[CVinW] Computer Vision in the Wild 1
- 2개의 Workshop (CVinW, VFoundationM) 에서 소개되는 내용들을 정리한다. 그래서 Section 2, 4에서 같은 논문이 적혀있을 수 있다.
- 논문들을 정리한 포스트는 다음에 위치한다..
Computers/projects/Google_blog_posts/AI/1230_CVinW2.md
Computer vision in the wild
- Limitation: Visual recognition models are typically trained to predict a fixed set of pre-determined object categories, which limits their usability in real-world applications since additional labeled data are needed to generalize to new visual concepts and domains.
- Interest in the vision-language model:
- Open-vocabulary recognition models can effortlessly adapt to a wide range of downstream computer vision (CV) and multimodal (MM) tasks. / The pre-trained CLIP model is so semantically rich that it can be easily transferred to downstream image classification and text-image retrieval tasks in zero-shot settings.
- As language supervision significantly increases the coverage of visual concepts for model training, model generalization is improved.
- Dataset: ELEVATER (project, paper)
- Challenges: Classification, Detection, Segmentation, Roboflow(Detection+)
1. ELEVATER (model adaptation, paper, github)
2. Open-vocabulary recognition
- REACT: Learning Customized Visual Models with Retrieval-Augmented Knowledge. CVPR, 2023.
- RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection. NeurIPS, 2022.
3. Efficient Adaptation (Awesome)
- 위에 논문들 재밌다. 유용하다. 의미있다. 하지만 나의 리소스로 연구 가능한지 모르겠다. 논문들 전체를 보고 GPU사용량을 확인해보자.
- VL-PET Vision-and-Language Parameter-Efficient Tuning via Granularity Control. ICCV, 2023.
- Adapter is All You Need for Tuning Visual Tasks. Alibaba, summited to CVPR, 2024.
- PLOT: Prompt Learning with Optimal Transport for Vision-Language Models. ICLR, 2023.
Vision Foundation Model
- Talk1: Recent Advances in Vision Foundation Models (Apple, Senior researcher. ZheGAN)
- CLIP 이후 vision-langage 모델(for Image classification)의 능력을 향상시키기 위해, Data-Archtecture-Objective 관점에서 어떤 노력들이 있었는지 요약한다.
- Interesting papers
- STAIR: Learning Sparse Text and Image Representation in Grounded Tokens. Apple, EMNLP, 2023. (Model design 관점)
- K-lite: Learning transferable visual models with external knowledge. NeurIPS, 2022. (Data 관점)
- Lit: Zero-shot transfer with locked-image text tuning. CVPR, 2022. (Model design/Training 관점)
- 느낀점: 많은 회사에서 좋은 Foundation 모델을 만들기 위한 노력을 수행 중. 다만, 학생 레벨로 하기엔 어려움 있음.
- Talk2: Towards Unified Vision Understanding Interface
- Computer vision researcher로써, 해당 연구의 큰 흐름을 잡아준 것 같다. 앞으로도 열린 길이 많다고 이야기하는데, 어떤게 있을지 고민이 필요한 것 같다.
- Interesting paper
- DETR → Mask2Former
- [Langage-driven] → CLIP, Alevater
- [Task-specific] → GroupViT / MaskCLIP, ECCV22, MaskClip,CVPR23 / OpenSeg / Open-MaskCLIP
- [Output Unification] → UniTab, Pix2Seqv2 / Unified-IO. ICLR, 2023.
- [Functionality Unification] → Uni-Perceiver v2 / GLIP / X-decoder. MS, CVPR, 2023.
- [Promptable interface] → SAM / SEEM. MS, NeurIPS, 2023. / FIND. MS, 2023. / LISA, submitted to ICLR24.
- → What is the next?
- Talk4: Large Multimodal Models: Towards Building and Surpassing Multimodal GPT-4
- Vision (CLIP), Language encoder들을 각각 다른 Task에서 Pre-training해놓고, 서로를 연결하는 방식을 차용한다. 대표적인 논문으로 Flamingo, BLIP-2가 있다.
- GPT4 어떻게 만든지 모른다. 하지만 차근이 이해, 예측해보자. 1) Instruction tuning, Self-instruction, 2) language-only to multi-modal.
