51 Papers Related to Computer Vision in the Wild.
1. Imege-output
1.1 Task-specific Vision Models (5 papers)
◽️ DETR: End-to-End Object Detection with Transformers. FAIR, ECCV, 2020.
◽️ MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation. FAIR, NeurIPS, 2021.
- Their model performs panoptic segmentation using DETR operation + semantic segmentation.

◽️ Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation. FAIR, CVPR, 2022.
- Mask2Former sets a new state-of-the-art for panoptic segmentation, instance segmentation and semantic segmentation.
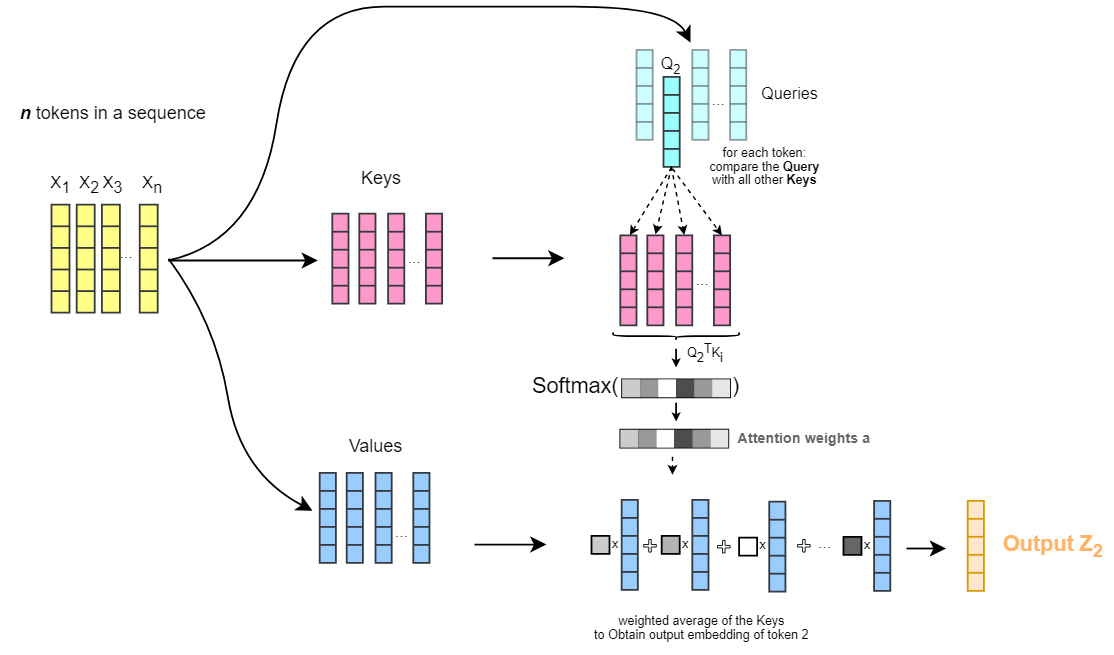
- Cross-attention에 대한 코드를 본다면, 여기 구현을 보는게 가장 깔끔할 듯. (learnable query가 q로 들어가고, image feature가 k, v로 들어가는 구조)

◽️ Pix2seq: A Language Modeling Framework for Object Detection. Google, ICLR, 2022. 206
- Closed-set object detector! / Google post, Github
- Motivation: The complexity of Faster-RCNN and DETR arises when trying to identify or localize all object instances while also avoiding duplication.
- Arch: the Pix2Seq model outputs a sequence of object descriptions: consisting of the bounding box's corners and a calss label.
- Method: 1) quantization and serialization to generate sequences of discrete tokens for bounding boxes and class labels. 2) The objective function is simply the maximum likelihood.

◽️ 🔒UniTAB: Unifying Text and Box Outputs for Grounded Vision-Language Modeling. MS, ECCV, 2022. 61
1.2 Langauge-Image Pretraining (7 papers)
◽️ CLIP: Learning Transferable Visual Models From Natural Language Supervision
◽️ ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
◽️ Florence: A New Foundation Model for Computer Vision

◽️ Interpreting CLIP's Image Representation via Text-Based Decomposition ICLR 2024
- Finding
- We find that ablating all layers but the last 4 attention layers has only a small effect on CLIP’s zero-shot classification accuracy.
- We present an algorithm for labeling the latent directions of each head with text descriptions.
- 나만의 설명으로 정리
- [Section3.3] 마지막 4개 layers의 MSA가 text embedding과 매칭시키는 가장 큰 역할을 한다. (이해 완료)
- [Section4.1] 마지막 4개 layers의 MSA의 각각의 head는 자신만의 text 구분력을 가진다. (예를 들어, 23번째 layer, 3번쨰 head는 색갈을 구분하는 능력을 가진다.) 논문의 CLIP-ViT-L에 대한 해석 결과를 제공한다. 이를 찾아내는 방법이 복잡한 듯 보이지만, 어렵지 않다 (60% 이해). 코드까지 보면 금방 이해할 듯 하다.
- [Section4.2] 이 특성을 이용해서 1) water-bird에서 좋은 성능을 가지는 방법을 만들 수 있고, 2) reference이미지와 유사한 이미지를 빠르게 찾아내는 것도 가능하다.
- [Section5] 이 특성을 이용해, GradCAM 보다 더 좋은 attention map 추출기를 만들 수 있다.
◽️ Big Self-Supervised Models are Strong Semi-Supervised Learners. Google, NeurIPS, 2020.
- FixMatch, FreeMatch에서 사용하는 unsupervised loss는 대부분 self-supervised loss(consistency regularization)이다. 이게 semi-supervised learning에 좋다는 것을 처음으로 보인 논문.
