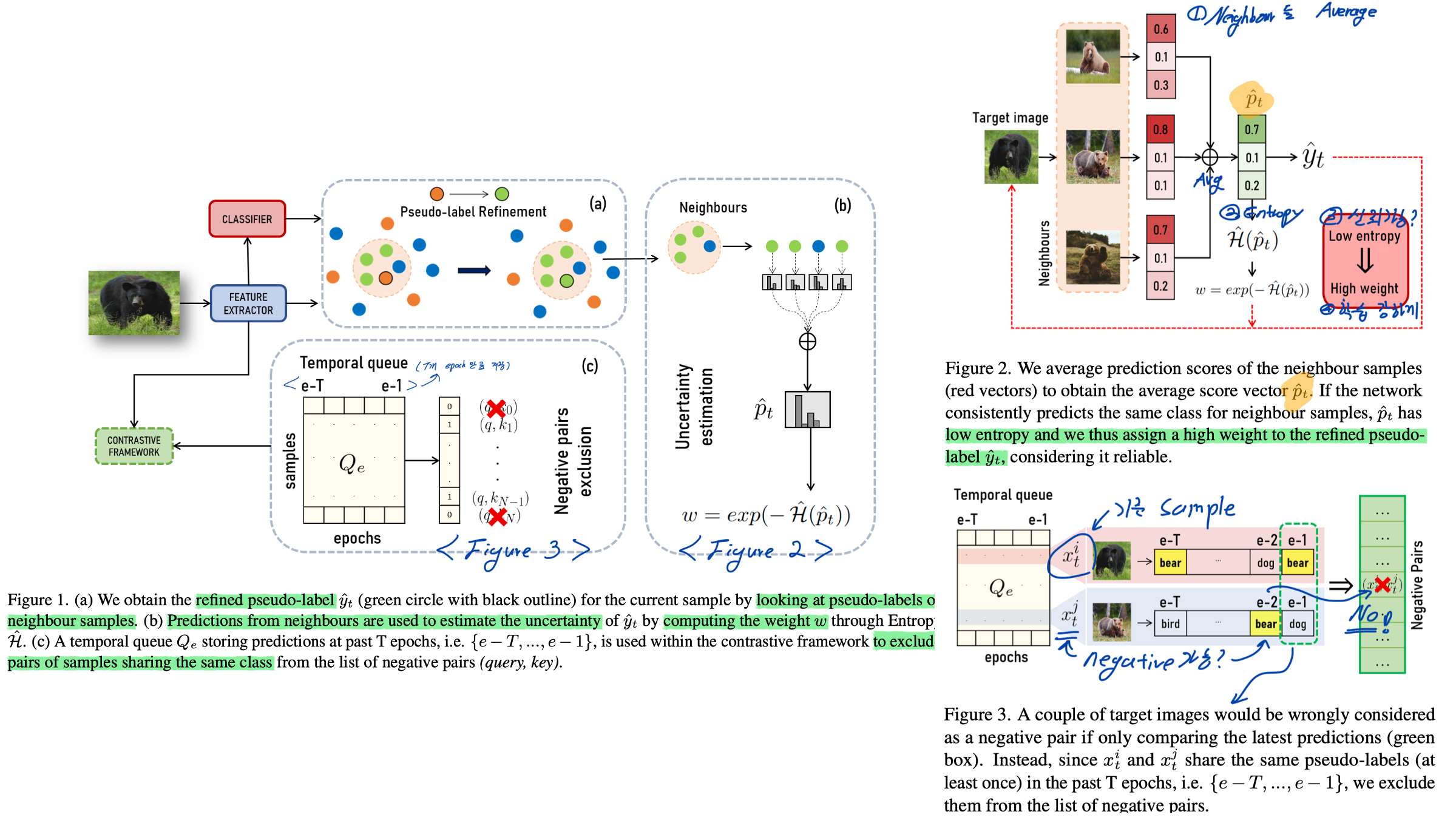
7. Guiding Pseudo-labels with Uncertainty Estimation for Source-free Unsupervised Domain Adaptation. CVPR, 2023.
- 기본 베이스라인으로 사용하기 좋은 페이퍼, Code
- Method
- [See Fig. 2] Pseudo-label Refinement via Nearest neighbours Knowledge Aggregation
- [See Fig. 2] Loss Reweighting with Pseudo-labels Uncertainty Estimation
- [See Fig. 3] Temporal Queue for Negative Pairs Exclusion
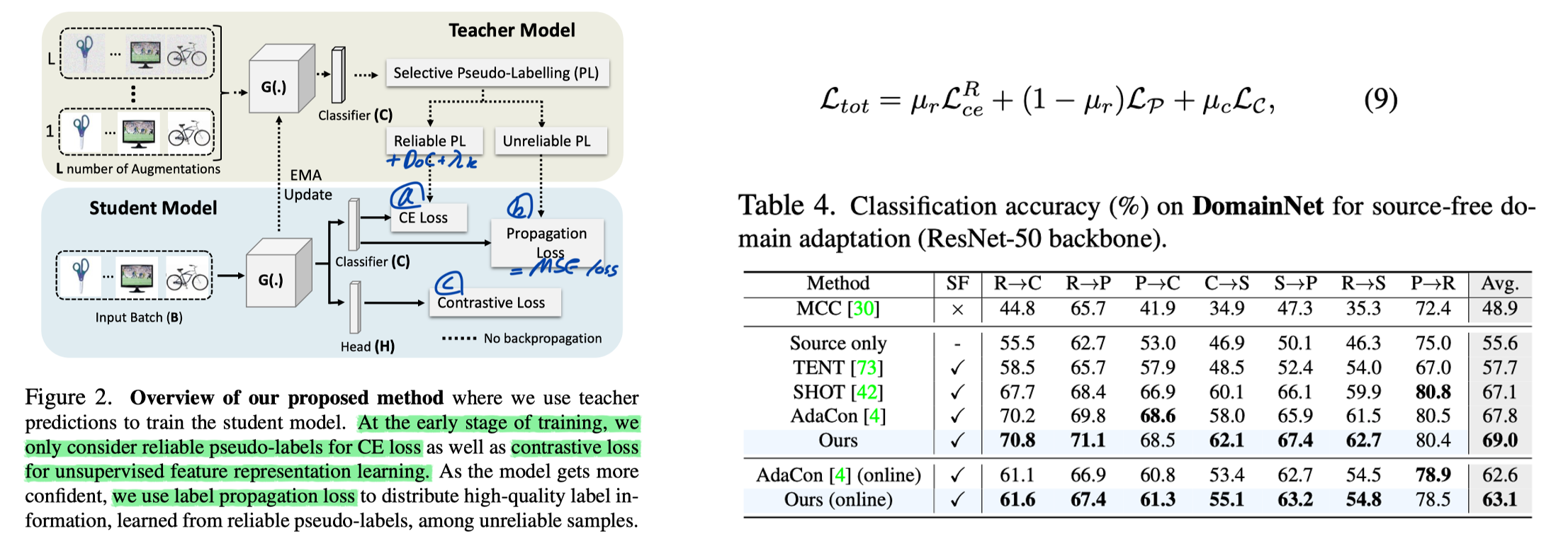
8. C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation. CVPR, 2023.
- Motivation
- Recent SOTA methods suffer from two issues: i) inevitable occurrence of noisy pseudo-labels and ii) refinement process requires maintaining a memory bank.
- So, we focus on increasing the reliability of generated pseudo-labels without using a memory-bank and clustering-based pseudo-label refinement.
- Method
- Selective Pseudo-Labelling
- To measure the label reliability, we intend to exploit i) prediction confidence and ii) average entropy or uncertainty. (See Equ. (4))
- Loss Functions
- CEloss + Propagation loss (MSE loss) + Supervised Contrastive loss (BYOL, SimSiam loss, not MoCo)
- Curriculum Learning
- Gradually decreasing µ_r and µ_c
- Notes
- Segmentation 성능이 경험상 저렇게 나올리가 없다. 뭔가 이상하다. 제안한 메소드 사용하나도 안하고, Entropy loss 와 Pseudo labeling with threshold 만 사용한다. 그래 일단 핵심만 정리해둔다. Self-sup loss도 SimSiam을 해놔야지 SimCLR을 해놨다. 엉망징창 논문.