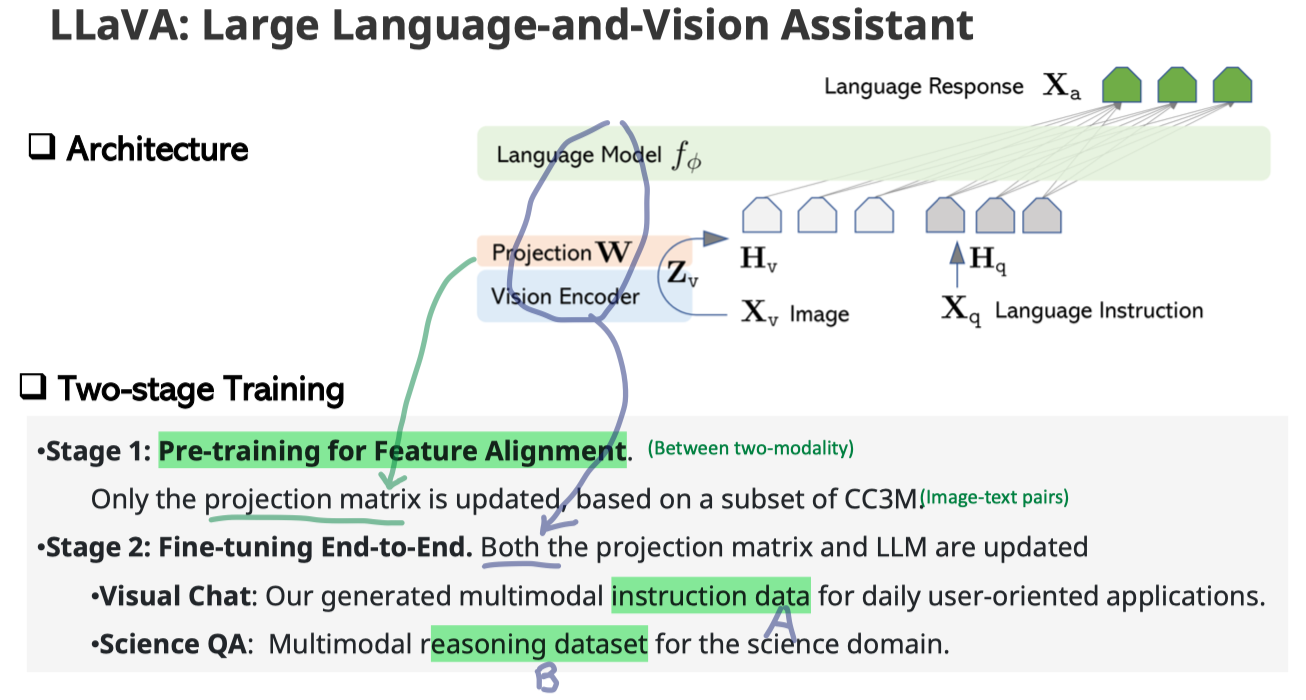
- Multi-modal chatbot을 위해서 다음과 같은 Instruction-dataset을 구성할 수 있다. 1) captions (detailed description) 2) box sequence 3) caption-base generated (?) conversation 4) complex reasoning (이미지 안의 숨겨진 의미 = the implications of the image, Science QA데이터셋이 존재한다.)
- Archtecture 및 학습 절차는 아래 사진과 같다.
- Further research ditections: 1) More modalities 2) Multitask instrct with academic tasks 3) MultiModal in-incontext learning, OpenFlamingo 4) Parameter-Efficient Training 5) Object hallucination, OCR, Reading high-resolution image, Specific-domain knowledge (medical, physics)
- Talk5: Chaining Multimodal Experts with LLMs
2. [DeepMind, Apple] Vision-Language Models
- Ferret: Refer and Ground Anything Anywhere at Any Granularity. Apple, 2023.
- VeCLIP: Improving CLIP training via visual-enriched captions. Apple, 2023.
- Contrastive Feature Masking Open-Vocabulary Vision Transformer. DeepMind, ICCV, 2023.
- RECLIP: Resource-Efficient Clip by Training with Small Images. DeepMind, TMLR, 2023
- Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers. DeepMind, CVPR, 2023.
6. Questions
- 그래서 데이터셋은 어떻게 다운 받지?
- Pretrained model, Foundation model은 어디서 다운 받지?
- Tuning/Adaptation을 위한 데이터셋으로 뭐가 있지?