- 학습 Steps (1) unsupervised pretraining of a big ResNet model using SimCLRv2 (2) supervised fine-tuning on a few labeled examples (3) distillation with unlabeled examples for refining and transferring the task-specific knowledge

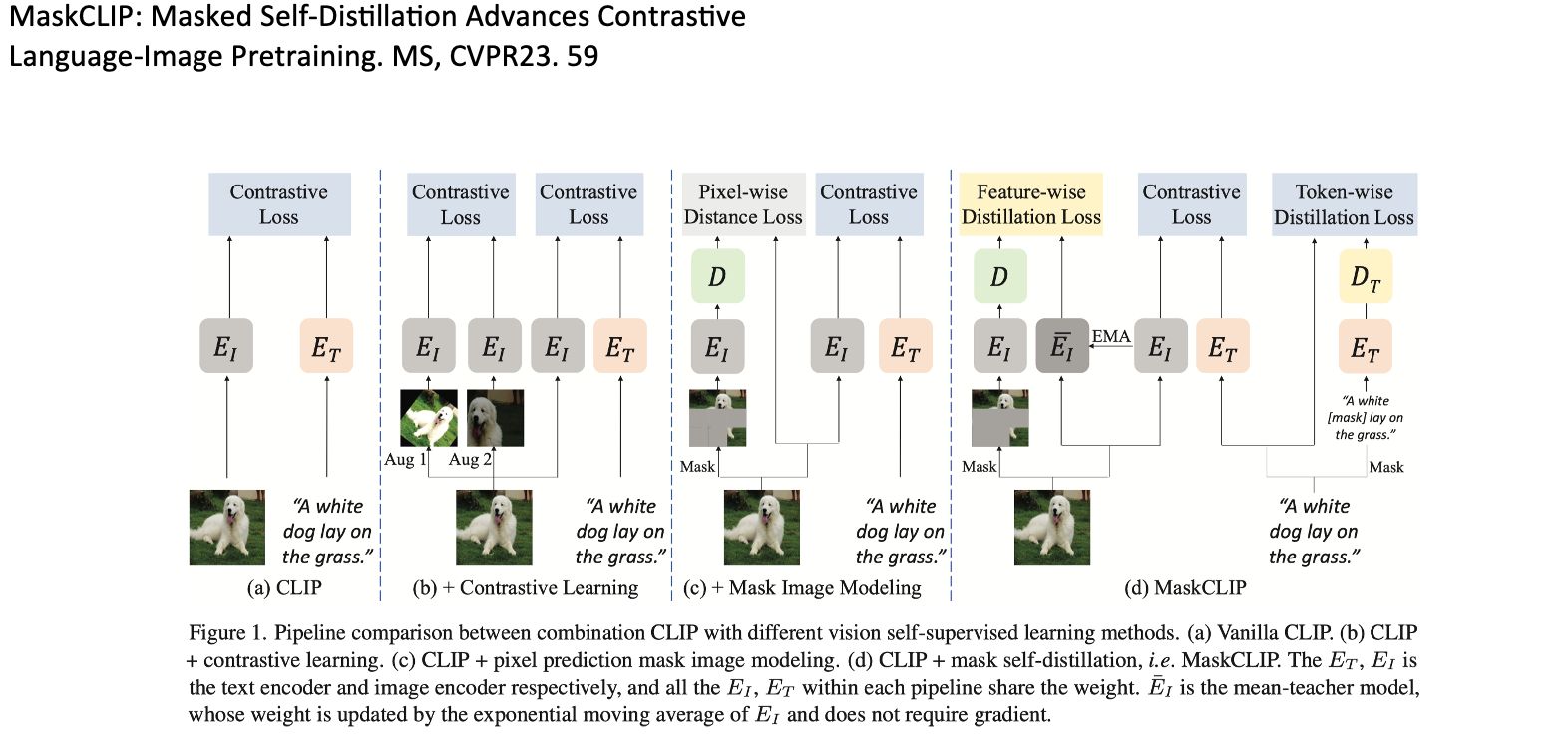
◽️ MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining. MS, CVPR23. 59
- 여기서 Mask는 Masked Image modeling을 의미한다. / 코드 공개 한다 했지만, 8개월 째 안한게.. 아쉽다.
- 1) Image-level masked autoencoder, 2) text-level masked autoencoder 3) text-image contrative learning
◽️ ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models. NeurIPS dataset&benchmarks track, 2022.
- Contributions: Benchmark (20,35 개 데이터셋을 모아놓은 것) & Toolkit (Dataloader와, Foundation 학습 알고리즘 구현)
- ImageNet, LAION-5B 으로 pretraining 하고 나서, CIFAR에서 Zero, Few, Full-shot task에 모두 잘 동작하는 Foundation 모델을 만들겠다는게 이 논문의 목적이다
- 만약 이것을 이용한다면, Foundation model을 20개 데이터셋에 각각 adaptation 하기 위한 좋은 인사이트를 제공해주는 논문을 만들어보면 좋을 것 같다. -> Zero-shot에서 어떻게 pretrained-weight(27page) 가져오는지 찾아보고, 그 weight를 source model으로 사용하고 싶다.
1.3 Task-specific Langauge-Image Pretraining (14 papers)
task-specific:Classification → Object dection, Segmentation- 아래 논문들은 Foundation model 제작을 위한 contrastive-lanuage-image-pretraining 을 사용하는 논문들.