- Augmentation, Contrastive learning, Teacher student model 을 요즘 SFUDA에서 엄청 사용한다. 특히 Contrastive learning을 조금 더 섬세하게 바꾸는 연구들이 CVPR에 많은 것 같다. Novel하진 않지만, 실험양으로 찍어 누른 느낌이다. 그래서 이런 방향은 마음에 안든다.
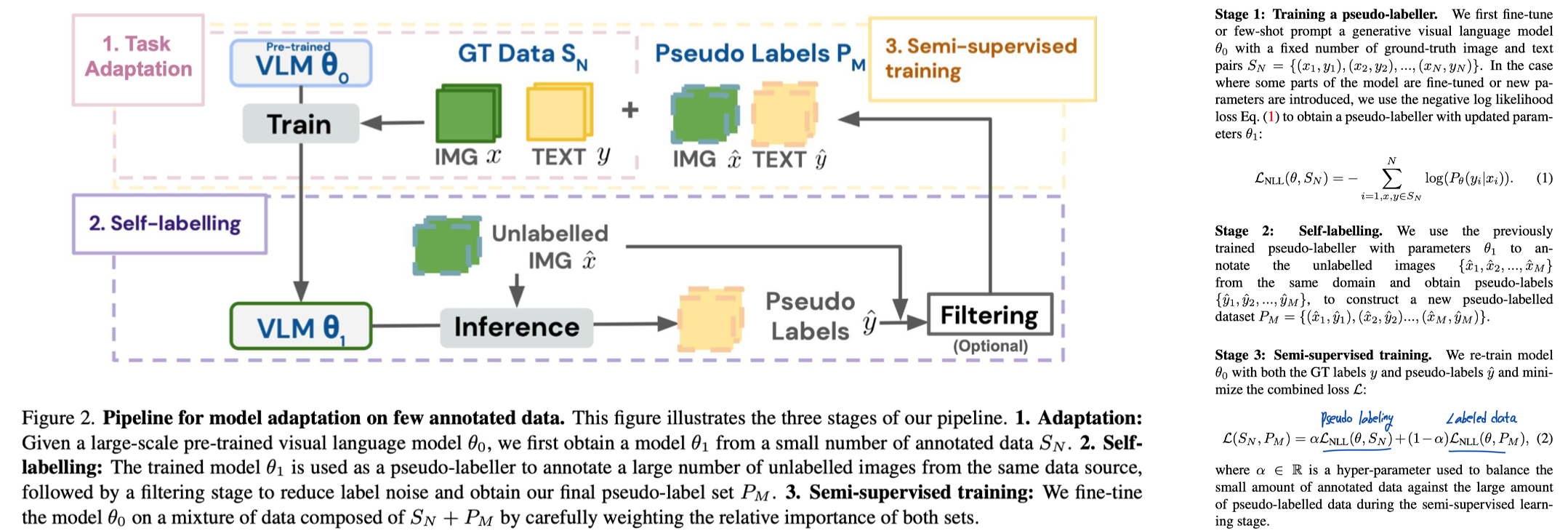
9. Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime. VGG of Oxford, Deepmind, 2023.
- Semi-supervised Domain Adaptation
- Motivation
- While humans are known to efficiently learn new tasks from a few examples, deep learning models struggle with adaptation from few examples.
- How to adapt to a new task as few as 10 annotaed images.
- Considerations. 1) PEFT 2) General adaptation technique (not only specific for image classification)
- Method
- We start from Flamingo, a powerful baseline for in-context learning (= The pre-trained model can be adapted to new tasks.).
- (1) train a pseudo-labeller,
- (2) use it to obtain pseudo-labels and then
- (3) re-train the original model using the pseudo-labels and the small amount of annotated data.
- Image Classificaiton Experiments
- (Semi-sup) We assume that the model only has access to a limited number of annotations for training and validation.
- We follow the approach in [26, PETA for NLP] and add MLP adapter layers