- 아래 논문들의 단점은, 정확한
category_name_string이 Text input으로 주었을 때 detection이 이뤄진다는 점이다 (i.e., laugauge-driven recognition). 여기서 나올 수 있는 Question은 image captioning 처럼 그냥 알아서 detect & discribe은 못하나?, CVinW의 철학 관점에서 이게 맞는가? 라는 것 들이다. - Presentation material:
Onedrive/Davian/Study/Lab_semina/Computer_vision_for_robots.pptx
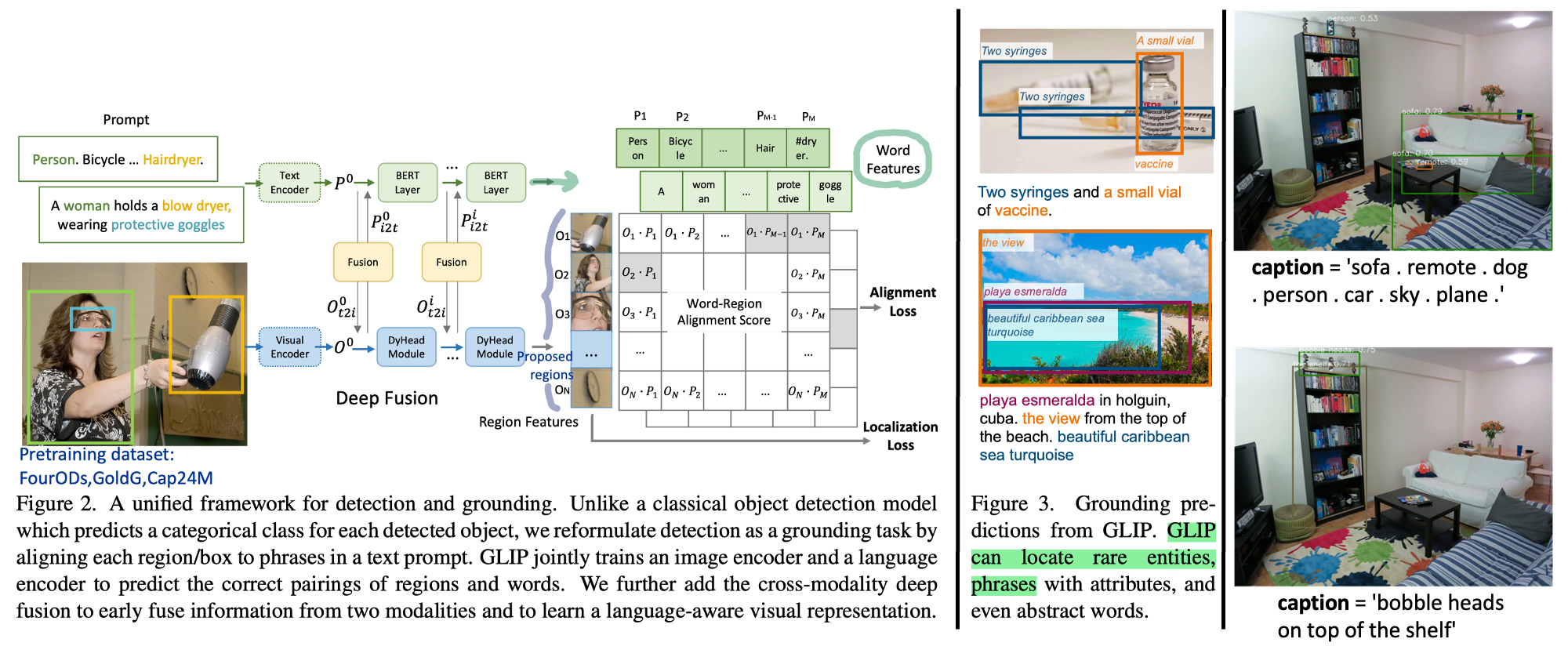
◽️ GCLIP: Grounded Language-Image Pre-training. MS, CVPR22. 626
- CLIP 모델의 Object detection 버전.
Grounding: Word-to-region matching - Our approach unifies the phrase grounding and object detection tasks in that object detection can be cast as context-free phrase grounding. (의미는, 아래 그림 참조)
- Unsupervised learning with massive image-text data: Teacher GLIP generates boxes-text pairs and student GLIP is trained on them. (Figure3)
- Dynamic Head라는 SOTA detection모델을 기반으로, 모델이 구현된다. Figure2에서 여러개의 Dynamic head를 통과하는 것은.. (논문을 안 읽어 확실하진 않지만) Self-attention을 통해 box (location)들이 re-fine되는 과정이라고 생각하면 될 듯 하다.
- Typical object detection 모델은 Loss가 2개이다. Classification loss and Localization loss. 전자만 alignment loss로 바뀌었다고 생각하면 된다.
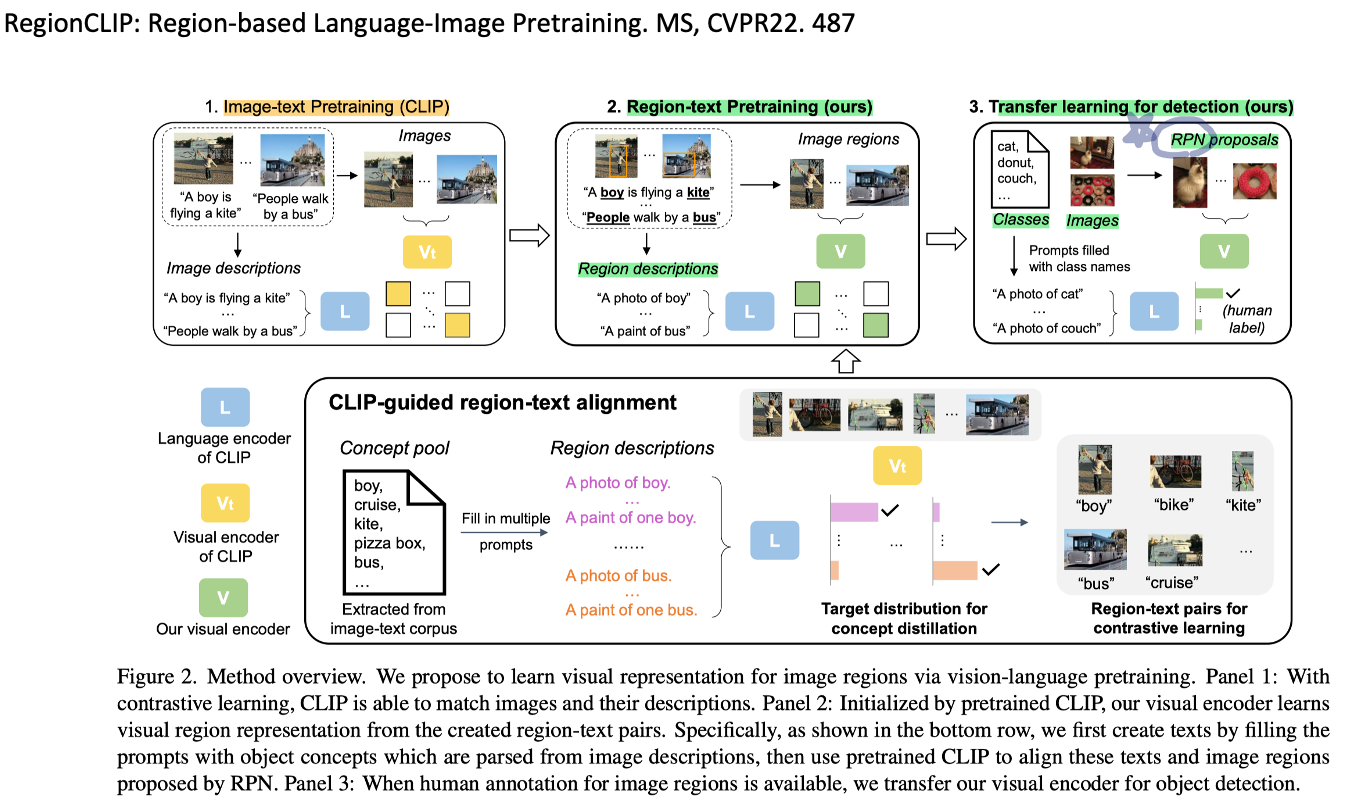
◽️ RegionCLIP: Region-based Language-Image Pretraining. MS, CVPR22. 329
- CLIP 모델의 Object detection 버전.
- CC3M (conceptual caption dataset) 데이터셋, Image encoder, CLIP text encoder, Region proposal networks (RPN) 을 잘 사용해서, Image/region-text contrastive learning을 수행. 그리고 COCO, LVIS의 Detection task에서 transfer learning 비교 실험 수행.
◽️ ViLD: Open-vocabulary Object Detection via Vision and Language Knowledge Distillation. Google, ICLR22. 593
- 위 기법과는 다르게, CLIP image encoder가 뽑아주는 feature를 그대로 따르는 distillation loss를 줌으로써, CLIP의 open-vocabulary 능력(CLIP이 이해하는 모든 voca를 다 사용할 수 있는 능력)을 사용하고자 노력했다.
- Proposal networks가 어떻게 학습되는지, N, M proposasls의 구체적 생성 등을 구체적으로 어떻게 하는지 헷갈린다.
- Demo: 데모에서 흥미로운 점은, 각 Class마다 Confidence score 차이가 크지 않다는 점이다.
- GCLIP, RegionCLIP과의 차이점은 CLIP의 novel categories 능력을 차용할 수 있다는 점이다. 아래 Figure3 처럼 학습 방식도 다름.

◽️ Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. 492.
- Motivation: Figure1의 Caption 참조. But, REC(referring expression comprehension)을 위한 특별한 Approach는 없다.
- Approach: vision-language features를 최대한 여러번 Attention 시켜준다. 1) feature enhancer 2) language-guide query selection 3) cross-modality decoder.
- self-attention, cross-attention에 대한 코드(github) 확인해보면 좋을 듯. 단, 학습 코드는 공개 안됨.

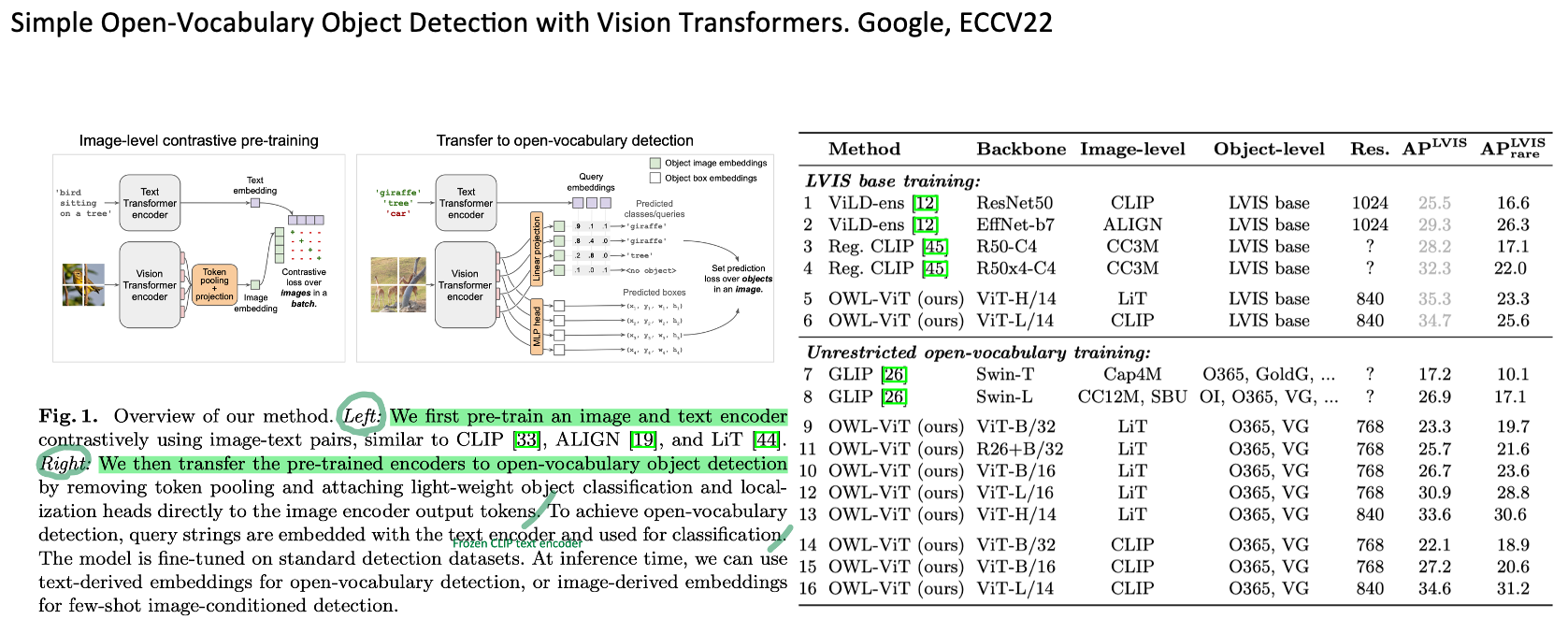
◽️ Simple Open-Vocabulary Object Detection with Vision Transformers. Google, ECCV22. 193
- LVIS dataset로 CLIP 학습을 한 후, COCO, O365 datasets로 detector를 (supervised) pre-trianing 하는 방식이다.
- Demo: Open-set object detector, One-shot image-conditioned detection
{kind=link}
{kind=link}
◽️ GroupViT: Semantic Segmentation Emerges from Text Supervision. UCSD, CVPR22. 257
- 이전 Post 설명 자료 (link)
- Segmentation을 위한 text-image contrastive learning임에도 불구하고 pixel-level operation 이 없다 (segmentation labels를 사용하지 않는다.). Group query가 알아서 pixels들을 grouping 해주기를 기대한다.
- Grouping Block: Image embeding과 group query 들의 cross attention.
◽️ Lseg: Language-driven Semantic Segmentation. ICLR22. 305
- 이전 Post 설명 자료 (link)
- Inter-annotator consistency becomes an issue when objects are present in an image that could fit multiple different descriptions or are subject to a hierarchy of labels.
- Segmentation labels 사용. / ViLD 처럼 CLIP image encoder아니라, CLIP frozen text encoder를 distillation 하는 느낌
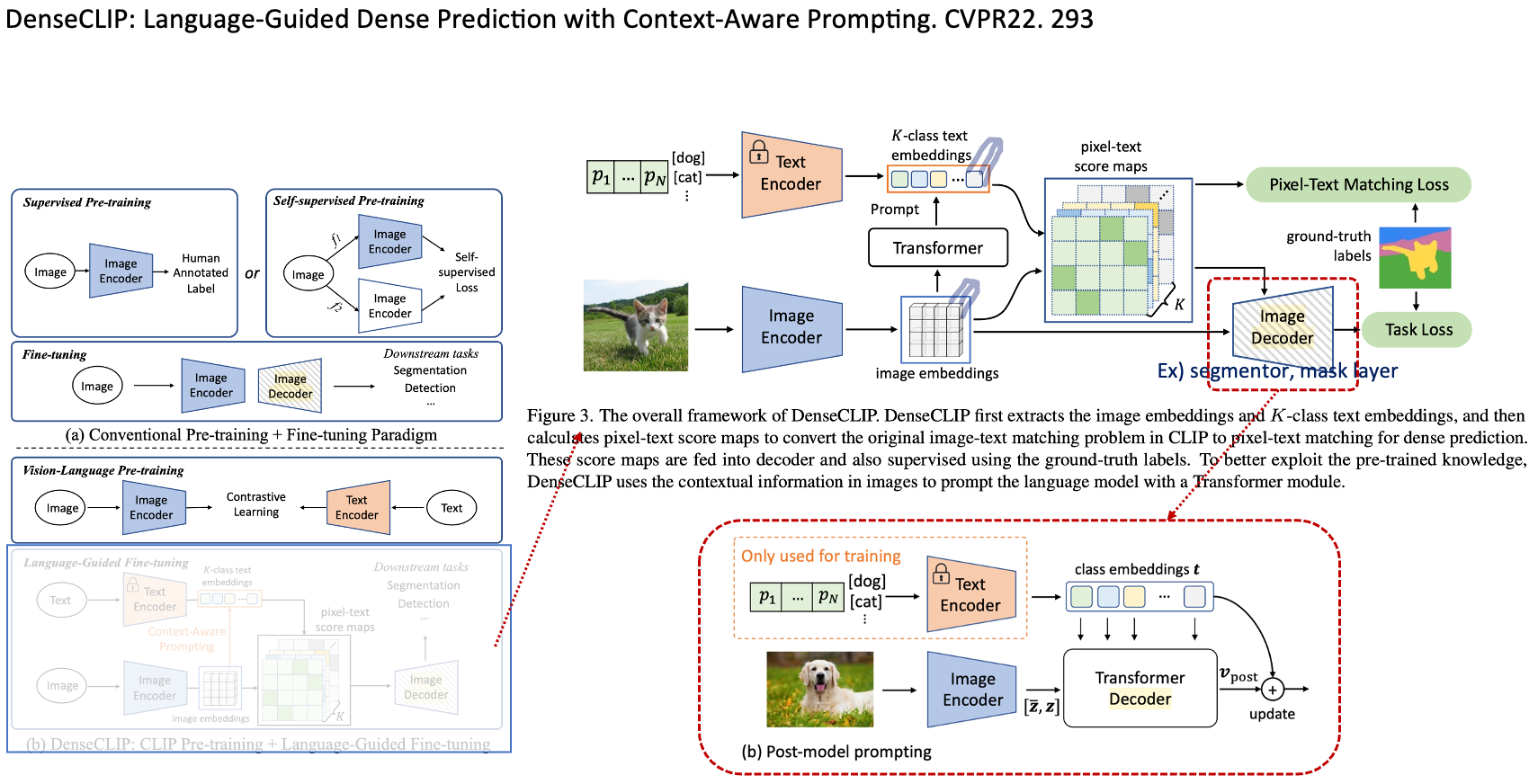
◽️ DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting. CVPR22. 293
- Segmentation labels 사용 / CLIP frozen text encoder 사용 (따라서 open-vocabulary 능력을 갖출까?)
- Approach는 위 Lseg와 거의 동일하다.
◽️ MaskCLIP: Extract Free Dense Labels from CLIP. MMLab, ECCV22. 234
- Introduction이 아주 마음에 든다. / 여기서 Mask는 segmentation을 의미한다. / 하지만, Table 1의 성능이 너무 엄청 낮은건가? Cityscape 같은 데이터셋과 비교하면 많이 낮은 것 같은데, COCO-stuff에서 저정도 mIoU는 어느정도 능력인지 감이 안온다.
- We find that Naive 하게, DeepLab encoder를 CLIP weight로 가져와 모델을 학습시키면 성능이 안나오더라.
- MaskCLIP: CLIP text encoder에서 나오는 vectors를 classifier weights로 사용한다. 그렇게 classify한 segment map을 사용한다.
- MaskCLIP+: 위 결과를 Pseudo label로 사용 + GT segmentation labels(PASCAL, COCO stuff) + DeepLapv2 모델을 학습시킨다.
- Leg, DenseCLIP에서는 text encoder만 freeze 해서 모델을 학습했다. 하지만 이 논문에서는 text, image encoder를 모데 freeze한다. Simplification 을 생각한다면, 위 2 논문이 우위에 있는 듯 하다.

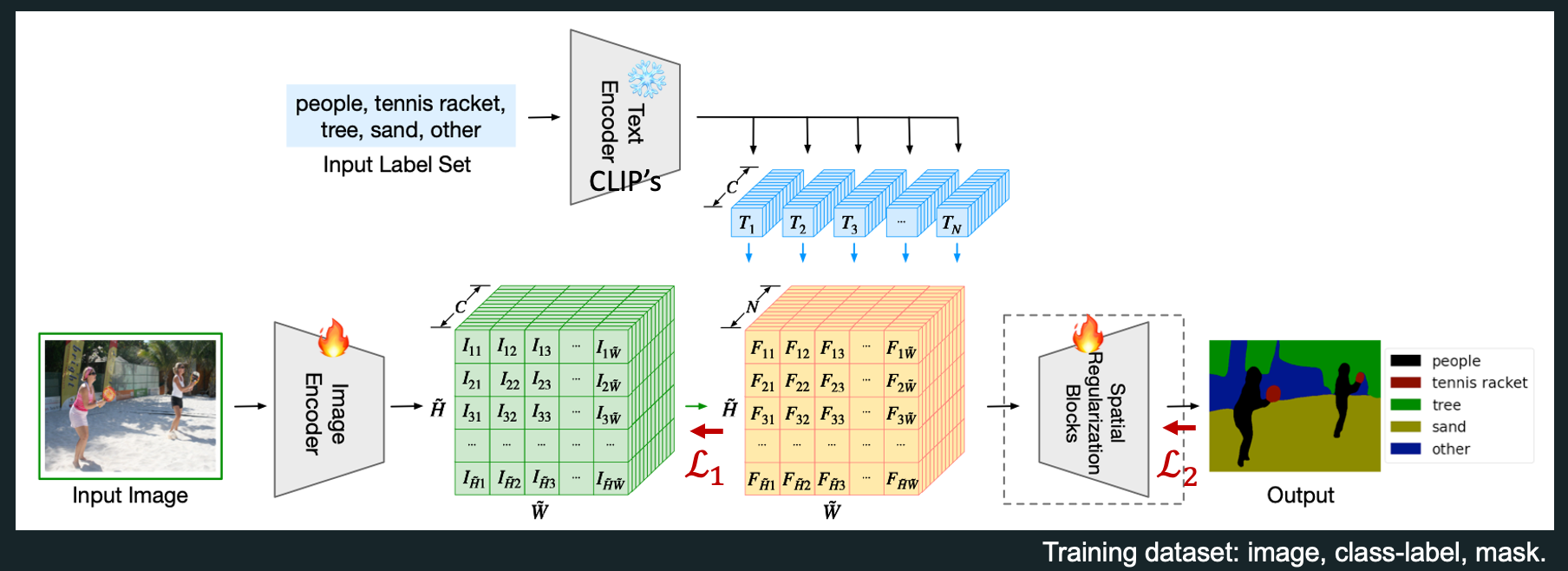
◽️ OpenSeg: Scaling Open-Vocabulary Image Segmentation with Image-Level Labels. Google, ECCV22. 207
- Lseg를 improve(scaling up)한 논문이다. / Grouping을 위한 group query 개념을 사용했다. 이는 GroupViT와 비슷한 것 같다.
- Weakness of Lseg: It requires pixel-wise annotations and thus is a limitation to generalization to unseen visual concepts.
- So, OpenSeg implements a class-agnostic segmentation model and train it with class-agnostic segmentation masks (ex, masks without class labels)

◽️ 🔒Open-Vocabulary Universal Image Segmentation with MaskCLIP. ICML23. 12
◽️ 🔒RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection. NeurIPS22. 24
◽️ 🔒Learning Customized Visual Models with Retrieval-Augmented Knowledge. CVPR23. 5
◽️ 🔒UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces
1.4 Promptable Models (2 papers)
◽️ Segment Anything. Meta, 2023.
- Meta Research team proposed SAM and believe it to be a foundation model for image segmentation (like GPT and CLIP).
- SAM has attracted attention for several reasons: 1) SAM follows NLP to pursue a path that combines the foundation model with prompt engineering. 2) It performs label-free segmentation. 3) SAM is easy to be compatible with other applications.
◽️ 🔒Semantic-SAM: Segment and Recognize Anything at Any Granularity
1.5 Parameter-Efficient Fine-Tuning (6 papers)
◽️ 🔒VL-PET Vision-and-Language Parameter-Efficient Tuning via Granularity Control. ICCV, 2023.
◽️ 🔒Adapter is All You Need for Tuning Visual Tasks. Alibaba, summited to CVPR, 2024.
◽️ 🔒PLOT: Prompt Learning with Optimal Transport for Vision-Language Models. ICLR, 2023.
◽️ 🔒LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
◽️ 🔒Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
◽️ 🔒Side Adapter Network for Open-Vocabulary Semantic Segmentation
2. Text-output (7 papers)
◽️ A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions Meta 2023
- 요약: 데이터셋 만듬. 이거로 새로운 Matching task에서 좋은 성능 얻음. 이것이 CLIP-finetuning 성능도 좋았음.
- Intro: CLIP을 발전시키기 위해서 text-image pairs를 깔끔하게 다듬거나, Negative pairs를 사용하는 방법들이 있었다. 이것과는 다르게, 좀더 길고 신뢰할만한 1) 데이터를 만들어서 2) 모델을 추가 학습했고 3) sub-parts - text matching이라는 세로운 테스크에서 좋은 성능을 얻었다.
- Dataset 제작법: SAM써서 sub-mask들을 만들어가고, 그것들에 대한 human-annotation을 만들어냈다.
- Subcrop-caption matching task: sub-mask 영역들과 sub-captions들을 매칭시키는 Task를 의미하는 듯 하다.
- 코드를 통해서 어떤 hyper-para로 fine-tune했는지 알수 있다면 좋을 듯 하다.

◽️ POPE Evaluating Object Hallucination in Large Vision-Language Models EMNLP 2023
- What is Object hallucination: Large vision langage model (LVLM, ex, LLaVA, InstructBLIP) 등이 captioning을 수행할 때, 이미지에 있지도 않은 Object를 이야기하는 것
- SEEM을 사용해서 detection을 수행 → LVLM의 Image captioning 내용이 아닌다, 질문을 통한 이해 능력 평가.

◽️ Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
- 기본 MAE, ResNet 같은 논문과는 다른 Structure. 내가 하고 싶은 이야기를 하는 것 마음에 든다. 역시 Saining.
- Motive1: CLIP image encoder는 이미지 이해하는 능력 구리다. CLIP으로 뽑은 image feature에는 이미지 전체를 이해한 정보가 없다. 예를 들어, 나비 다리가 있는지, 차의 문이 열려있는지 닫혀있는지, CLIP은 모른다. 그래서 CLIP사용하는 VLM 성능 또한 구리다.
- Section2: DINO가 CLIP보다 "서로 다른 이미지를 다른 이미지로 인지하는 능력" 이 더 좋다. 반대로, CLIP은 "문이 닫힌 차, 문이 열린 차 이미지를 거의 같은 feature space로 임베딩 한다" // DINOv2에서 0.6이하, CLIP에서 0.95이상 similarity를 가지는 pairs를 찾는다. → 150개의 pair에 human annotating + VQA 만들기 → SOTA MLLMs (multimodal LLM) 평가 → 결론: Current MLLMs struggle with visual details.
- Section3: GPT-4에게 MLLMs가 구별하기 힘들어하는 Visual pattern 찾기 → Visual pattern에 따른 CLIP-based 모델 평가해보기 평가방법 Figure5 결과Table1 → CLIP이 못하는것이 LLaVA, InstructBLIP도 잘 못하더라
- Section4: DINO랑 CLIP이랑 같이 써서 VML 돌려보자. 근데 그냥 Naive하게 돌리면 안된다. // 4.2 Additive MoF (Figure7 2번째), 성능 Table2: 위 평가에서는 성능 오르지만, LLaVA의 기본 성능은 떨어트린다. → Figure 7 3번째 과 같은 방식으로 visual token을 교차해서 넣어주면 성능 좋아진다.

◽️ 🔒X-GPT: Connecting generalist X-Decoder with GPT-3
◽️ 🔒BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
◽️ 🔒Flamingo: Multimodal In-Context-Learning
◽️ 🔒Mass-producing failures of multimodal systems with language models. In NeurIPS, 2023.
3. Image-Text-output
3.1 Unified Vision-Langauge Models (8 papers)
◽️ 🔒Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks. Allen, ICLR, 2023. 192
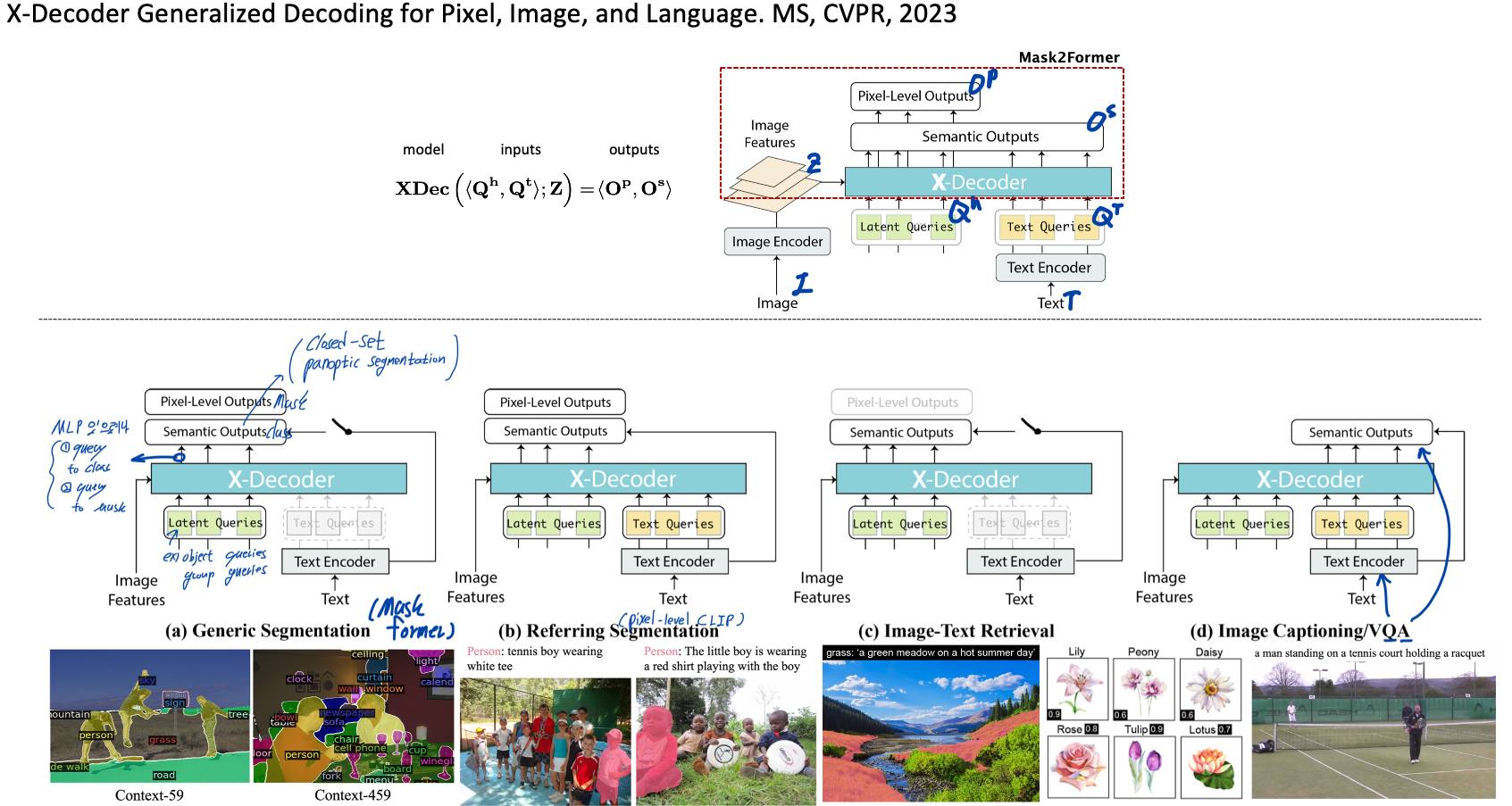
◽️ X-Decoder: Generalized Decoding for Pixel, Image, and Language. MS, CVPR, 2023. 89
- Motivation: Until recently, most of these tasks have been separately tackled with specialized model designs, preventing the synergy of tasks across different granularities from being exploited.
- Unifying = open-vocabulary segmentation (image output) + Image captioning, Image-text retrieval (text output)
- Pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs
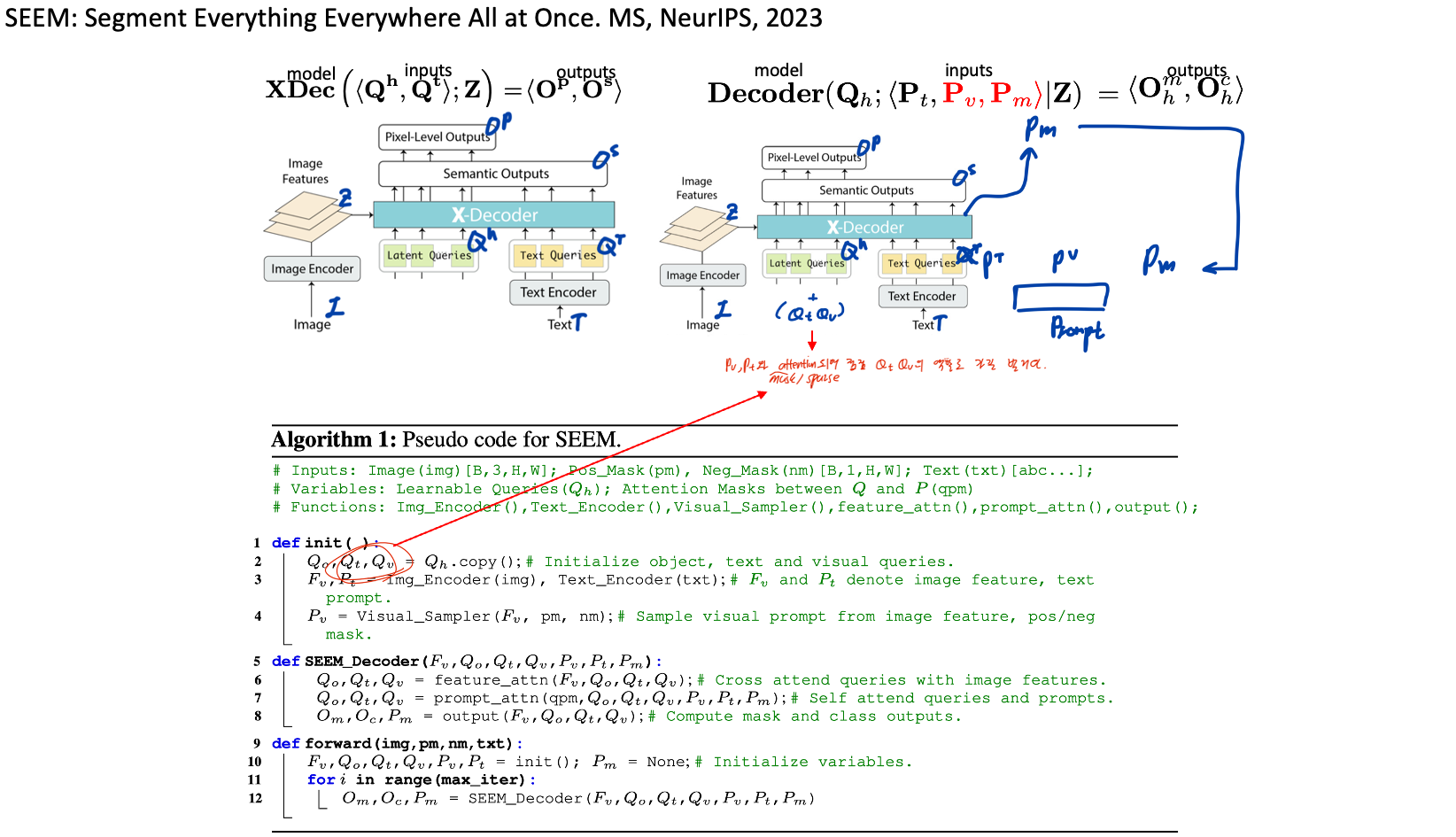
◽️ SEEM: Segment Everything Everywhere All at Once. MS, NeurIPS, 2023.
- Our model can deal with any combination of the input prompts, leading to strong compositionality. They train the model on three tasks: panoptic segmentation, referring segmentation, and interactive segmentation.
- Visual-semantic prompt: points, boxes, scribbles, masks + text (이리저리 섞어서도 가능하다. 예를들어 click + text 와 같이.)
◽️ 🔒FIND: Interface Foundation Models' Embeddings. MS, 2023.
◽️ 🔒Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks. CVPR, 2023. 27
- Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks, CVPR 2022. 77
- Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs, NeurIPS 2022. 26
◽️ 🔒Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
◽️ LISA: Reasoning Segmentation via Large Language Model. submitted to ICLR24.
- Presentation material:
Onedrive/Davian/Study/Generative/240320_CVwLLM.pptx - LLM의 Complex reasoning, world knowledge 능력을 바탕으로, Segmentaiton output을 만들겠다.
- Segmentation: ADE20K, COCO-Stuff, and LVIS-PACO //Referring segmentation dataset: refCOCO, refCOCO+, refCOCOg, and refCLEF // VQA dataset: the LLaVA-Instruct-150k data 을 사용.
- Objectives: 1) the auto-regressive cross-entropy loss for text generation 2) per-pixel binary cross-entropy (BCE) loss and DICE loss
- Weaknesses in Openreview:
- LLMs, MLLMs를 사용해서 reasoning 및 world knowledge를 사용한 것. 기존 SEEM 같은 논문은 LLM을 사용한게 아니므로 fair comparison아님.
- The token "SEG" is only one token, so it can be used for multiple instance segmentation.
- The reasoning question can be recognized by foundation models.
- LLM에 LoRa를 했는데, Text-generation task에서 성능 절감 없는지 증명 없음. (Output은 Image만 해야겠다..)
- Training LISA-7B requires only 10,000 training steps on 8 NVIDIA 24G 3090 GPUs.

◽️ GLaMM: Pixel Grounding Large Multimodal Model. arXiv. 2024.
- 기존 LLM 논문들은 1) 오직 text output만을 내놓거나, 2) grounding (text-based masking) 이 안되거나 3) single object만 grounding 가능하던지 (LISA) 4) Conversation은 불가능한다던지 의 한계점을 가졌다. 더 practical한 기술로 GroundingLMM (GLaMM)을 제안한다.
- 이런 모델이 수행할 수 있는 Task는 Grounded converstaion generation이다. 이는 Figure1을 통해 확인 가능하다.
- 위 Task를 위한 데이터셋을 소개한다. 1) automated pipeline으로 생성된 Grounding-anything dataset, 2) 기존 CV dataset을 conversation화 시킨 데이터셋
- 방법론은 Figure2와 같다. 방법론의 디테일과 데이터셋의 구체적이 내용은 필요할 때 논문 전체를 통해 확인해본다.
- 전체 pretraining과 finetuning을 위해서 8 NVIDIA A100-40GB GPUs가 사용됐다고 한다.
◽️ 🔒PSALM: Pixelwise SegmentAtion with Large Multi-Modal Model
◽️ 🔒Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want